IDA Python 使用总结
环境配置
切换 python 版本
管理员权限运行 IDA 安装目录下的 idapyswitch.exe ,选择使用的 python 解释器。
安装 IPyIDA 插件
IPyIDA 是一个仅依赖 Python 的解决方案,用于将 IPython 控制台添加到 IDA Pro 中。通过使用 <Shift+>,你可以打开一个内嵌 Qt 控制台的窗口。这样你就可以享受到 IPython 的自动补全、在线帮助、等宽字体输入框、图表等功能。
IPyIDA 提供了一个安装脚本,可以自动从 IDA 控制台安装 IPyIDA 及其依赖项。只需将以下代码复制到 IDA 控制台中即可完成 IPyIDA 的安装:
python2:
1
import urllib2; exec urllib2.urlopen('https://github.com/eset/ipyida/raw/stable/install_from_ida.py').read()
python3:
1
import urllib.request; exec(urllib.request.urlopen('https://github.com/eset/ipyida/raw/stable/install_from_ida.py').read())
脚本将执行以下操作:
- 如果尚未安装
pip,将安装pip。 - 从 PyPi 安装
ipyida包。 - 将
ipyida_plugin_stub.py复制到用户的插件目录。 - 加载 IPyIDA 插件。
另外 IPyIDA 也可以手动安装,用户只需要将 ipyida_plugin_stub.py 和 ipyida 目录复制到 IDA 的插件目录中即可。
手动安装需要用户自己管理依赖项和更新。IPyIDA 需要 ipykernel 和 qtconsole 包,并且如果使用 ipykernel 版本 5 或更高版本,还需要 qasync 包。
1 | pip install ipykernel qtconsole |
pycharm 自动补全
在 PyCharm 的设置→项目→Python 解释器点击设置选择全部显示...
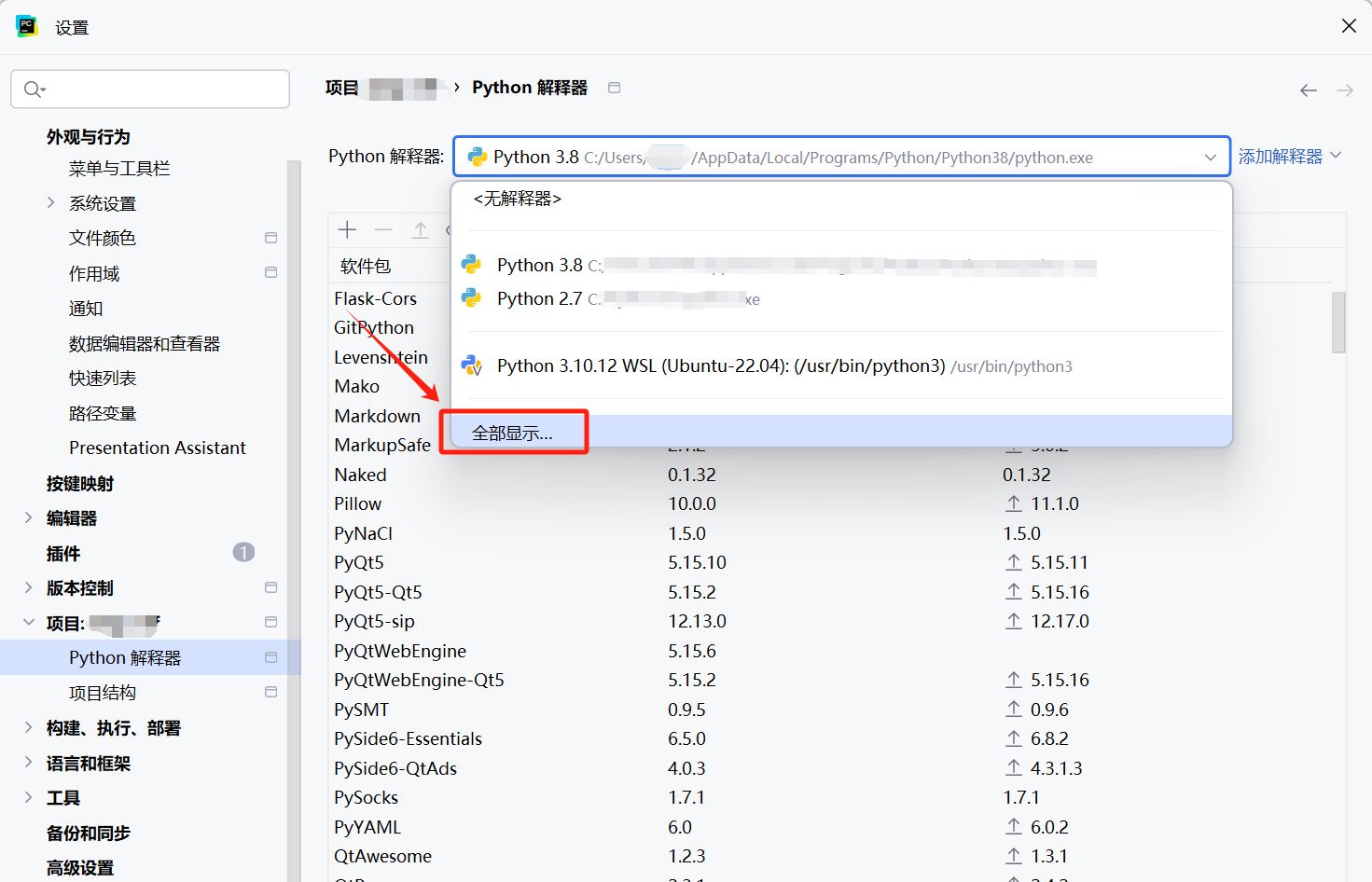
点击显示解释器路径图标,然后在弹出的解释器路径对话框中添加 IdaPython 的 python 库路径。
旧版本的 IDA 的 python 库有 3 和 2 的区分,分别表示 Python3 和 Python2 对应的 python 库。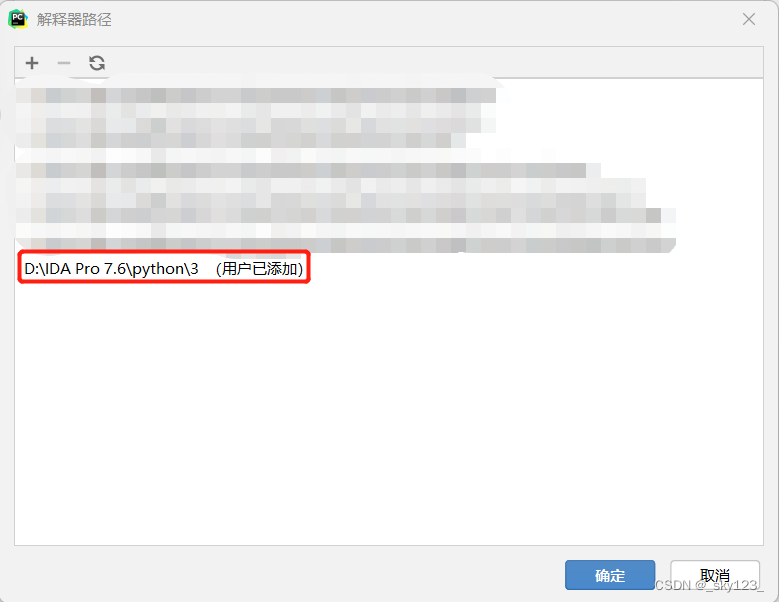
添加完 IdaPython 的代码库之后就可以使用 PyCharm 的自动补全功能了。
基本使用
段相关
idc.get_segm_name(addr):获取地址addr所在段的名字(参数为当前的地址)。idc.get_segm_start(addr):获取地址addr所在段的开始地址idc.get_segm_end(addr):获取地址addr所在段的结束地址idc.get_first_seg():获取第一个段的地址idc.get_next_seg(addr):获取地址大于addr的第一个段的起始地址idautil.Segments():返回一个列表记录所有段的地址
例如遍历所有的段:
1 | import idc |
地址相关
交叉引用
idautils.CodeRefsTo(ea, flow):获取引用ea地址处的代码的地址。- 参数:
ea:被引用的代码的地址flow:表示代码顺序执行的是否计算在内(布尔值,0/1 或 False/True),比如如果flow = True那么认为当前指令的上一条指令引用了当前指令。
- 返回值 :代码引用列表(可能是空列表)
- 参数:
idautils.CodeRefsFrom(ea, flow):ea地址处的代码引用了何处的代码。- 参数:
ea:查询的代码的地址flow:表示代码顺序执行的是否计算在内(布尔值,0/1 或 False/True),比如如果flow = True那么认为当前指令的下一条指令被当前指令引用。
- 返回值 :代码引用列表(可能是空列表)
- 参数:
idautils.DataRefsTo(ea):获取引用ea地址处的内容的地址。idautils.DataRefsFrom(ea):ea地址处的数据引用了何处的数据。
符号地址
idc.get_name_ea_simple(name):获取名称对应的地址,如果获取不到则返回ida_idaapi.BADADDR。获取符号在 got 表中的地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def get_got_addr(symbol):
# 获取符号的地址
symbol_addr = idc.get_name_ea_simple(symbol)
# 如果该地址不在 'extern' 段中,尝试获取对应的 __imp_ 符号地址
if idc.get_segm_name(symbol_addr) != 'extern':
symbol_addr = idc.get_name_ea_simple(f'__imp_{symbol}')
# 确保符号地址在 'extern' 段中
assert idc.get_segm_name(symbol_addr) == 'extern'
# 查找所有引用该符号地址的代码或数据引用
for ref_addr in (list(idautils.CodeRefsTo(symbol_addr, False)) + list(idautils.DataRefsTo(symbol_addr))):
# 如果引用地址位于 .got 或 .got.plt 段中,返回该引用地址
if idc.get_segm_name(ref_addr) in ['.got', '.got.plt']:
return ref_addr获取符号在 plt 表中的地址:
1
2
3
4
5
6def get_plt_addr(symbol):
# 获取符号的 GOT 地址
for ref_addr in (list(idautils.CodeRefsTo(get_got_addr(symbol), False)) + list(idautils.DataRefsTo(get_got_addr(symbol)))):
# 如果引用地址位于 .plt 或 .plt.got 段中,返回该函数的起始地址
if idc.get_segm_name(ref_addr) in ['.plt', '.plt.got']:
return idaapi.get_func(ref_addr).start_ea
数据相关
数据读写
ida_bytes.get_wide_byte(addr):以 1 字节为单位获取地址处的值。ida_bytes.patch_byte(addr, value):以 1 字节为单位修改地址处的值。ida_bytes.get_wide_word(addr):以 2 字节为的单位获取地址处的值。ida_bytes.patch_word(addr, value):以 2 字节为的单位修改地址处的值。ida_bytes.get_wide_dword(addr):以 4 字节的单位获取地址处的值。ida_bytes.patch_dword(addr, value):以 4 字节为的单位修改地址处的值。ida_bytes.get_qword(addr):以 8 字节的单位获取地址处的值。ida_bytes.patch_qword(addr, value):以 8 字节为的单位修改地址处的值。idc.get_bytes(addr, len):获取addr地址处len长度的数据。idc.patch_bytes(addr, data):在addr地址处写入data(bytes 类型数据)。
数据类型
idc.get_item_size(addr):获取addr地址处的数据大小,例如汇编指令长度。idc.del_items(addr):去除目标地址处数据的属性。idc.set_name(ea, name, flags=0): 为指定地址的对象设置或删除名称,并将名称添加到名称列表中。对象可以是任何类型(如指令、函数、数据字节、字符串、结构体等)。其中参数name如果是空字符串则表示删除名称。idc.create_insn(addr):将目标地址处的数据设置为代码。有可能会失败,可以与ida_name.set_name(addr, '')配合来避免失败。
数据查找
IdaPython 没有什么好用的数据查找的 API,因此通常搜索数据都是先将数据读出来然后手动搜索。
1 | import idaapi |
字符串相关
在 IdaPython 脚本中,字符串起到了非常关键的作用。例如通过字符串定位关键代码,或者通过字符串恢复函数符号等。因此这里单独介绍一下 IdaPython 中字符串相关的功能。
字符串提取
字符串获取主要有 idautils.Strings 和 idc.get_strlit_contents两种方式。
idautils.Strings
idautils.Strings() 是一个非常常用的 API,它会自动识别和遍历整个二进制文件中的所有字符串,得到一个 Strings 对象。
Strings 对象支持下标访问,得到的结果是一个 StringItem 对象,该对象有如下属性:
ea:字符串的地址。strtype:字符串类型,有下面几种常见类型:STRTYPE_TERMCHR:字符终止的字符串,字符串以特定字符结束。STRTYPE_C:C 风格字符串(零终止)。STRTYPE_C_16:16 位字符的 C 风格字符串(零终止)。STRTYPE_C_32:32 位字符的 C 风格字符串(零终止)。STRTYPE_PASCAL:Pascal 风格的字符串,带一个字节长度前缀。STRTYPE_PASCAL_16:Pascal 风格的 16 位字符字符串,带一个字节长度前缀。STRTYPE_LEN2:Pascal 风格的字符串,带两个字节的长度前缀。STRTYPE_LEN2_16:Pascal 风格的 16 位字符字符串,带两个字节的长度前缀。STRTYPE_LEN4:Pascal 风格的字符串,带四个字节的长度前缀。STRTYPE_LEN4_16:Pascal 风格的 16 位字符字符串,带四个字节的长度前缀。
length:字符串长度。
另外我们可以通过 str() 将 StringItem 对象对象强制转换为字符串形式。
1 | import idautils |
idc.get_strlit_contents
idc.get_strlit_contents 主要用于从指定地址提取字符串:
1 | def get_strlit_contents(ea, length = -1, strtype = STRTYPE_C): |
- 参数:
ea:字符串起始地址。length:字符串长度。默认是 -1,此时 IDA 会计算最大字符串长度。strtype:字符串类型,使用STRTYPE_*常量。
- 返回值 :返回字符串内容。如果在指定的地址无法找到有效的字符串,或者字符串内容为空,则返回空字符串。
字符串查找
我们可以通过 idautils.Strings() 构建出程序的字符串表,之后就可以在这个表中查询字符串的地址。
1 | import idautils |
字符串创建
idc.create_strlit 可以在指定地址创建字符串(字符串类型由 get_inf_attr(INF_STRTYPE) 的值决定):
1 | def create_strlit(ea, endea): |
- 参数:
ea:字符串起始地址。endea:字符串的结束地址(不包括该地址)。如果endea == BADADDR则 IDA 会计算最大字符串长度。
- 返回值 :返回 1 表示成功,0 表示失败。
汇编指令相关
IdaPython 内置了汇编指令相关的 API,但是 IDA 的汇编与主流的汇编库 Keystone 和 Capstone 不通用,进而导致与主流的二进制相关库不兼容。
因此我们通常只是使用 IdaPython 的部分汇编指令功能(主要是获取指令地址和长度),而实际的汇编和反汇编操作主要还是通过 keystone 和 Capstone 实现。
idc.GetDisasm(addr)或idc.generate_disasm_line(addr,flags):获取地址处的汇编语句,这里flags通常为 0 。idc.print_operand(addr,index):获取指定地址addr的汇编指令的第index个操作数(字符串形式),如果index索引超过操作数的个数则返回空字符串。下面简单举几个例子感受一下:汇编 inxex = 0 index = 1 pop raxrax‘’ mov [rsp+10h], rax[rsp+10h]raxcall $+5$+5‘’ add rax, 68FBhrax68FBhjz short loc_1400100CCloc_1400100CC‘’ popfq‘’ ‘’ retn‘’ ‘’ idc.get_operand_type(addr, index):获取操作数的类型。o_void (0):无效操作数,表示没有操作数。o_reg (1):寄存器操作数,表示一个寄存器。o_mem (2):内存操作数,表示一个内存地址。o_phrase (3):短语操作数,表示根据寄存器和偏移量计算的内存地址。o_displ (4):带偏移量的内存操作数,表示根据寄存器、偏移量和可选标志寄存器计算的内存地址。o_imm (5):立即数操作数,表示一个立即数值。o_far (6):远跳转操作数,表示一个远跳转地址。o_near (7):相对跳转操作数,表示一个相对于当前指令地址的跳转地址。
idc.get_operand_value(addr, index):获取指定索引操作数中的值。- 对于寄存器操作数 (
o_reg),返回寄存器的编号。 - 对于内存操作数 (
o_mem),返回内存地址的值。 - 对于立即数操作数 (
o_imm),返回立即数的值。 - 对于相对跳转操作数 (
o_near),返回跳转的地址。 - 对于其他特定于处理器的操作数类型,返回相应的值,具体含义需要参考相关文档。
- 对于寄存器操作数 (
idc.print_insn_mnem(addr):获取指定地址addr的汇编指令的操作指令(如mov、add)。idc.next_head(addr):获取当前地址的汇编的下一条汇编的地址。idc.prev_head(addr):获取当前地址的汇编的上一条汇编的地址。
1 | import idc |
函数相关
ida_funcs.FuncItems(start):FuncItems函数接收一个函数起始地址,并返回一个迭代器,允许你遍历并打印函数内部的每条汇编的地址。idautils.Functions(startaddr,endaddr):获取指定地址之间的所有函数idc.get_func_name(addr):获取指定地址所在函数的函数名get_func_cmt(addr, repeatable):获取函数的注释repeatable:0 是获取常规注释,1 是获取重复注释。
idc.set_func_cmt(ea, cmt, repeatable):设置函数注释idc.find_func_end(ea):寻找函数结尾,如果函数存在则返回结尾地址,否则返回BADADDR。ida_funcs.set_func_end(addr, newend):设置函数结尾为newendida_funcs.set_func_start(addr, newstart):设置函数开头为newstartida_funcs.get_func(addr).start_ea:获取addr所在函数的地址idc.get_prev_func(addr):获取addr所在函数的前一个函数的地址idc.get_next_func(addr):获取addr所在函数的后一个函数的地址ida_funcs.add_func(addr):在addr地址创建函数idaapi.FlowChart(func):接受一个函数对象,返回这个函数所有的代码块。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def get_basic_block(address):
for block in idaapi.FlowChart(idaapi.get_func(address)):
if block.start_ea <= address < block.end_ea:
return block
return None
def prev_call(addr):
addr = idc.prev_head(addr)
block = get_basic_block(addr)
while addr >= block.start_ea:
if arch_ctx.is_call(next(arch_ctx.cs.disasm(ida_bytes.get_bytes(addr, idc.get_item_size(addr)), addr))):
return addr
addr = idc.prev_head(addr)
return block.start_ea
def next_call(addr):
addr = idc.next_head(addr)
block = get_basic_block(addr)
while addr < block.end_ea:
if arch_ctx.is_call(next(arch_ctx.cs.disasm(ida_bytes.get_bytes(addr, idc.get_item_size(addr)), addr))):
return addr
addr = idc.next_head(addr)
return block.end_ea
去混淆
基础理论
程序的结构
我们可以认为一个程序的代码结构如下图所示: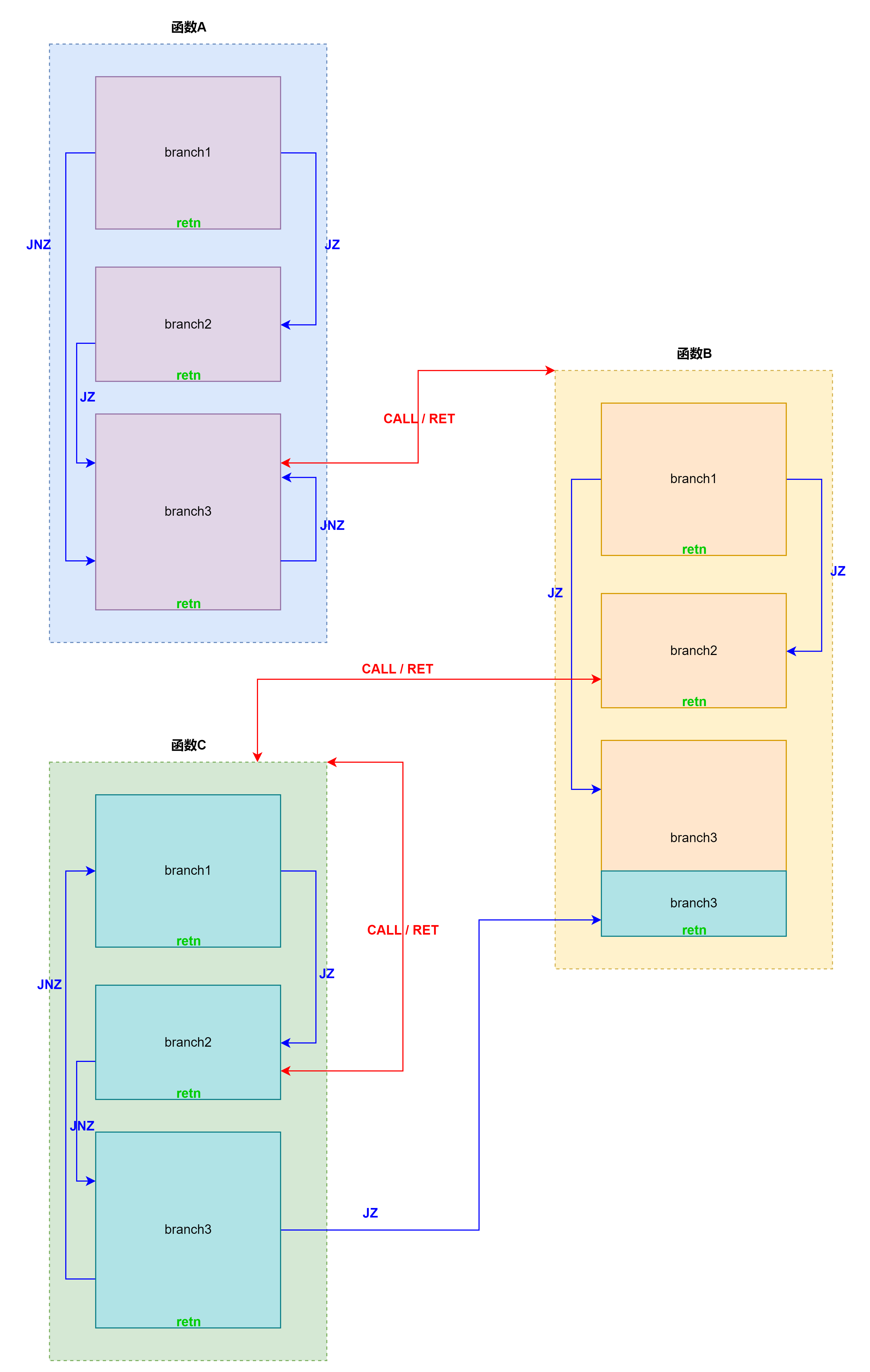
一个程序由多个函数(function)组成,而每个函数由多个分支(branch)组成,对于函数和分支我们做如下定义:
- 函数:从 CALL 指令跳转到的代码开始,在不通过 CALL 指令跳转的前提下能访问到的所有代码。
- 分支:通过 JCC 跳转到的代码开始,直到以 RET 结尾或者跳转到已分析过的分支的代码块。
因此去混淆的时候我们可以有如下代码框架,即先 bfs 函数,然后在每个函数内部再 bfs 所有分支。在 bfs 的过程中将已去混淆的代码拼接起来。这样做的好处是同一个函数的代码尽可能放在一起,ida 在反编译的时候容易识别。
1 | func_queue = Queue() |
代码重定位
代码的位置移动时,原本的 CALL 和 JCC 等跳转指令要想跳转到原来的地方需要进行指令修正,这个可以借助 keystone-engine 和 capstone 来完成。
1 | def mov_code(ea, new_code_ea): |
然而在完成去混淆后程序中的绝大多数代码都移动了位置,因此程序中所有的 CALL 和 JCC 等跳转指令跳转的地址需要进行修正,也就是重定位。
对于指令修正我们可以通过并查集来维护。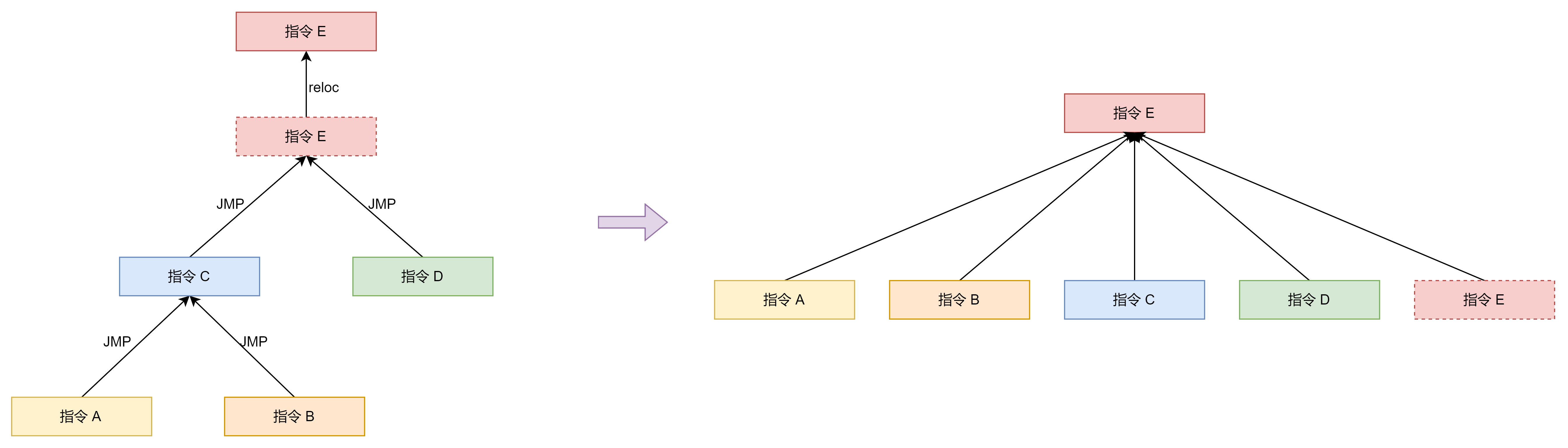
一个程序的跳转指令可以看做是上图左边的结构。即存在一个跳转指令跳转到另一个跳转指令的情况。通过并查集我们可以将指令 A,B,C,D,E 的真实地址都修正为指令 E 的真实地址。
在使用并查集维护重定位的时候需要注意以下几点:
- 上图中的指令 E 需要确保不存在指令复用的情况。因为有的代码混淆会将程序拆分成指令后放到一个巨大的 switch 中,然后通过在 switch 中查找依次执行指令。这种情况会造成一条指令在不同的分支中都会使用,如果此时我们用并查集维护就会把该指令重定位到其中一个使用该指令的地址,但实际上该指令还会在其他地址出现,这就造成了程序可能会跳转到错误的分支上。对于这种情况我们需要重定位查找 switch 的代码到去混淆的代码上,而不是重定位 switch 中的具体指令,这样就保证一一对应了。
- 在上图的结构中我们可以发现,只有连接根节点的边是重定位的边,其余的边都是跳转的边。因为在跳转的时候我们不需要关心中间的跳转指令在哪里,而是需要关心最终跳转到的位置的真实地址。因此在并查集合并的时候如果是一条 JMP 指令就需要将该指令的重定位后的实际地址合并到指令的原本地址,然后将指令的原本地址合并到指令的跳转地址,否则将该指令的原本地址合并到指令的重定位后的实际地址。这样在并查集路径压缩之后每一个跳转指令跳转地址都被重定位到非 JMP 指令的实际地址。
例题:强网杯2022 find_basic
观察发现程序由下面的代码块构成:
1 | .text:000048F4 pushf |
分析该代码块的执行过程,发现本质是在一个 switch 中查找实际指令。该代码块可由 lea ecx, [esp+4] 指令代替。
首先,我们需要将程序中的代码块提取出来,然后记录几个有用的信息:
start_ea:代码块的起始地址end_ea:代码块的结束地址imm:在 switch 中查找指令用的立即数reg:存放立即数用的寄存器call_target:调用的 switch 函数
在提取代码块的有效信息的同时也可以检测该代码块是否有效,因此分析发现程序中会在代码块直接插入一些有实际功能的代码。
1 | class Block: |
在提取出代码块之后利用提取到的有效信息可以在 call_target 中查找代码块对应的实际代码。这里有几个特殊情况:
一般情况在 cmp 判断找到对应位置后会依次执行 jnz,popa,popf 三条指令,然后后面紧跟着代码块对应的实际代码。然而想下面这种情况,在执行完 popf 后面紧跟着 pusha 而不是代码块对应的实际代码,简单分析一下发现这种情况代码块对应的实际代码为 retn 。这种情况需要返回 True 表示一个 branch 的结束。
1
2
3
4
5
6
7
8
9.text:000045CC popa
.text:000045CD popf
.text:000045CE pushf
.text:000045CF pusha
.text:000045D0 call dec_index
.text:000045D0
.text:000045D5 popa
.text:000045D6 popf
.text:000045D7 retn通常认为代码块对应的实际代码的结束标志为一个 jmp 指令,但是有的地方在 jmp 之后还会执行几条有效指令,因此判断实际代码的结束标志应当是 pushf 。
1 | def get_real_code(block, new_code_ea): |
这里涉及到了维护重定位的并查集 RelocDSU ,对应代码如下。在 get 函数中如果遇到了 jmp 指令且操作数是立即数就路径压缩到跳转的地址,直到地址在 .got.plt 或者指令不是 jmp 指令。另外判断是否是已处理代码是根据地址对应的最终地址是否不在 .text 段。
1 | class RelocDSU: |
接下来就是考虑如何提取出一个 branch 的代码了。前面提到过程序中会在代码块直接插入一些有实际功能的代码,因此需要借助 try:...except:... 和 assert 来处理。除此之外这里还有几个特殊情况:
- 程序中的 0x900 和 0x435c 处分别有一个获取返回地址 eip 到 ebx 和 eax 的函数,程序借助这两个函数来访问全局变量实现地址无关代码,然而重定位后代码地址改变,因此这里需要将其修正为
mov reg, xxx。 - 需要根据程序中的 jmp 指令来决定下一步需要去混淆的代码位置,这里需要判断 jmp 后面跟的是否是立即数,另外需要判断 jmp 到的代码是否是已经处理过的代码。
- 并查集合并的时候如果是代码块,需要将代码块的地址合并到代码块对应指令的实际重定位后的地址;如果不是代码块如果是 jmp 指令且操作数是立即数,需要将 jmp 指令和该指令的重定位后的实际地址合并到指令的原本地址,然后将指令的原本地址合并到指令的跳转地址,否则将该指令的地址合并到重定位后的地址。
1 | def handle_one_branch(branch_address, new_code_ea): |
能够处理 branch 后,我们就可以 bfs 依次处理所有的 function 和 branch 了,这里还有几个特殊情况:
- 0x4148 地址处的函数中有一个 switch ,由于是通过跳转表跳转,去混淆脚本分析不到跳转的分支,因此需要读取跳转表找到跳转的 branch 然后添加到
branch_queue中。 - 寻找新的 branch 时需要判断 jcc 的操作数类型是否是立即数。
1 | func_queue = Queue() |
在完成代码去混淆之后需要对代码进行重定位,重定位的时候需要注意 jmp 指令长度的变化。
1 | ea = new_code_start |
最后去混淆后的 switch 不能被 ida 正常识别出来,具体原因是前面获取返回地址 eip 的函数被 patch 成了 mov reg, xxx 指令,导致其与编译器默认编译出的汇编不同(程序开启了 PIE,直接访问跳转表的地址 ida 不能正确识别),因此需要将这里的代码重新 patch 回去。
同时为了不影响原本程序中的数据,这里我将修复的跳转表放到了其他位置。另外还有两个字符串全局变量也移动到了正确位置。
1 | new_jmp_table = (0xA6000 - 0x2D54, 0xA6000) |
最终去混淆脚本如下:
1 | from queue import * |
例题:SUSCTF2022 tttree
首先将 0x140010074 ,0x140017EFA ,140018C67 起始处的数据转换为汇编。
观察汇编,发现很多代码块之间相互跳转,因此先按照 retn 划分代码块。通过对代码块的观察,发现这些代码块按照 call $+5;pop rax(即 E8 00 00 00 00 58 ) 的出现次数可以分为三种:
出现 0 次:
 本质上是 `其它操作` + `retn` 。
本质上是 `其它操作` + `retn` 。
出现 1 次:
这种代码块本质为其它操作+jmp target,注意其它操作中可能包含 branch 。出现 2 次:
这个可以看做 2 个出现 1 次的代码块两个拼在一起,其中前面一个代码块去掉
retn。执行完前面一个代码块后由于没有retn,因此target1留在栈中。执行第 2 个代码块跳转到target2执行 ,在target2代码块返回时会返回到target1。因此这种代码块本质上相当于其它操作+call target2且下一个要执行的代码块为target1。
 本质上是 `其它操作` + `retn` 。
本质上是 `其它操作` + `retn` 。

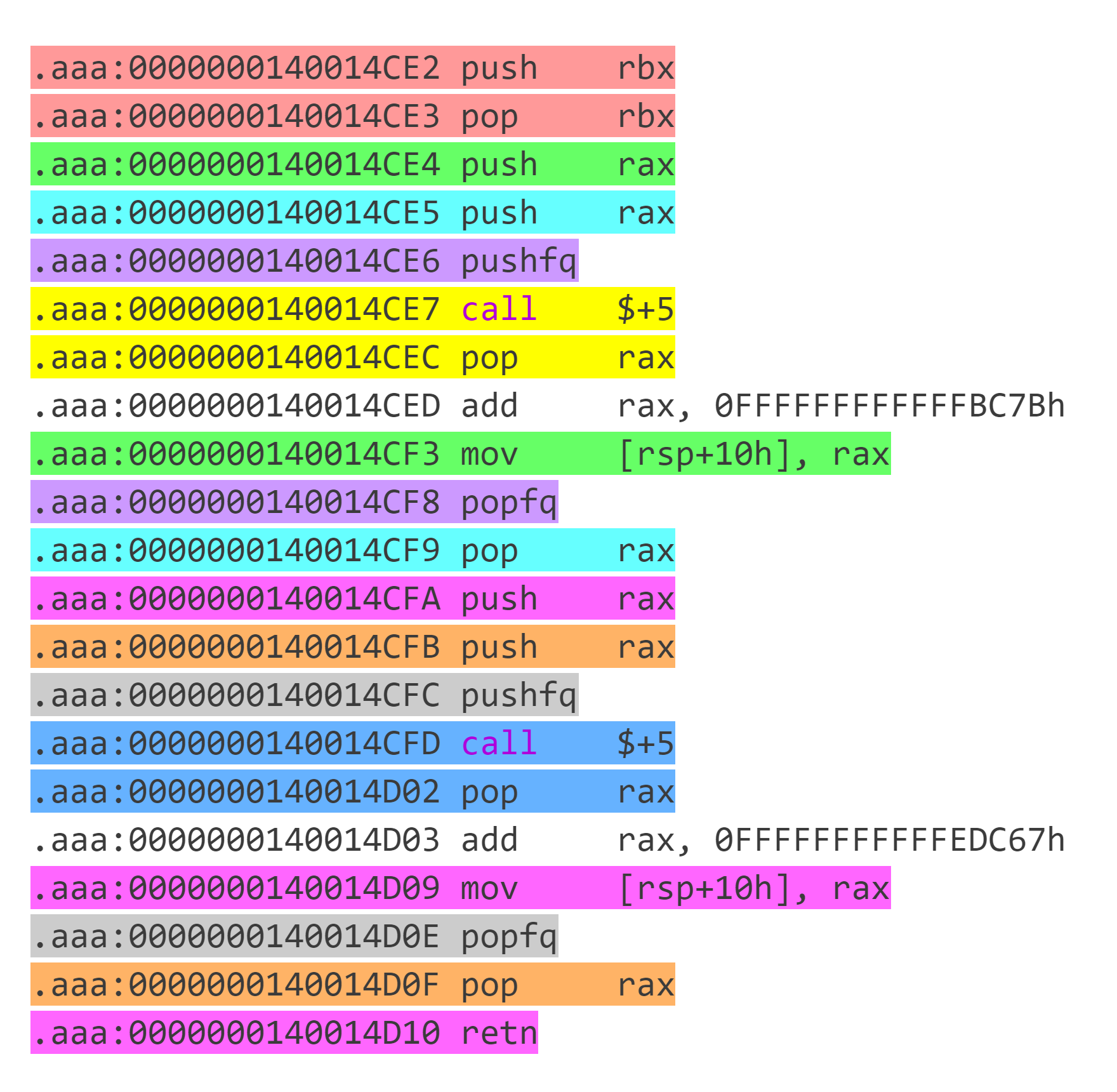
我们定义代码块 Block 几个关键信息:
start_addr:代码块的起始地址。asm_list:代码块的有效汇编,由于汇编指令可能包含[rip + xxx],因此需要记录汇编指令的地址以便后续修正。direct_next:执行完此代码块后接下来要执行的代码块地址。branch_list:代码块中的所有条件跳转语句跳到的地址。call_target:代码块调用函数地址。
1 | class Block: |
get_block 函数可以获取给定地址处的代码块并提取相关信息。代码块中可能有 push xxx;pop xxx; 这样的无意义指令,可以通过栈模拟来去除。
1 | def get_block(start_ea): |
能够获取代码块信息之后就可以 bfs 函数以及函数中的所有分支,提取出汇编代码并写入 newcode 段。这里需要注意以下几点:
- 涉及 rip 的汇编指令不能只是简单把指令中的
rip替换为对应的具体数值,因为有的指令立即数的长度被限制在 4 字节,直接替换成数值会溢出。一个比较好的解决方法是将rip替换为rip + (指令原本地址 - 指令当前地址)。这样借助 rip 寄存器扩大访问范围并且代码移动的距离不会超过 0x100000000 因此可以保证正确性。 - 如果
block.direct_next对应的代码已经被去混淆了需要加上一条 jmp 指令跳转到已经去混淆的代码。 - 有的汇编指令 keystone 不支持汇编,比如
bnd ret,需要特判。
1 | while not func_queue.empty(): |
最后对代码进行重定位,需要注意的是代码块中的有效指令中也可能有 call 指令,这里 call 调用的是一个类似 plt 表的结构,会直接跳转到导入表中的函数地址表指向的函数,需要特判这种情况。
1 | ea = new_code_start |
最后完整代码:
1 | from queue import * |
去花指令
花指令目前没有太好的去除办法,但是同一题目中花指令种类和变化都是有限的,也就是说我们可以将题目中所有花指令的类型总结出来,然后分别编写相应的查找和处理规则。
例题:看雪CTF2019 圆圈舞DancingCircle
用IDA打开DancingCircle,按G输入 0x401f58 跳转至核心函数,发现有大量花指令。因此需要借助 ida python 脚本正则表达式匹配去除。
分析汇编代码,发现花指令有如下几类:
call 花指令
call + pop
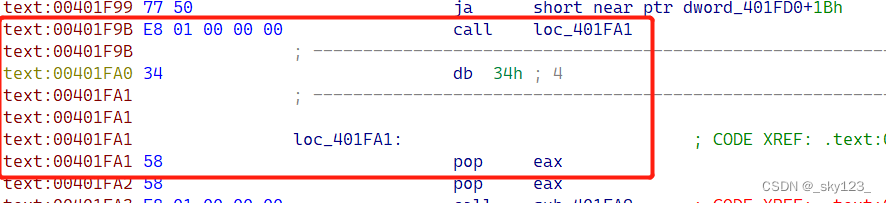
例如 0x00401F9B 处的花指令
另外还有 push eax + call + pop eax + pop eax 类型的。call + add esp, 4
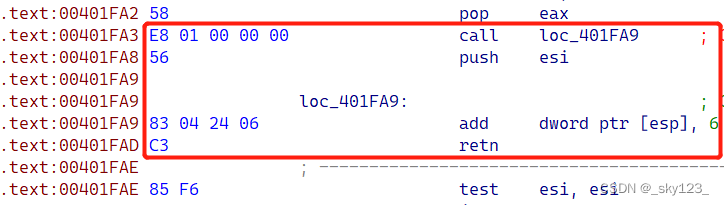
例如 0x00401F62 处的花指令call + add [esp], 6 + retn
例如 0x00401FA3 处的花指令

jx + jnx 花指令
例如 0x00402D67 处的花指令
这类花指令可以做如下检测:
- 两个跳转指令的第一个字节相差 1 且较小的那个是偶数。
- 前一个跳转的立即数比后一个多 2 。
fake jmp 花指令
例如 0x00401FB2 这处花指令:
这里有很多跳转,但分析后发现这些跳转都可以忽略。由于这一类花指令比较单一,因此直接匹配特征即可。
stx + jx 花指令
例如 0x0040261F 和 0x004026D7 两处花指令: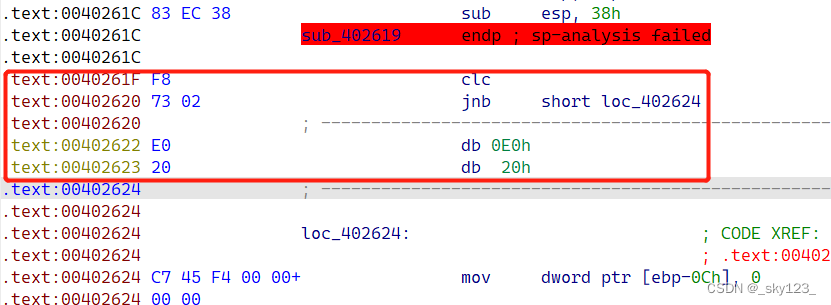
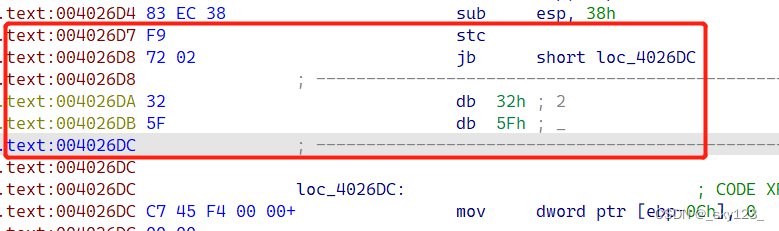
此类花指令本质是通过设置标志寄存器的值使得满足后面的条件跳转。由于此类指令较少,直接匹配特征即可。
1 | import regex as re |
常用脚本
全局符号错误修复

1 | import idc |
1 | # -*- coding: utf-8 -*- |
修复结构体偏移识别
1 | # -*- coding: utf-8 -*- |
修复函数参数
1 |
|
- Title: IDA Python 使用总结
- Author: sky123
- Created at : 2024-11-11 12:51:12
- Updated at : 2026-02-02 22:28:21
- Link: https://skyi23.github.io/2024/11/11/IDA Python 使用总结/
- License: This work is licensed under CC BY-NC-SA 4.0.