linux user pwn 基础知识
环境搭建
虚拟机安装
- 镜像下载网站
- 为了避免环境问题建议 22.04 ,20.04,18.04,16.04 等常见版本 ubuntu 虚拟机环境各准备一份。注意定期更新快照以防意外。
- 虚拟机建议硬盘 256 G 以上,内存也尽量大一些。硬盘大小只是上界,256 G 不是真就占了 256 G,而后期如果硬盘空间不足会很麻烦。
- 更换 ubuntu 镜像源 ,建议先在
系统设置 → Software & Updates → Download from → 选择国内服务器例如阿里云(貌似不这样后续换源会出错),然后再sudo gedit /etc/apt/sources.list将镜像源中不高于当前系统版本的镜像复制进去(高于当前系统版本容易把apt搞坏)。 - Ubuntu 换源 error:The following signatures couldn’t be verified because the public key is not available 解决方法:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 5523BAEEB01FA116其中的5523BAEEB01FA116是根据错误提示写的。
基础工具
net-tools
ifconfig 查看网络配置需要安装 net-tools 。
1 | sudo apt install net-tools |
vim
1 | sudo apt install vim |
gedit
不习惯 vim 的可以使用 gedit 文本编辑器。
1 | sudo apt install gedit |
git
1 | sudo apt install git |
gcc
1 | sudo apt install gcc |
python
ipython 提供了很好的 python 交互命令行,建议安装。
1 | sudo apt install python2 |
另外有的版本 ubuntu 的不好安装 pip2 可以使用 get-pip.py 脚本安装。
1 | sudo apt install python3-pip |
ubuntu 22.04 的 ipython(python2)必须使用 pip2 安装:
1 | sudo pip2 install ipython |
docker
1 | sudo apt install docker.io |
默认情况下,Docker 命令需要使用 sudo 权限才能运行,这是因为 Docker 守护进程以 root 用户身份运行。然而,你可以通过以下步骤将当前用户添加到 Docker 用户组,从而允许在不使用 sudo 的情况下运行 Docker 命令:
确保当前用户属于
docker组:运行以下命令检查当前用户是否已添加到 docker 组:1
groups
在输出的组列表中查找
docker。如果没有找到docker组,请继续下一步。将当前用户添加到
docker组:运行以下命令将当前用户添加到docker组中(将<username>替换为你的用户名):1
sudo usermod -aG docker <username>
更新用户组更改:运行以下命令使用户组更改生效:
1
newgrp docker
重新登录或重启系统:要使用户组更改永久生效,你需要注销当前会话并重新登录,或者重启系统。
oh-my-zsh
安装 zsh
1 | sudo apt install zsh |
安装 oh-my-zsh
1 | sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" |
设置 zsh 为默认 shell(重启虚拟机后生效)
1 | chsh -s /bin/zsh |
安装 oh-my-zsh 插件 zsh-autosuggestions ,zsh-syntax-highlighting
1 | git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions |
编辑 ~/.zshrc 添加插件:
1 | plugins=( |
更新:
1 | omz update |
wsl
WSL (Windows Subsystem for Linux) 是微软为 Windows 用户提供的一种兼容层,允许用户在 Windows 操作系统上运行 Linux 环境(包括大部分命令行工具、应用程序和服务),而不需要安装虚拟机或双系统。简单来说,WSL 让你在 Windows 上运行 Linux 程序,就像它们是原生程序一样。
WSL 目前有 WSL1 和 WSL2 两个版本:
WSL1 :最初的版本,提供 Linux 环境,运行 Linux 程序,速度较快但功能较有限。
WSL2 :通过在 Windows 上虚拟化完整的 Linux 内核,提供更强大的功能和更高的兼容性,特别适合需要容器、Docker 或更复杂的 Linux 功能的开发工作。
由于 WSL2 和虚拟机的部分设置冲突,因此这里建议安装 WSL1。具体安装过程如下:
安装 WSL 1 或 WSL 2 : 你可以通过 PowerShell 运行以下命令来安装 WSL:
1
wsl --install
选择 Linux 发行版 : 安装后,你可以从 Microsoft Store 下载你喜欢的 Linux 发行版(如 Ubuntu、Debian 等)。我这里安装的是 Ubuntu 22.04。
启用 Windows 功能 :下载好 Linux 发行版后在应用商店选择打开该 Linux,此时会弹出系统安装的命令窗口。但正常情况下这一步会出现一些报错,你需要启用部分 Windows 功能来避免这些报错。
0x80370114 错误 :这个报错说明未启用“虚拟机平台 (Virtual Machine Platform)”或“Windows 子系统 for Linux”功能。你需要打开 PowerShell(以管理员身份运行),依次执行以下命令并重启电脑:
1
2dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart0x80370102 错误 :这个报错表示虚拟化功能未启用,或者 Windows 中的 虚拟机平台 (Virtual Machine Platform) 功能未启用。
如果是安装 WSL2 则需要打开 PowerShell(以管理员身份运行),然后执行以下命令开启 Hyper-V 功能并重启电脑。
1
dism.exe /online /enable-feature /featurename:Microsoft-Hyper-V-All /all /norestart
之后还要打开 任务管理器,切换到“性能”选项卡,选择“CPU”,查看右下角“虚拟化”是否显示为 已启用。如果未启用还要在重启的时候进 BIOS 开启 CPU 的虚拟化选项。
如果是安装 WSL1 则只需要将 WSL 的版本设置为 1 即可。
1
wsl --set-default-version 1
pwn 相关工具
clion
clion 是一款 C\C++ 的 IDE ,可以用来阅读 glibc 源码的工具,这款工具对宏展开,符号跳转,结构体大小以及成员偏移计算都有很好的支持。这款软件需要付费使用,不过可以某宝搞一个教育邮箱。
首先用打开 debug_glibc 解压后的 glibc 源码,这里有以下几点需要注意:
- 源码在对应版本的
source目录下。 - 最好不要使用解压到默认
\glibc路径下的源码,因为源码调试与行号绑定,阅读源码可能会修改到源码。 - 这里用
debug_glibc中的源码是因为这里的源码是编译过的,clion 分析代码需要编译的配置文件。
然后这里我们看到 Makefile 没有正确导入:
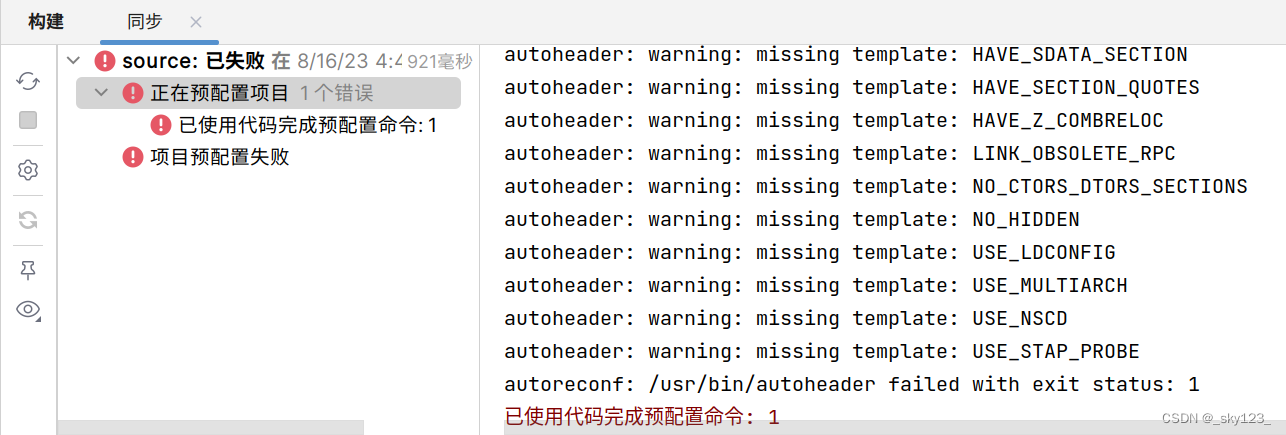
在较新版本的 clion 中位于 source 根目录下的 autoreconf 的配置文件 configure.ac 配置有问题,需要改成以下内容(这个主要看版本,有时默认的就好使):
1 | GLIBC_PROVIDES dnl See aclocal.m4 in the top level source directory. |
另外还需要右键 Makefile 设置在命令后面添加 --disable-sanity-checks 。另外构建目标要填 all ,否则 clion 分析的源码的不全。
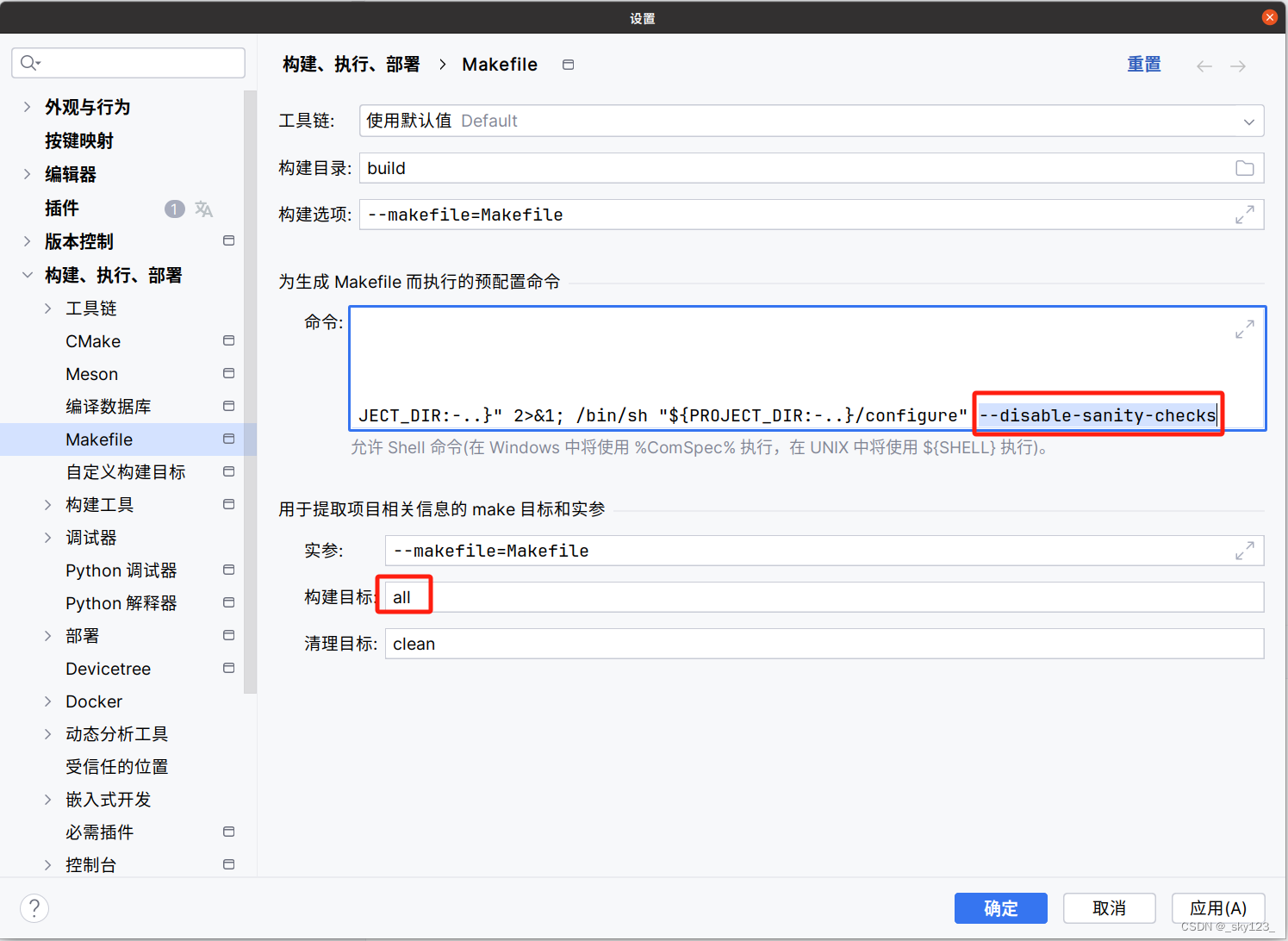
完整预配置命令如下:
1 |
|
之后右键重新加载 Makefile 项目。
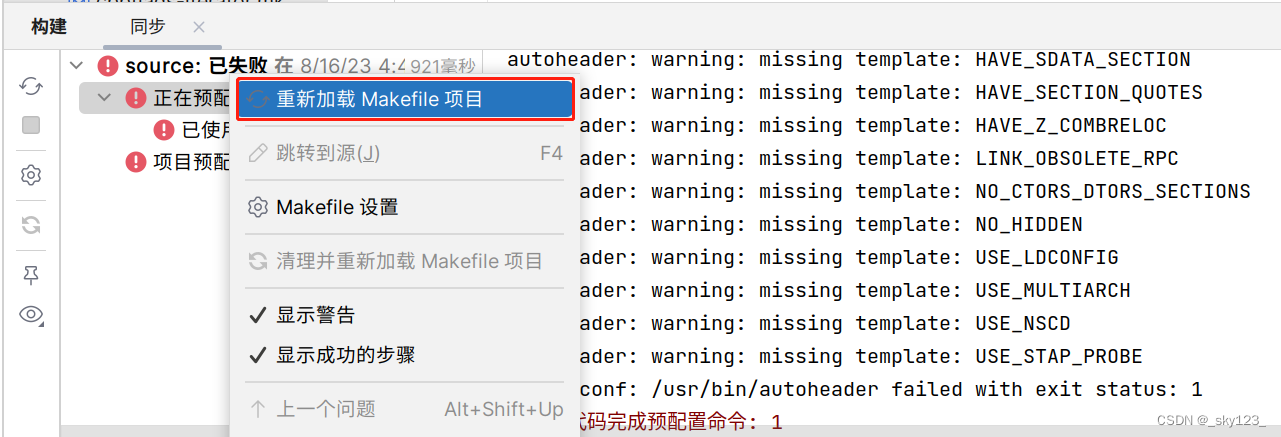
不勾选清理项目。
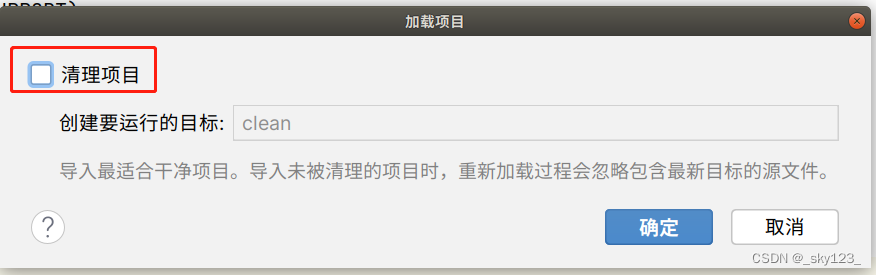
如果最后这样说明导入成功,之后耐心等待项目导入完毕即可。
gdb
1 | sudo apt-get install gdb gdb-multiarch |
主要有 pwndbg,peda,gef ,这里我常用的是 pwndbg 。对于一些版本过于古老导致环境装不上的可以尝试一下 peda 。
先将三个项目的代码都拉取下来。
1 | git clone https://github.com/longld/peda.git |
pwndbg 需要运行初始化脚本。
1 | cd pwndbg |
另外还有一个 pwngdb 插件在调试多线程堆(heapinfoall 命令)的时候很有用,建议安装。
1 | git clone https://github.com/scwuaptx/Pwngdb.git |
gdb 在启动的时候会读取当前用户的主目录的 .gdbinit 文件进行 gdb 插件的初始化,通常来说使用默认的配置即可:
1 | source /home/sky123/tools/pwndbg/gdbinit.py |
另外这里有一个 pwndbg 和 Pwngdb 共存配置方案,不过目前来看不推荐使用。
1 | source /home/sky123/tools/pwndbg/gdbinit.py |
注意
- 以普通用权限和管理员权限启动 gdb 时读取的
.gdbinit文件的路径是不同的,普通权限读取的是/home/<username>/.gdbinit而管理员权限读取的是/root/.gdbinit。 - 上述配置方案是为了使用
Pwngdb插件,而该插件唯一的作用就是打印每个线程的对应的tcache,而实际上这个库已经很久不维护了,因此建议还是直接source /home/sky123/tools/pwndbg/gdbinit.py。
pwndbg 安装 ghidra 插件可以支持代码反编译(虽然没啥用 )
安装
r2pipe库1
pip3 install r2pipe
下载安装 radere2 项目
1
2
3git clone https://github.com/radareorg/radare2.git
cd radare2
sudo sys/install.sh下载编译安装 r2ghidra 项目
1
2
3
4
5
6git clone https://github.com/radareorg/r2ghidra.git
cd r2ghidra
sudo ./preconfigure
sudo ./configure
sudo make -j16
sudo make install
pwntools
注意我这里的 pwntools 是 python2 版本的,需要指定为 4.9.0 ,因为高版本的 pwntools 已经不支持 python2 了(具体来说是高版本的 pwntools 必须依赖 unicorn 2.x.x ,而 unicorn 2.x.x 只支持 python3)。
1 | pip install pwntools==4.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple |
如果已经装了 pwntools 需要先卸载干净再重新安装,否则更改版本无效(最好不带 sudo 也来一遍确保卸载干净)。
1 | sudo pip2 uninstall pwntools |
这样安装的 pwntools 的 plt 功可能无法正常使用,需要手动安装 Unicorn 库。
1 | pip install unicorn==1.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple |
当然这样做的代价是一些特殊架构老版本的 pwntools 不支持,这时候最好换 python3 的 pwntools 。
gadget 搜索工具
ROPgdbget
安装:
1 | git clone https://github.com/JonathanSalwan/ROPgadget.git |
使用:
1 | ROPgadget --binary ntdll.dll > rop |
有时候 ROPgadget 会出现如下报错:
1 | ROPgadget --binary init_60D_fwf > rop |
此时需要重新安装 capstone:
1 | sudo pip uninstall capstone |
如果出现这个报错:
1 | ➜ ~ ROPgadget |
这里需要将 ROPGadget 安装目录下的 script 目录拷贝到 /home/ubuntu/.local/lib/python3.10/site-packages/ROPGadget-7.5.dist-info 中。
1 | cd ROPGadget |
ropper
ropper 可以和 ROPgadget 配合使用,因为有的 gadget 使用 ROPgadget 搜不到,例如 arm32 架构的 Thumb 模式 gadget。
安装:
在 pypi 的 ropper 官网上下载 ropper
运行安装脚本完成 ropper 安装
1
sudo python3 setup.py install
使用:
1
ropper --file ./pwn --nocolor > rop
one_gadget
用于搜索 libc 中能够实现 execve("/bin/sh", (char *[2]) {"/bin/sh", NULL}, NULL); 的效果的跳转地址,由于是采用特征匹配的方法,因此只能是在 libc 中查找。
安装:
1
2sudo apt install -y ruby ruby-dev
sudo gem install one_gadget使用:可以查找到 gadget 地址以及条件限制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24➜ ~ one_gadget /lib/x86_64-linux-gnu/libc.so.6
0x50a37 posix_spawn(rsp+0x1c, "/bin/sh", 0, rbp, rsp+0x60, environ)
constraints:
rsp & 0xf == 0
rcx == NULL
rbp == NULL || (u16)[rbp] == NULL
0xebcf1 execve("/bin/sh", r10, [rbp-0x70])
constraints:
address rbp-0x78 is writable
[r10] == NULL || r10 == NULL
[[rbp-0x70]] == NULL || [rbp-0x70] == NULL
0xebcf5 execve("/bin/sh", r10, rdx)
constraints:
address rbp-0x78 is writable
[r10] == NULL || r10 == NULL
[rdx] == NULL || rdx == NULL
0xebcf8 execve("/bin/sh", rsi, rdx)
constraints:
address rbp-0x78 is writable
[rsi] == NULL || rsi == NULL
[rdx] == NULL || rdx == NULL如果
one_gadget在一个版本的 Ubuntu 中搜索某一版本的 glibc 的 gadget 出现如下报错可以尝试换另一个版本的 Ubuntu 。貌似是权限问题,可以以 root 权限重新装一下。

seccomp-tools
用于查看和生成程序沙箱规则。
安装:
1
sudo gem install seccomp-tools
使用:
1
seccomp-tools dump ./pwn
LibcSearcher
通过泄露的 libc 中函数的地址来确定 libc 版本。
1 | git clone https://github.com/lieanu/LibcSearcher.git |
glibc-all-in-one
临时找 glibc 和 ld 或者编译 glibc 。
1 | git clone https://github.com/matrix1001/glibc-all-in-one.git |
更新下载列表:
1 | ➜ glibc-all-in-one ./update_list |
下载 libc ,注意要安装解压工具 zstd ,因为下载脚本中用到了。
1 | sudo apt-get install zstd |
编译 libc
1 | sudo ./build [版本例如2.29] [架构例如 i686 amd64] |
patchelf
安装:
1 | sudo apt install patchelf |
qemu
1 | sudo apt install qemu-user qemu-system |
如何使用题目提供的 docker 环境
netcat
在官网下载项目源码,使用如下命令进行编译。
1 | ./configure LDFLAGS=-static # 考虑到 docker 环境恶劣选择静态编译 |
编译后生成的 netcat 位于项目 src 目录下。netcat 即我们常用的 nc 命令对应的可执行程序。
在 docker 中使用如下命令将题目 io 映射到 8888 端口。
1 | ./netcat -lvp 8888 -e ./pwn |
在本机可以使用如下命令连接并交互。(前提是 docker 的 8888 端口映射到本机的 8888 端口)
1 | nc 127.0.0.1 8888 |
gdb
在官网下载项目源码,使用如下命令编译 gdbserver :
1 | sudo apt-get install libgmp-dev libmpfr-dev |
对于 gdb ,由于编译 gdb 时依赖的静态库需要提前编译,因此想要编译 gdb 最好直接编译整个项目:
1 | cd gdb-9.2 |
注意以下几点:
- 编译的
gdbserver版本一定要与本机的gdb匹配,不同版本的gdbserver通信协议不同。 - 有的时候在
gdbserver中运行./configuer命令会出现找不到Makefile的情况,这时在根目录进行一次编译就好了。 - 连接失败之后再运行一次编译命令就可能编译成功。
gdb位于./gdb/gdb中。gdbserver位于./gdbserver/gdbserver中。
docker
加载镜像
1
docker load -i 题目附件.tar
查看现有镜像
1
docker images
启动容器
1
docker run --privileged -it -w /home/ctf -v ~/Desktop/本机目录:/home/ctf/镜像目录 -p 8888:8888 -p 9999:9999 镜像名 /bin/bash
--privileged:加这个参数才能gdbserver附加进程远程调试-v:目录映射,方便传文件。-p:端口映射,开两个端口分别给netcat和gdbserver用。改用--net=host可以映射全部端口。-w:进入 docker 后目录为/home/ctf。
查看现有容器
1
docker ps
进容器 shell ,即同一个容器再开一个 shell 。
1
sudo docker exec -it -w /home/ctf 容器ID /bin/bash
停止所有容器:
1
docker stop $(docker ps -a -q)
删除所有容器:
1
docker rm $(docker ps -a -q)
删除所有镜像:
1
docker rmi $(docker images -q)
使用方法
exp.py 模板如下:
1 | from pwn import * |
运行脚本前首先在 docker 容器中用
netcat将题目程序 IO 映射到 8888 端口:1
./netcat -lvp 8888 -e ./pwn
运行脚本,阻塞在
gdb.attach时脚本已经与远程的netcat连接,此时 docker 镜像中已经有pwn这个进程了。此时使用ps -aux | grep pwn查看进程pid然后运行如下命令让gdbserver附加进程并监听 9999 端口。1
gdbserver :9999 --attach 进程pid
此时脚本执行
gdb.attach连接 docker 中的gdbserver并阻塞在pause()上直到gdb成功连接gdbserver。在脚本运行窗口按回车解除阻塞进行调试。
其中 docker 中的操作可以通过脚本自动化实现。
1 |
|
ELF 文件格式
ELF(Executable and Linkable Format)是一种常见的可执行文件和可链接文件格式,主要用于Linux和类Unix系统。ELF 文件可以包含不同的类型,常见的 ELF 文件类型包括:
- 可执行文件(
ET_EXEC):这种类型的 ELF 文件是可直接执行的程序,可以在操作系统上运行。 - 共享目标文件(
ET_DYN):这种类型的 ELF 文件是可被动态链接的共享库,可以在运行时与其他程序动态链接。该类型文件后缀名为.so。 - 可重定位文件(
ET_REL):这种类型的 ELF 文件是编译器生成的目标文件,通常用于将多个目标文件链接到一个可执行文件或共享库中。该类型文件后缀名为.o,静态链接库(.a)也可以归为这一类。 - 核心转储文件(
ET_CORE):这种类型的 ELF 文件是操作系统在程序崩溃或发生错误时生成的核心转储文件,用于调试和分析程序崩溃的原因。
ELF 文件结构及相关常数被定义在 /usr/include/elf.h 里,因为 ELF 文件在各种平台下都通用,ELF文件有 32 位版本和 64 位版本。32 位版本与 64 位版本的 ELF 文件的格式基本是一样的(部分结构体为了优化对齐后大小调整了成员的顺序),只不过有些成员的大小不一样。
elf.h 使用 typedef 定义了一套自己的变量体系:
| 自定义类型 | 描述 | 原始类型 | 长度(字节) |
|---|---|---|---|
Elf32_Addr |
32 位版本程序地址 | uint32_t |
4 |
Elf32_Half |
32 位版本的无符号短整型 | uint16_t |
2 |
Elf32_Off |
32 位版本的偏移地址 | uint32_t |
4 |
Elf32_Sword |
32 位版本有符号整型 | uint32_t |
4 |
Elf32_Word |
32 位版本无符号整型 | int32_t |
4 |
Elf64_Addr |
64 位版本程序地址 | uint64_t |
8 |
Elf64_Half |
64 位版本的无符号短整型 | uint16_t |
2 |
Elf64_Off |
64 位版本的偏移地址 | uint64_t |
8 |
Elf64_Sword |
64 位版本有符号整型 | uint32_t |
4 |
Elf64_Word |
64 位版本无符号整型 | int32_t |
4 |
ELF 主要管理结构为文件头,程序头表(可重定位文件没有)和节表,其他部分有一个个节组成,多个属性相同的节构成一个段。对于节的介绍这里按照静态链接相关和动态链接相关分别介绍。

文件头
我们这里以 32 位版本的文件头结构 Elf32_Ehdr 作为例子来描述,它的定义如下:
1 | /* The ELF file header. This appears at the start of every ELF file. */ |
e_ident:ELF 文件的魔数和其他信息。- 前 4 字节为
ELFMAG即\x7fELF。 - 第 5 字节为 ELF 文件类型,值为
ELFCLASS32(1)代表 32 位,值为ELFCLASS64(2)代表 64 位。 - 第 6 字节为 ELF 的字节序,0 为无效格式,1 为小端格式,2 为大端格式。
- 第 7 字节为 ELF 版本,一般为 1 ,即 1.2 版本。
- 后面 9 字节没有定义一般填 0 ,有些平台会使用这 9 个字节作为扩展标志。
- 前 4 字节为
e_type:表示ELF文件类型,如可执行文件、共享对象文件(.so)、可重定位文件(.o)等。e_machine:表示目标体系结构,即程序的目标平台,如 x86、ARM 等。相关常量以EM_开头。e_version:ELF 文件版本号,一般为常数 1 。e_entry:表示程序入口点虚拟地址。操作系统加载完程序后从这个地址开始执行进程的命令。可重定位文件一般没有入口地址,则这个值为 0 。e_phoff:表示程序头表的文件偏移量。e_shoff:表示节表的文件偏移量。e_flags:表示处理器特定标志。e_ehsize:表示 ELF 文件头的大小。e_phentsize:表示程序头表中每个表项的大小。e_phnum:表示程序头表中表项的数量。e_shentsize:表示节表中每个表项的大小。e_shnum:表示节表中表项的数量。e_shstrndx:表示节表中字符串表的索引。
程序头表
ELF 可执行文件中有一个专门的数据结构叫做程序头表(Program Header Table)用来保存段(注意不是节)的信息。因为 ELF 目标文件不需要被装载,所以它没有程序头表,而 ELF 的可执行文件和共享库文件都有程序头表。
程序头表是由 Elf*_Phdr 组成的数组,用于描述 ELF 文件中每个节的属性和信息。
1 | /* Program segment header. */ |
p_type:段的类型,例如可执行段、数据段等。p_offset:段在文件中的偏移量。p_vaddr:段在虚拟内存中的起始地址。p_paddr:段在物理内存中的起始地址。因为 ELF 还没装载不知道物理地址,所以作为保留字段。通常和p_vaddr的值是一样的。p_filesz:段在文件中的大小。p_memsz:段在内存中的大小。p_flags:段的标志,例如可读、可写、可执行等。p_align:段在文件和内存中的对齐方式。段的的加载地址要能被 整除。
节表
ELF文件里面定义一个固定长度的 Elf*_Shdr 结构体数组用来存放节相关信息,与 PE 文件的节表相似。
在 ELF 文件中,段(Segment)和节(Section)是两个不同的概念,它们在文件结构中具有不同的作用和目的。
段(Segment)是一种逻辑上的组织单位,它定义了可执行文件或共享库在内存中的一个连续区域。每个段都有自己的虚拟地址空间,可以包含多个节。常见的段类型包括代码段(.text),数据段(.data、.bss),只读数据段(.rodata)等。段在加载和执行时被操作系统用来管理内存,设置内存保护属性以及指定虚拟地址空间的起始地址和大小。
节(Section)是一种更细粒度的组织单位,它包含了文件中的特定类型的数据或代码。每个节都有自己的名字、类型和内容。常见的节类型包括代码节(.text),数据节(.data、.bss),只读数据节(.rodata),符号表节(.symtab),字符串表节(.strtab)等。节不直接参与内存的加载和执行,而是用于链接器(Linker)和调试器(Debugger)等工具对文件进行处理和分析。
通俗的讲,在装载程序的时候为了节省内存会将 ELF 文件中属性相同的节(Section)合并成在一个段(Segment)加载到内存中。
段和节之间存在对应关系和映射关系:
- 一个段可以包含多个节,这些节的内容和属性都属于该段。
- 段提供了对应于虚拟内存的逻辑映射,而节则提供了对应于文件的逻辑映射。
- 段的加载和执行涉及内存管理和地址映射,而节则用于链接和调试过程中的符号解析、重定位等操作。
其中 Elf32_Shdr 定义如下:
1 | /* Section header. */ |
sh_name:表示节的名称在字符串表中的索引。字符串表节存储了所有节的名称,sh_name指定了节的名称在字符串表中的位置。sh_type:表示节的类型,指定了节的用途和属性。常见的类型包括代码段(SHT_PROGBITS(1))、数据段(SHT_PROGBITS(1))、符号表(SHT_SYMTAB(2))、字符串表(SHT_STRTAB(3))等。sh_flags:表示节的标志,用于描述节的特性和属性。标志的具体含义取决于节的类型和上下文。sh_addr:表示节的虚拟地址,只在可执行文件中有意义。对于可执行文件,sh_addr指定了节在内存中的加载地址,如果该节不可被加载,则该值为 0 。sh_offset:表示节在文件中的偏移量,指定了节在文件中的位置。对于 bss 段来说该值没有意义。sh_size:表示节的大小,指定了节所占据的字节数。sh_link:表示链接到的其他节的索引,用于建立节之间的关联关系,具体含义依赖于节的类型。sh_info:附加信息,具体含义依赖于节的类型。sh_addralign:表示节的地址对齐要求,指定了节在内存中的对齐方式。即sh_addr需要满足 。如果sh_addralign为 0 或 1 表示该段没有对齐要求。sh_entsize:表示节中每个项的大小,如果该字段为 0 说明节中不包含固定大小的项。
ELF 中常见的节如下:
.text:代码段(Code Section),用于存储程序的可执行指令。.rodata:只读数据段(Read-Only Data Section),用于存储只读的常量数据,例如字符串常量。.data:数据段(Data Section),用于存储已初始化的全局变量和静态变量。.bss:未初始化的数据段(Block Started by Symbol),用于存储未初始化的全局变量和静态变量。它不占用实际的文件空间,而是在运行时由系统自动初始化为零。.symtab:符号表节(Symbol Table Section),用于存储程序的符号表信息,包括函数、变量和其他符号的名称、类型和地址等。.strtab:字符串表节(String Table Section),用于存储字符串数据,如节名称、符号名称等。字符串表节被多个其他节引用,通过偏移量和索引来访问具体的字符串。.rel.text或.rela.text:代码重定位节(Relocation Section),用于存储代码段中的重定位信息,以便在链接时修正代码中的符号引用。.rel.data或.rela.data:数据重定位节(Relocation Section),用于存储数据段中的重定位信息,以便在链接时修正数据段中的符号引用。.dynamic:动态节(Dynamic Section),用于存储程序的动态链接信息,包括动态链接器需要的重定位表、共享对象的名称、版本信息等。.note:注释节(Note Section),用于存储与程序或库相关的注释或调试信息。
静态链接相关
注意:静态链接相关只在可重定位文件中存在。比如可执行文件,如果不开启 PIE 加载地址固定,不需要对自身进行重定位,而开启 PIE 后为地址无关代码,也不需要对自身进行重定位。因此不需要静态链接也就丢弃了静态链接相关的节。
符号表(.symtab)
注意:符号表除了静态链接外没有用,但是程序为了方便调试会保留符号表,我们可以通过 strip + 程序名 的方式将符号表去除,这就是为什么有的 pwn 题的附件没有函数和变量名而有的却有。
ELF 文件中的符号表往往是文件中的一个段,段名一般叫 .symtab 。符号表是一个 Elf*_Sym 结构(32 位 ELF 文件)的数组,每个 Elf*_Sym 结构对应一个符号。
1 | /* Symbol table entry. */ |
st_name:符号名称在字符串表中的偏移量。st_value:符号的值,即符号的地址或偏移量。- 如果该符号在目标文件中,如果是符号的定义并且该符号不是
COMMON块类型的则st_value表示该符号在段中的偏移。 - 在目标文件中,如果符号是
COMMON块类型的则st_value表示该符号的对齐属性。 - 在可执行文件中,
st_value表示符号的虚拟地址。
- 如果该符号在目标文件中,如果是符号的定义并且该符号不是
st_size:符号的大小,如果符号是一个函数,则表示函数的大小。如果该值为 0 表示符号的大小为 0 或未知。st_info:该字段是一个字节,包含符号的类型和绑定信息。符号类型包括函数、数据、对象等,符号绑定包括局部符号、全局符号、弱符号等。该字段的高 4 位表示符号的类型,低 4 位表示符号的绑定信息。st_other:保留字段,通常为 0 。st_shndx:通常为符号所在节的索引。- 如果符号是一个常量,该字段为
SHN_ABS(初始值不为 0 的全局变量) 或SHN_COMMON(初始值为 0 的全局变量)。 - 如果该符号未定义但是在该文件中被引用到,说明该符号可能定义在其他目标文件中,则该字段为
SHN_UNDEF。
- 如果符号是一个常量,该字段为
重定位表(.rel.text/.rel.data)
重定位表是一个 Elf*_Rel 结构的数组,每个数组元素对应一个重定位入口。重定位表主要有.rel.text 或 .rela.text,即代码重定位节(Relocation Section)和 .rel.data 或 .rela.data:数据重定位节(Relocation Section)。
1 | /* Relocation table entry without addend (in section of type SHT_REL). */ |
r_offset:需要进行重定位的位置的偏移量或地址。这个位置通常是指令中的某个操作数或数据的地址,需要在链接时进行修正,以便正确地引用目标符号。- 对于可执行文件或共享库,
r_offset表示需要修改的位置在内存中的位置(用于动态链接)。 - 对于可重定位文件,
r_offset表示需要修改的位置相对于段起始位置的偏移(用于静态链接)。
- 对于可执行文件或共享库,
r_info:低 8 位表示符号的重定位类型,重定位类型指定了进行何种类型的修正,例如绝对重定位、PC 相对重定位等。高 24 位表示该符号在符号表中的索引,用于解析重定位所引用的符号。
字符串表(.strtab)
ELF 文件中用到了很多字符串,比如段名、变量名等。因为字符串的长度往往是不定的,所以用固定的结构来表示它比较困难。一种很常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。
通过这种方法,在ELF文件中引用字符串只须给出一个数字下标即可,不用考虑字符串长度的问题。一般字符串表在ELF文件中也以段的形式保存,常见的段名为“.strtab”或“.shstrtab”。这两个字符串表分别为字符串表(String Table)和段表字符串表(Section Header String Table)。顾名思义,字符串表用来保存普通的字符串,比如符号的名字;段表字符串表用来保存段表中用到的字符串,最常见的就是段名(sh_name )。
注意,在字符串表中的每个字符串的开头和结尾都有一个 \x00 填充。
动态链接相关
.interp 段
在动态链接的 ELF 可执行文件中,有一个专门的段叫做 .interp 段(“interp”是“interpreter”(解释器)的缩写)。
.interp 的内容很简单,里面保存的就是一个字符串 /lib64/ld-linux-x86-64.so.2 ,这个字符串就是可执行文件所需要的动态链接器的路径。
通常系统通过判断一个 ELF 程序是否有 .interp 来判断该 ELF 文件是否为动态链接程序。
.dynamic 段
动态链接 ELF 中最重要的结构是 .dynamic 段,这个段里面保存了动态链接器所需要的基本信息,比如依赖于哪些共享对象、动态链接符号表的位置、动态链接重定位表的位置、共享对象初始化代码的地址等。.dynamic 段是由Elf*_Dyn 构成的结构体数组。
1 | /* Dynamic section entry. */ |
Elf32_Dyn 结构由一个类型值加上一个附加的数值或指针,对于不同的类型,后面附加的数值或者指针有着不同的含义。我们这里列举几个比较常见的类型值(这些值都是定义在 elf.h 里面的宏),
DT_SYMTAB:指定了符号表的地址,d_ptr表示.dynsym的地址。DT_STRTAB:指定了字符串表的地址,d_ptr表示.synstr的地址。DT_STRSZ:指定了字符串表的大小,d_val表示大小。DT_HASH:指定了符号哈希表的地址,用于加快符号查找的速度,d_ptr表示.hash的地址。DT_SONAME:指定了共享库的名称。DT_RPATH:指定了库搜索路径(已废弃,不推荐使用)。DT_INIT:指定了初始化函数的地址,动态链接器在加载可执行文件或共享库时会调用该函数。DT_FINI:指定了终止函数的地址,动态链接器在程序结束时会调用该函数。DT_NEEDED:指定了需要的共享库的名称。DT_REL/DT_RELA:指定了重定位表的地址。
动态符号表(.dynsym)
为了完成动态链接,最关键的还是所依赖的符号和相关文件的信息。我们知道在静态链接中,有一个专门的段叫做符号表 .symtab(Symbol Table),里面保存了所有关于该目标文件的符号的定义和引用。为了表示动态链接这些模块之间的符号导入导出关系,ELF 专门有一个叫做动态符号表(Dynamic Symbol Table)的段用来保存这些信息,这个段的段名通常叫做 .dynsym(Dynamic Symbol),同样也是由 Elf*_Sym 构成的结构体数组。
与 .symtab 不同的是,.dynsym 只保存了与动态链接相关的符号,对于那些模块内部的符号,比如模块私有变量则不保存。很多时候动态链接的模块同时拥有 .dynsym 和 .symtab 两个表,.symtab 中往往保存了所有符号,包括 .dynsym 中的符号。
与 .symtab 类似,动态符号表也需要一些辅助的表,比如用于保存符号名的字符串表。静态链接时叫做符号字符串表 .strtab(String Table),在这里就是动态符号字符串表 .dynstr(Dynamic String Table);由于动态链接下,我们需要在程序运行时查找符号,为了加快符号的查找过程,往往还有辅助的符号哈希表(.hash)。
动态链接重定位表(.rel.dyn/.rel.data)
共享对象需要重定位的主要原因是导入符号的存在。动态链接下,无论是可执行文件或共享对象,一旦它依赖于其他共享对象,也就是说有导入的符号时,那么它的代码或数据中就会有对于导入符号的引用。在编译时这些导入符号的地址未知,在静态链接中,这些未知的地址引用在最终链接时被修正。但是在动态链接中,导入符号的地址在运行时才确定,所以需要在运行时将这些导入符号的引用修正,即需要重定位。
共享对象的重定位与我们在前面“静态链接”中分析过的目标文件的重定位十分类似,唯一有区别的是目标文件的重定位是在静态链接时完成的,而共享对象的重定位是在装载时完成的。在静态链接中,目标文件里面包含有专门用于表示重定位信息的重定位表,比如 .rel.text 表示是代码段的重定位表,.rel.data 是数据段的重定位表。
动态链接的文件中,也有类似的重定位表分别叫做 .rel.dyn 和 .rel.plt ,它们分别相当于 .rel.data 和 .rel.text 。.rel.dyn 实际上是对数据引用的修正,它所修正的位置位于 .got 以及数据段;而 .rel.plt 是对函数引用的修正,它所修正的位置位于 .got.plt 。
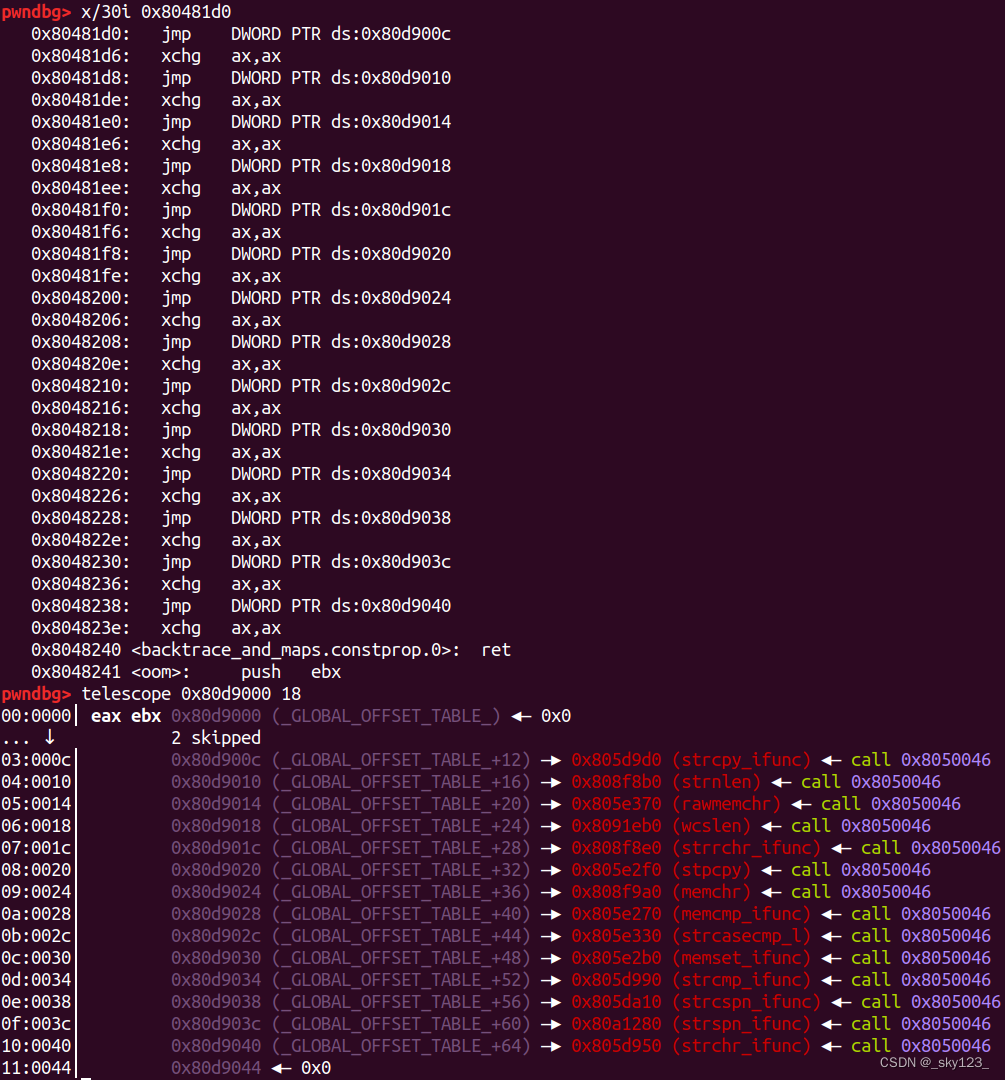
PLT 表(.plt)
在未开启 FULL RELRO 的情况下 PLT 表的结构如下图所示, PLT 表在 .plt(有的还包括 .plt.got) 中。
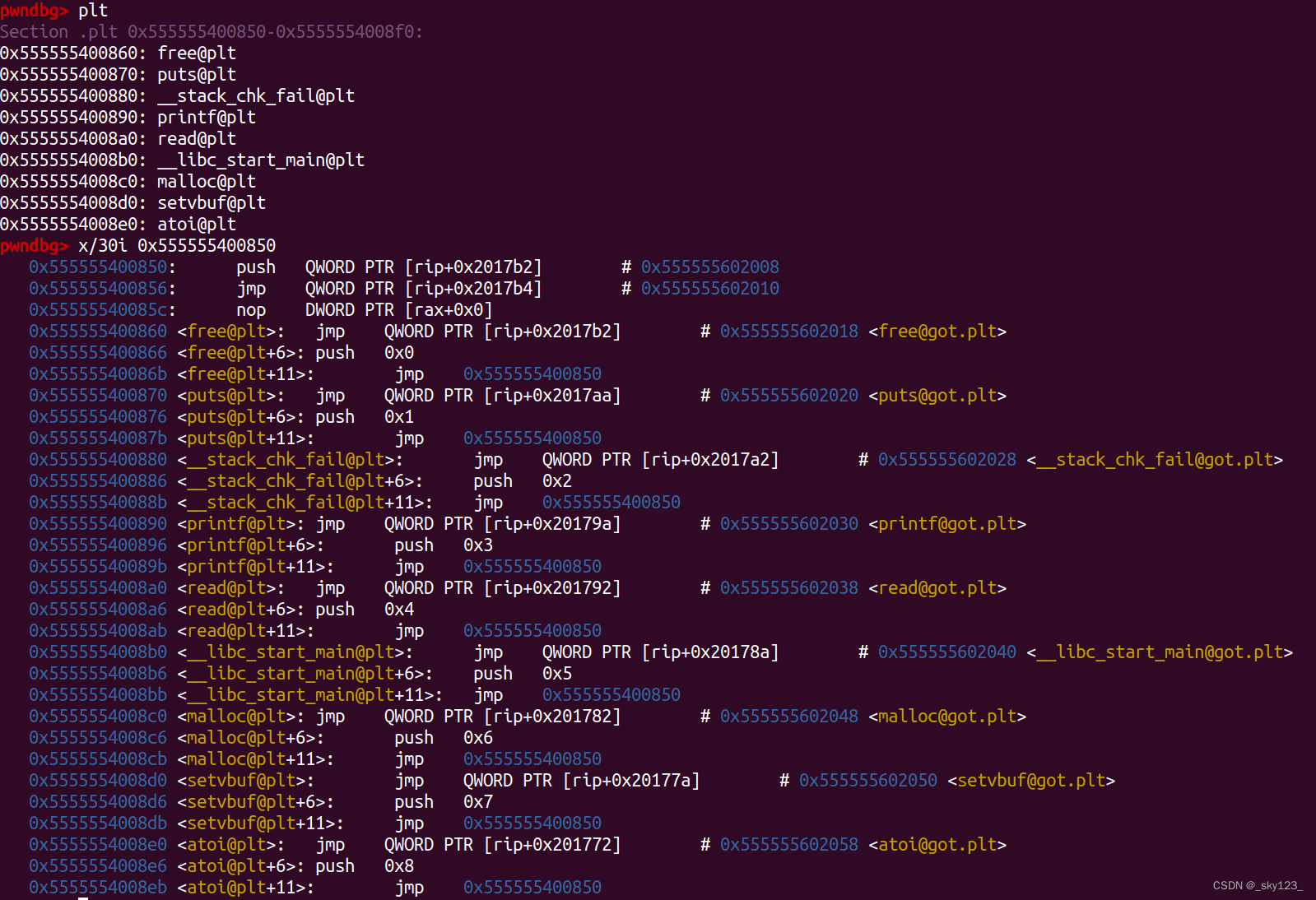
PLT 表的形式如下所示:
其中 为函数 bar 在 GOT 表中的值的索引,bar@GOT 中初始值为 jmp *(bar@GOT) 指令的下一条指令,也就是说第一次调用 bar 函数的时候会继续执行跳转至 PLT0 进行 bar@GOT 的重定位并调用 bar 函数;第二次调用 bar 函数的时候由于 bar@GOT 已完成重定位因此会直接跳转至 bar 函数。
在开启 FULL RELRO 的情况下 PLT 表的结构如下图所示,此时的 PLT 表在 .plt.sec 而不是 .plt 中。
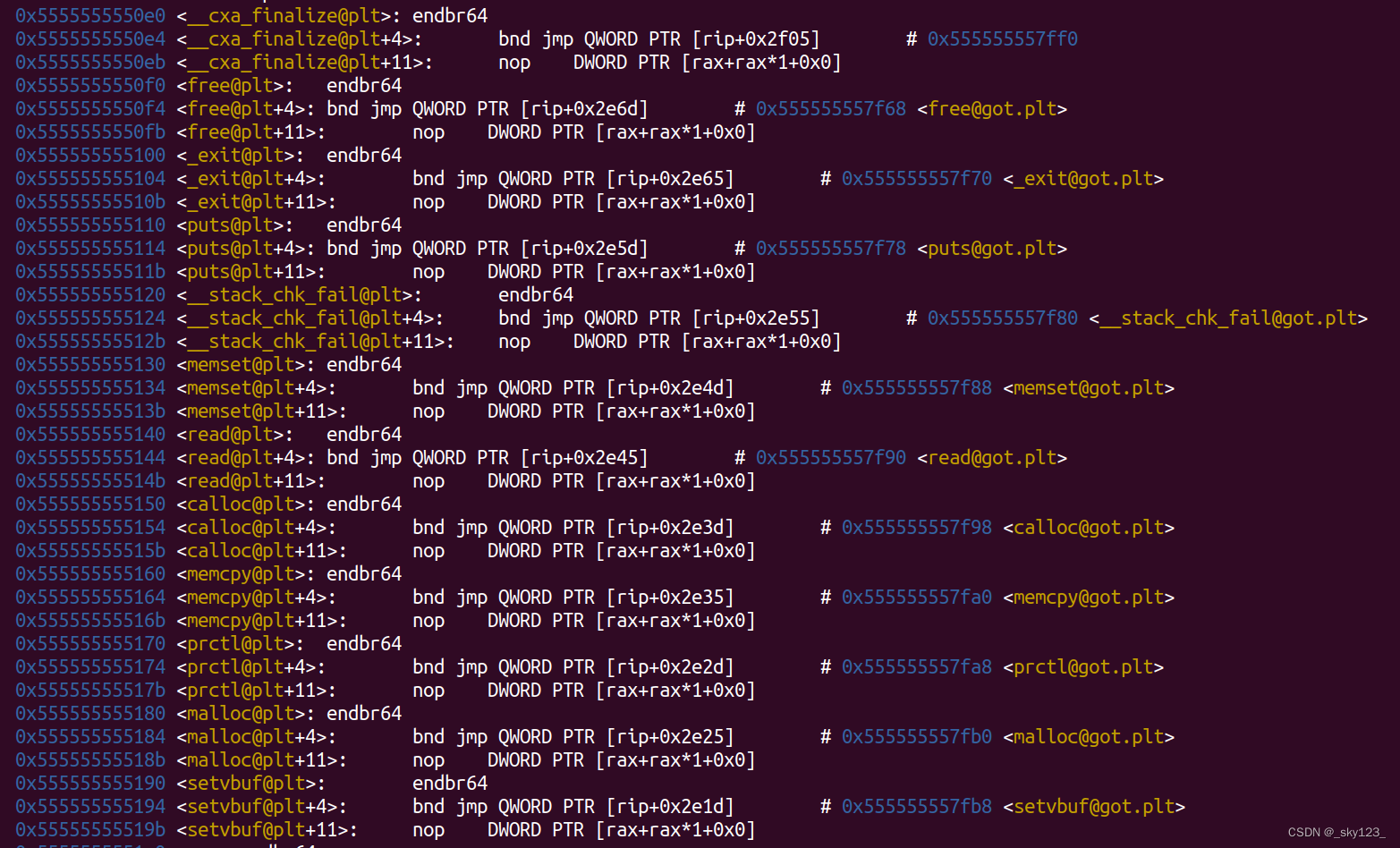
由于 GOT 表在装载时已经完成重定位且不可写,因此不存在延迟绑定,PLT 直接根据 GOT 表存储的函数地址进行跳转。
GOT 表(.got/.got.plt)
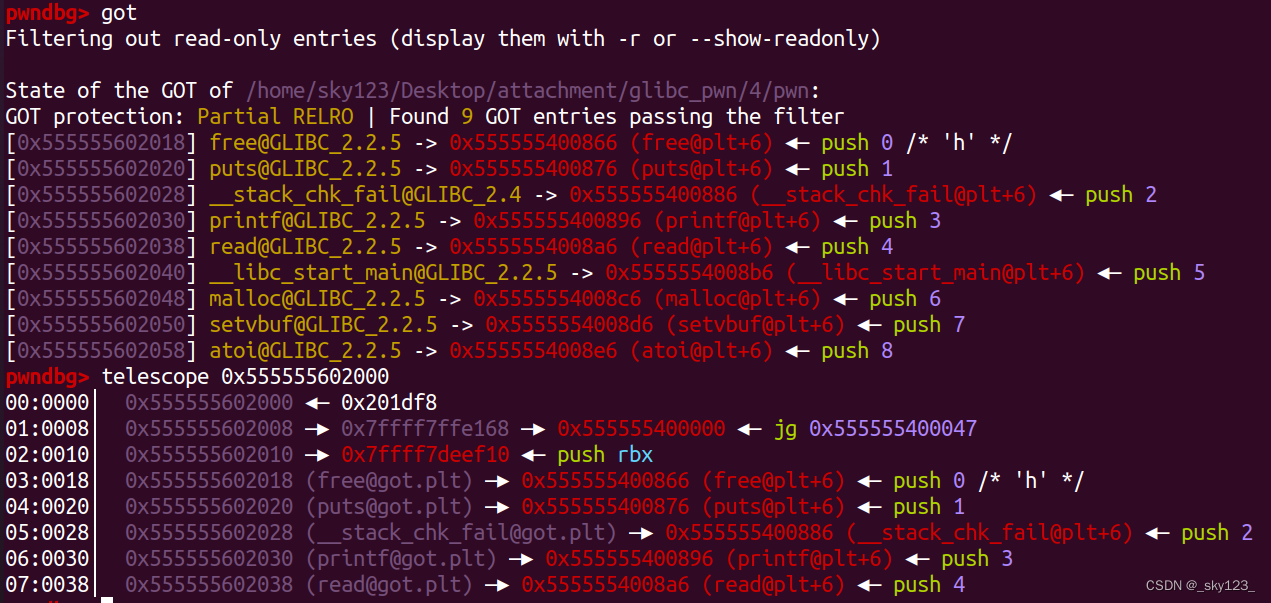
ELF 将 GOT 拆分成了两个表叫做 .got 和 .got.plt 。其中 .got 用来保存全局变量引用的地址,.got.plt 用来保存函数引用的地址,也就是说,所有对于外部函数的引用全部被分离出来放到了 .got.plt 中(当然有的 ELF 文件可能吧这两个表合并为一个 .got 表,结构等同于后面提到的 .got.plt)。另外 .got.plt 还有一个特殊的地方是它的前三项是有特殊意义的,分别含义如下:
- 第一项保存的是
.dynamic段的偏移(也有可能是.dynamic段的地址)。 - 第二项是一个
link_map的结构体指针,里面保存着动态链接的一些相关信息,是重定位函数_dl_runtime_resolve的第一个参数。 - 第三项保存的是
_dl_runtime_resolve的地址。
.got.plt 在内存中的状态如下图所示:
注意:静态链接程序也是有 plt 表和 got 表的,并且 plt 表也会被调用。
辅助信息数组
无论静态还是动态链接程序都有辅助信息数组,只是动态链接程序是动态链接器使用辅助信息数组。
站在动态链接器的角度看,当操作系统把控制权交给它的时候,它将开始做链接工作,那么至少它需要知道关于可执行文件和本进程的一些信息,比如可执行文件有几个段(“Segment”)、每个段的属性、程序的入口地址(因为动态链接器到时候需要把控制权交给可执行文件)等。
这些信息往往由操作系统传递给动态链接器,保存在进程的堆栈里面。我们在前面提到过,进程初始化的时候,事实上,堆栈里面还保存了动态链接器所需要的一些辅助信息数组(Auxiliary Vector)。辅助信息的格式也是一个结构数组,它的结构被定义在 elf.h :
1 | typedef struct |
a_type字段表示辅助信息数组的类型。下面是一些常见的a_type值及其对应的含义:AT_NULL (0):辅助向量列表的结束标志。在列表的最后一个条目中使用。AT_IGNORE (1):忽略的辅助向量类型。在某些情况下,可以将该类型的辅助向量忽略。AT_EXECFD (2):可执行文件的文件描述符。表示打开可执行文件的文件描述符。AT_PHDR (3):程序头表的地址。指向程序头表在内存中的起始地址。AT_PHENT (4):程序头表中每个条目的大小(字节)。指示每个程序头表条目的字节数。AT_PHNUM (5):程序头表的条目数量。指示程序头表中的条目数量。AT_PAGESZ (6):页面大小。表示操作系统使用的页面大小。AT_BASE (7):共享对象的基地址。指向主共享对象的基地址。AT_FLAGS (8):标志位。包含一些特定于操作系统的标志。AT_ENTRY (9):程序入口点的地址。指向程序的入口点地址。AT_NOTELF (10):不是ELF文件。指示加载程序的文件不是有效的ELF文件。
a_un:该成员是一个联合体(union),用于存储辅助向量条目的值。在这段代码中,由于指针类型的元素会在 32 位和 64 位平台上产生兼容性问题,所以注释中提到不再添加指针元素。a_val:如果辅助向量条目的类型是一个整数值,那么该成员将存储该整数值。它也是一个 32 位的无符号整数。
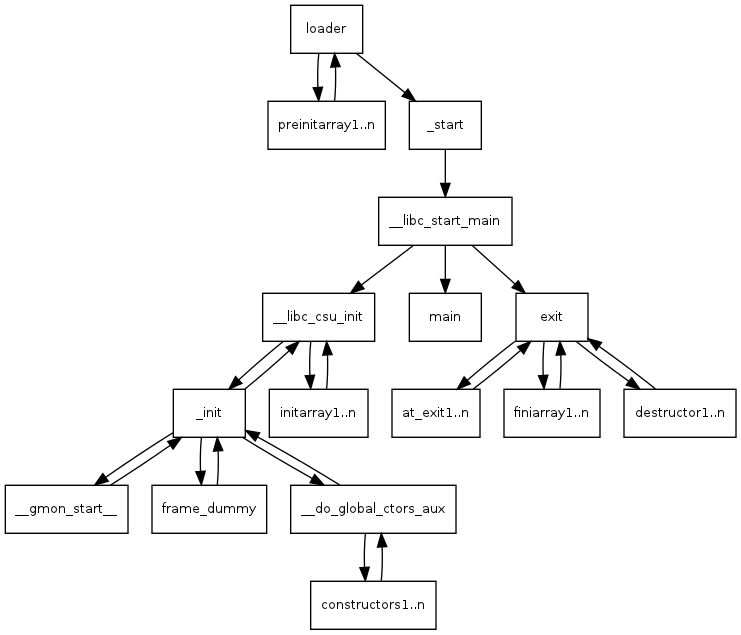
程序编译过程
从源文件编译链接形成 ELF 文件的过程如下图所示:
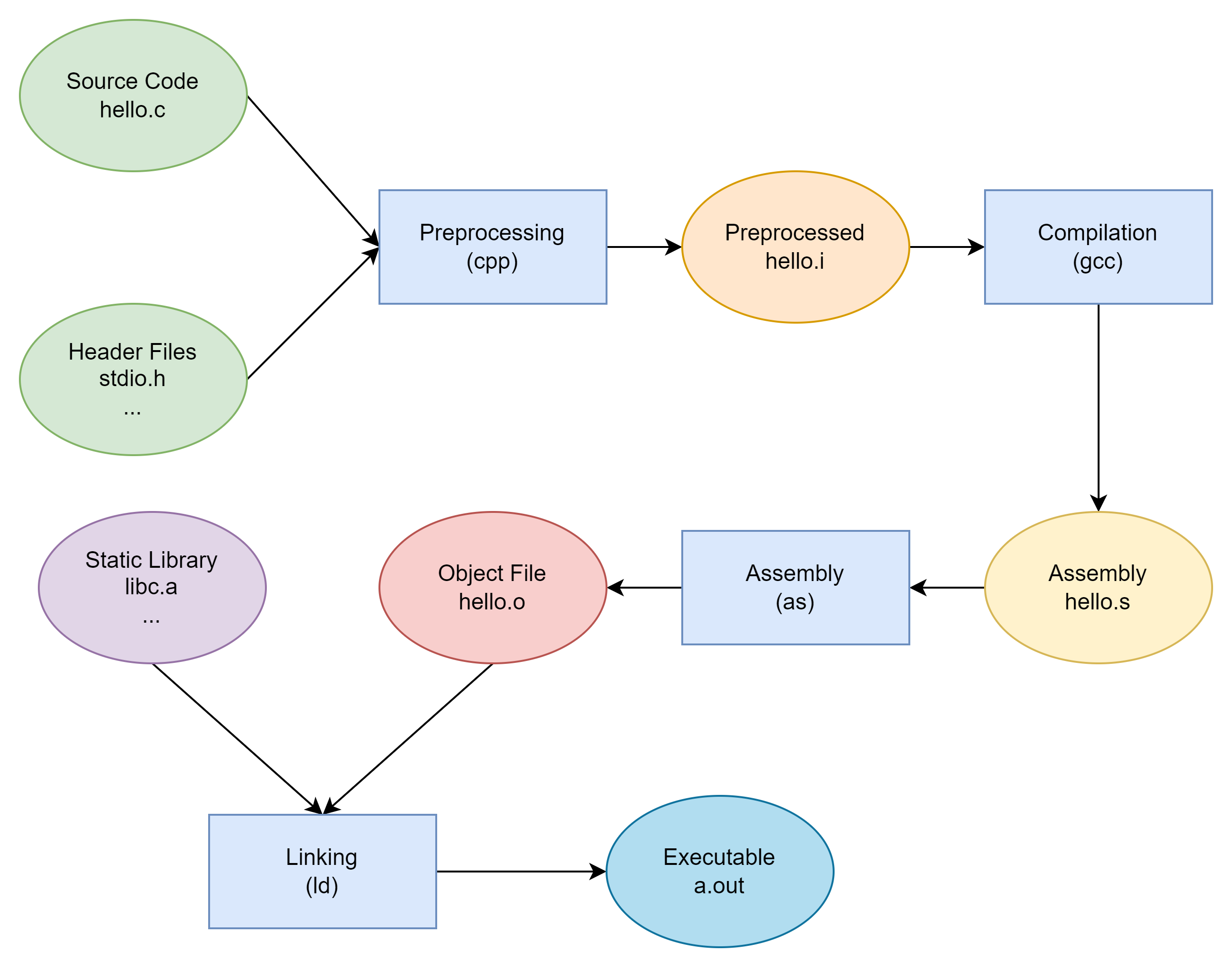
预编译
首先是源代码文件和相关的头文件,如 stdio.h 等被预编译器 cpp 预编译成一个 .i 文件。对于 C++ 程序来说,它的源代码文件的扩展名可能是 .cpp 或 .cxx ,头文件的扩展名可能是 .hpp ,而预编译后的文件扩展名是 .ii 。
第一步预编译的过程相当于如下命令(-E 表示只进行预编译):
1 | gcc –E hello.c –o hello.i |
或者:
1 | cpp hello.c > hello.i |
预编译过程主要处理那些源代码文件中的以 # 开始的预编译指令。比如 #include 、#define 等,主要处理规则如下:
- 将所有的
#define删除,并且展开所有的宏定义。 - 处理所有条件预编译指令,比如
#if、#ifdef、#elif、#else、#endif。 - 处理
#include预编译指令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件。 - 删除所有的注释
//和/* */。 - 添加行号和文件名标识,比如
#2"hello.c"2,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号。 - 保留所有的
#pragma编译器指令,因为编译器须要使用它们。
经过预编译后的 .i 文件不包含任何宏定义,因为所有的宏已经被展开,并且包含的文件也已经被插入到 .i 文件中。所以当我们无法判断宏定义是否正确或头文件包含是否正确时,可以查看预编译后的文件来确定问题。
编译
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生产相应的汇编代码文件,这个过程往往是我们所说的整个程序构建的核心部分,也是最复杂的部分之一。
上面的编译过程相当于如下命令:
1 | gcc –S hello.i –o hello.s |
汇编
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译就可以了,“汇编”这个名字也来源于此。
上面的汇编过程我们可以调用汇编器 as 来完成:
1 | as hello.s –o hello.o |
或者使用 gcc 命令从 C 源代码文件开始,经过预编译、编译和汇编直接输出目标文件(Object File):
1 | gcc –c hello.c –o hello.o |
链接
静态链接
静态链接是在编译过程的最后阶段将多个目标文件(如 .o 文件)以及所需的库文件合并在一起,生成最终的可执行文件或共享库的过程。
可以使用如下命令将 a.o 和 b.o 链接为目标文件 ab 。
1 | ld a.o b.o -o ab |
合并代码和数据段(Code and Data Segment Merging)
链接器将多个目标文件中的代码段和数据段合并成一个更大的代码段和数据段。这样,所有的目标文件中的代码和数据都会被整合到最终的可执行文件或静态库中。
符号解析(Symbol Resolution)
链接器负通过重定位表解析目标文件中的符号引用。每个目标文件都包含对其他目标文件或库中定义的符号的引用,例如函数、变量等。链接器会检查这些引用并确定对应的定义位置。
对于可重定位的 ELF 文件来说,它必须包含有重定位表,用来描述如何修改相应的段里的内容。对于每个要被重定位的 ELF 段都有一个对应的重定位表,而一个重定位表往往就是 ELF 文件中的一个段,所以其实重定位表也可以叫重定位段。
比如代码段 .text 如有要被重定位的地方,那么会有一个相对应叫 .rel.text 的段保存了代码段的重定位表;如果代码段 .data 有要被重定位的地方,就会有一个相对应叫 .rel.data 的段保存了数据段的重定位表。
链接器通过 Elf32_Rel 的 r_offset 加上所在段的起始位置得到重定位入口的位置;通过 r_info 的低 8 为得知重定位类型;通过 r_info 的高 24 位得到重定位符号在符号表(.symtab)中的下标。
符号重定位(Symbol Relocation)
链接器通过符号表对应的 Elf32_Rel 的 st_value 表示该符号在段中的偏移,进而可以根据重定位类型计算出重定位入口所要修正的值。最后将对应的重定位入口 patch 成正确的值。32 位静态链接常用到的重定位类型如下:
R_386_32:绝对地址。R_386_PC32:相对于当前指令地址的下一条指令相对地址。
解析库依赖关系(Library Dependency Resolution)
如果目标文件依赖于外部库文件(如标准库或其他第三方库),链接器会解析这些库的依赖关系,并将所需的库文件链接到最终的可执行文件或静态库中。这样,在运行时,可执行文件或静态库就能够访问和使用这些库中提供的功能。
生成重定位表(Relocation Table)
链接器生成重定位表,记录了需要进行符号重定位的位置和相关信息。这些重定位表将在最终的可执行文件或静态库中被使用,以便在加载和执行时进行正确的符号重定位。
动态链接
动态链接(Dynamic Linking)本质是指把链接这个过程推迟到了运行时再进行,准确的说这个过程应该放在装载部分。不过动态链接的出现很大一部分原因是为了解决内存浪费问题,因此直接照搬静态链接的方式不合理,需要做一些改变。
另外我们称一个程序为动态链接程序或静态链接程序指的是该程序是否有动态链接过程。
注意动态链接不包括合并代码和数据段的过程,各个模块在内存中独立存在。
装载时重定位
由于需要将多个模块装载到内存中,因此动态链接难免会有地址冲突问题,这就需要我们在加载的时候将模块中的相关地址修改为正确的值,这就是装载时重定位。
Linux和GCC支持这种装载时重定位的方法,在产生共享对象时,使用了两个GCC参数 -shared 和 -fPIC ,如果只使用 -shared ,那么输出的共享对象就是使用装载时重定位的方法。
地址无关代码
把同一个模块装到不同虚拟地址,如果在代码里写死了绝对地址,就需要修改代码段里的指令(所谓“对 .text 做重定位”),这会让代码页变成私有页,无法在多个进程间共享,也拉低启动性能。
用 地址无关代码(PIC)把“和绝对地址相关的东西”挪到数据表里就可以解决上述问题:
- 代码中的控制流(
call/jmp)尽量用相对位移; - 代码若要取“某个符号的绝对地址”,就先去 GOT(全局偏移表) 拿该符号当前进程里的真实地址,再访问;
- 调外部函数用 PLT(过程链接表):
call foo@plt→ PLT 查/填 GOT → 真正跳到函数。首次调用解析,之后命中 GOT(延迟绑定)。
此时模块内与模块间
模块内控制流:天然 PC‑relative,对同一模块内的符号,用“相对当前指令的偏移”寻址(不依赖装载基址),无需表项。
注:x86‑64 上 RIP 是顺序下一条指令的地址(fall‑through),PC‑relative 以它为基准计算偏移。
模块内数据:
static/hidden:直接 RIP‑relative;- 默认可见全局:为支持 ELF 符号截获语义,经 GOT 间接。
模块间:
- 函数:PLT+GOT(支持延迟绑定);
- 数据:通过 GOT 间接;若主程序是非 PIE而直接引用共享库变量,可能触发 Copy relocation(启动时把值拷贝一份到主程序的
.bss)。
延迟绑定
在使用动态链接的程序里,模块之间常常存在大量的函数调用(而为了降低耦合,跨模块的可写全局变量一般较少)。如果在程序启动时就把所有外部函数的地址都解析并重定位完,会带来不必要的启动开销——毕竟很多函数在一次运行中从未被调用。因此,ELF/ld.so 采用延迟绑定:仅在函数第一次被调用时,才进行符号查找与对应 GOT 表的修补;未被用到的函数不会提前绑定,从而缩短启动时间,特别适合依赖众多库、外部调用巨量的程序。
只对“函数调用”可延迟。 变量(数据)引用的动态重定位一般在装载时一次性完成,不会延迟绑定。通过
dlopen()也能强制“立即(NOW)”或“延迟(LAZY)”解析,但“延迟”只适用于函数。
大多数系统/构建默认启用懒绑定(除非显式要求“立即绑定”)。可以用环境变量 LD_BIND_NOW=1 或链接选项 -Wl,-z,now 禁用懒绑定,改为装载时就解析全部外部函数。
与 RELRO 的关系:
Partial RELRO:仅将一部分动态链接数据区标记为只读,保留
.got.plt可写以支持懒绑定。Full RELRO:要求在进入
main前全部解析函数符号并把 GOT(含.got.plt)设为只读,这就事实上禁用了延迟绑定(等价于-z now)。代价是启动时多做一点工作,换来运行期更强的防篡改性。当然特殊情况也有在开启 FULL RELRO 的时候进行重定位,比如 ret2dlresolve 。
我们以调用 puts 函数为例讲解一下延迟绑定的过程。
首先第一次调用 puts 时由于 puts@got 没有进行重定位,因此会调用 _dl_runtime_resolve 函数进行重定位,_dl_runtime_resolve 函数将查找到的 puts 函数地址填写到 puts@got 后会调用 puts 函数。
**第一次调用 puts**(尚未解析):
调用点发出
call puts@PLT,跳到该函数的 PLT 入口(每个外部函数有自己的pltN)。进入
puts@plt后(典型两段式):1
2
3
4
5
6
7
8
9
10
11; --- 通用 PLT0 桩 ---
plt0:
push qword ptr [rip + .got.plt + 8] ; = .got.plt[1] => link_map
jmp qword ptr [rip + .got.plt + 16] ; = .got.plt[2] => 解析器入口
; --- 单个函数的专属 PLT 桩(俗称 pltN)---
; label: puts@plt
puts@plt:
jmp qword ptr [rip + puts@GOTPLT] ; 已解析:直接跳真实 puts
push dword ptr idx_puts ; 首调:压入 .rela.plt 的表项序号
jmp plt0 ; 进入通用桩由于
puts@GOTPLT被初始化成指回本桩的第二条指令(也可理解为“一个 PLT 局部小跳板”)。因此第 ① 步并不会离开本桩,而是落到后面的push $idx。这个idx就是该函数在.rela.plt里的表项序号。PLT0 从 GOT 中取到当前模块的
link_map,再跳转到运行时解析器(dl_runtime_resolve族)入口。.got.plt(函数用 GOT)前 3 个条目是保留位,后续每个条目对应一个可延迟解析的函数。
.got.plt[0]→_DYNAMIC的链接时地址
给动态链接器(ld.so)做“自举/定位”的锚点:它能让 ld.so 通过_DYNAMIC找到该对象的.dynamic段,进而读到DT_PLTGOT、DT_JMPREL、DT_SYMTAB、DT_STRTAB等指针,用来完成 PLT/GOT 的修补、符号解析等工作。这个槽不直接参与一次函数调用的跳转,但对装载期和解析期的元数据定位很重要。.got.plt[1]→ 当前对象的“描述符”(link_map指针)
这是传给解析桩的第一个参数。首调时,PLT 桩会把.got.plt[1]压栈/放寄存器,ld.so 由此拿到当前 ELF 对象的 **link_map**,再根据link_map->l_info[DT_*]找到.rela.plt/.rel.plt、.dynsym、.dynstr等表去解析符号、写回真实地址。.got.plt[2]→ 解析器入口(resolver trampoline)
这是 PLT0 要jmp去的目标(也就是_dl_runtime_resolve的汇编桩入口;在 glibc 上常见别名如_dl_runtime_resolve_xsave[_c])。PLT0 把上一步准备好的参数(link_map+ 重定位索引)“交给”这个解析桩,解析桩再调用 C 例程_dl_fixup完成R_X86_64_JUMP_SLOT的解析与回填.got.plt[n],并尾调用到真实函数。
解析器依据
link_map查.dynsym/.dynstr和 **.rela.plt**(注意:x86‑64 使用Elf64_Rela,即 RELA 形式),通过重定位条目的r_info找到目标符号,按动态链接的搜索顺序解析出真实地址。解析器把真实地址写回该函数的 GOT 槽(
.got.plt的对应项),随后跳转到puts真身继续执行。
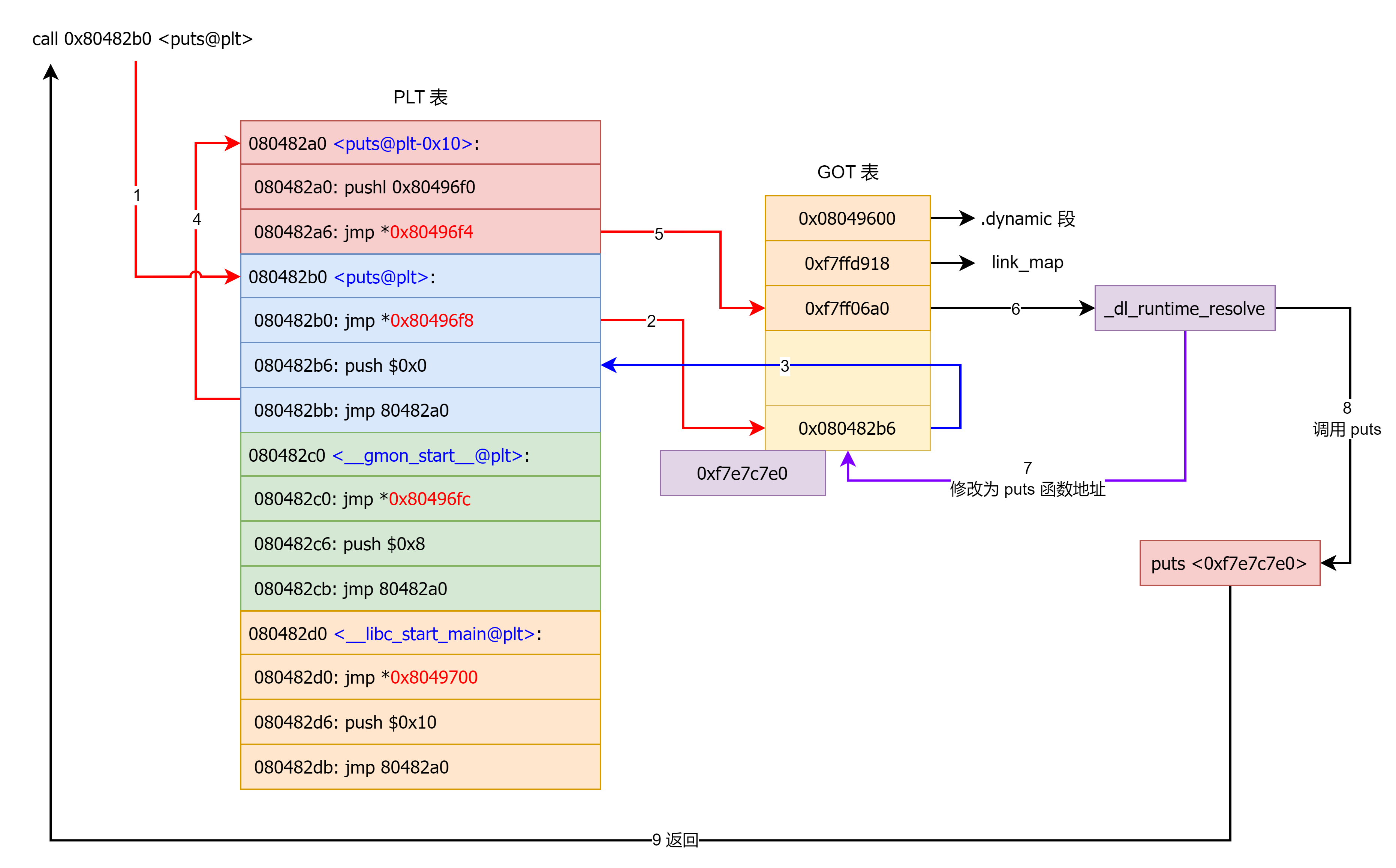
再次调用 puts,puts@PLT 直接从 puts@GOTPLT 读取已解析好的函数地址并跳转,不再进入解析器,因此热路径只有一次间接跳转开销。
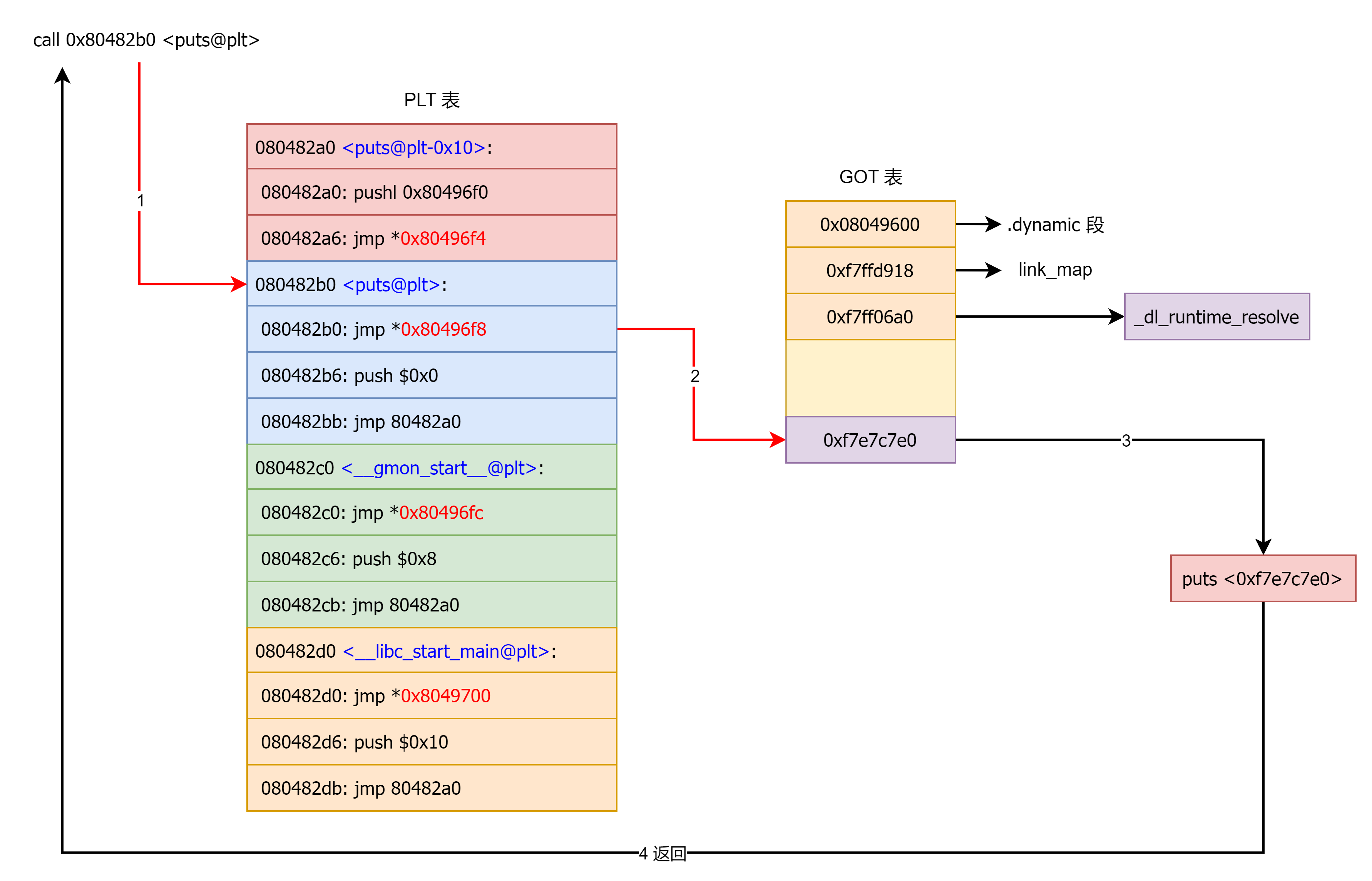
其中在第一次调用 puts 函数时调用的 _dl_runtime_resolve 函数的具体实现为:
- 用第一个参数
link_map访问.dynamic,取出.dynstr,.dynsym,.rel.plt的指针。 .rel.plt + 第二个参数求出当前函数的重定位表项Elf32_Rel的指针,记作rel。rel->r_info >> 8作为.dynsym的下标,求出当前函数的符号表项Elf32_Sym的指针,记作sym。.dynstr + sym->st_name得出符号名字符串指针。- 在动态链接库查找这个函数的地址,并且把地址赋值给
*rel->r_offset,即 GOT 表。 - 调用这个函数。
把
puts@GOTPLT改成指向printf@plt的第二条指令(也就是它的push idx_printf):
- 调用
puts@PLT→ 第一条jmp [rip+puts@GOTPLT]会跳到printf@plt的 fallback。printf@plt的 fallback 会push idx_printf; jmp plt0,于是解析器拿到的idx是printf的。_dl_fixup解析printf,并把真实printf地址写回.rela.plt[idx_printf].r_offset指向的槽(即 **printf@GOTPLT)——不是puts@GOTPLT**。- 你的
puts@GOTPLT仍然指向printf@plt的 fallback;以后每次puts@PLT都会“借道 printf 的 fallback”,解析器会很快认出已解析过,再尾调用真实printf。结论:这种劫持让
puts()实际上调用了printf(),且解析器修改的是printf的 GOT 槽,与“你最初跳出来的那个 GOT 槽”无关。
动态链接的步骤和实现
动态链接器自举
在 ELF 格式的程序中,如果启用了动态链接(即不是 -static 编译),那么程序的启动流程会先进入动态链接器(如 64 位系统上的 /lib64/ld-linux-x86-64.so.2)。但由于动态链接器本身也是一个 ELF 可执行体,它也有重定位需求,必须先完成自我重定位才能开始为主程序服务,这一过程称为自举(Bootstrap)。
动态链接器的入口地址就是自举代码的起点,当内核将控制权交给动态链接器时,它会执行如下步骤:
- 读取自己的 GOT 表,通常通过
.got.plt区段定位。 - GOT 的第一个表项通常保存
.dynamic段的偏移,由此定位到.dynamic。 - 从
.dynamic段中解析出链接器自身的重定位表、符号表、字符串表等信息。 - 使用这些表项,对链接器自身的重定位表进行修复(如
R_*_RELATIVE条目),完成自身地址修正。
只有完成这些步骤后,链接器本身的全局变量、函数指针、跳转表等才能正常使用。这也意味着:动态链接器前半段的代码几乎不依赖任何已初始化的全局数据区,只能使用硬编码和偏移量操作。
装载共享对象
完成自举后,链接器会开始处理主程序(即用户编写的可执行文件)的依赖项。
- 合并全局符号表
链接器将主程序与链接器自身的符号表合并为一个全局符号表,供后续查找使用。 - 解析 DT_NEEDED
主程序的.dynamic段中包含多个DT_NEEDED项,每个表示一个需要加载的共享对象(动态库)。 - 构建装载集合
链接器将所有DT_NEEDED项依次加入待装载队列,并按一定顺序加载这些库。这个过程可以类比为对 ELF 依赖图的遍历,glibc 中使用的是广度优先遍历(BFS),可以避免较深的递归加载导致顺序不一致。 - 递归解析依赖
如果某个库又依赖其他共享对象(即它自身也有DT_NEEDED),链接器将其依赖也加入集合中,直到整个依赖树完全加载。 - 映射 ELF 文件
每个共享对象被打开后,链接器读取其 ELF 头部、程序头表(Program Header Table),将其.text、.data、.rodata等段通过mmap映射到进程地址空间中。
重定位和初始化
共享对象装载完成后,链接器执行重定位操作,将指针类符号修正为实际加载地址。这包括 .got、.got.plt、全局变量等。常见重定位类型(以 x86 为例)有:
R_386_RELATIVE:重定位静态地址引用,如static int *p = &a;R_386_GLOB_DAT:全局变量地址写入.got表R_386_JUMP_SLOT:函数符号重定位,写入.got.plt,用于延迟绑定
为了提高程序启动速度,PLT(Procedure Linkage Table)+ GOT 机制支持懒绑定:首次调用外部函数时,PLT 入口跳转至 _dl_runtime_resolve,动态链接器在该函数中完成真正地址解析并修复 .got.plt 表项。
可通过环境变量 LD_BIND_NOW=1 禁用懒绑定,强制所有 JUMP_SLOT 重定位在程序启动时立即完成。
执行构造函数
重定位完成后,链接器将调用每个共享对象中注册的初始化函数:
.init_array:现代构造函数表,按数组顺序依次调用,优先使用。.init:旧式单入口构造函数(被_init调用)。.ctors:废弃机制,仅供兼容。
这些构造函数用于初始化 C++ 的全局对象、线程局部变量、资源连接等。
注意
**动态链接器不会主动执行主程序的 .init 和 .init_array**,这部分由程序自己的入口代码(通常是 __libc_csu_init)负责调用。
当所有依赖库装载完毕、重定位完成、构造函数执行完毕之后,动态链接器的工作完成,它将控制权移交给主程序入口,即 ELF 文件头 e_entry 指定的位置。在 glibc 中,这个流程是:
1 | _start |
至此,用户代码才真正开始执行。
提示
当程序执行结束时,还会依次执行 .fini_array、.fini 中注册的析构函数,以销毁全局对象、关闭连接、释放资源等。
动态链接器也会负责调用所有共享对象的 .fini_array,而主程序自身的 .fini_array 同样由 __libc_csu_fini 负责。
装载
在 Linux 中,装载(load/load in memory)指的是操作系统内核将一个 ELF 可执行文件从磁盘读取出来,并将其内容映射到进程的虚拟地址空间中,准备好让 CPU 可以从它的入口点开始执行的整个过程。
装载的本质是:内核清空当前进程的用户空间 → 加载新程序 → 设置入口 → 开始执行。
1 | 用户命令 → shell 调用 fork → 子进程调用 execve |
从 shell 到 execve
当我们在 shell 中执行一条命令时,实际上发生了以下流程:
bash进程调用fork()创建一个子进程;- 子进程调用
execve()执行新的 ELF 可执行程序; - 父进程继续执行,等待子进程结束。
其中 execve() 是 Linux 中非常核心的一个系统调用,简单来说,**execve() 就是“让当前进程去运行另一个程序”。**该函数原型如下:
1 | int execve(const char *pathname, char *const argv[], char *const envp[]); |
pathname:要执行的程序路径(可以是 ELF 文件、脚本等)argv[]:参数列表(传给main(int argc, char *argv[]))envp[]:环境变量列表
另外 glibc 提供了多个 exec 族 API(如 execl, execvp, execvpe 等)对其封装,最终都调用 execve()。
| 函数名 | 参数形式 | 是否查 PATH | 是否自带 envp | 调用示例 |
|---|---|---|---|---|
execl |
列表 | ❌ 否 | ❌ 否 | execl("/bin/ls", "ls", NULL); |
execlp |
列表 | ✅ 是 | ❌ 否 | execlp("ls", "ls", NULL); |
execle |
列表 + envp | ❌ 否 | ✅ 是 | execle("/bin/ls", "ls", NULL, envp); |
execv |
数组 argv[] |
❌ 否 | ❌ 否 | execv("/bin/ls", argv); |
execvp |
数组 argv[] |
✅ 是 | ❌ 否 | execvp("ls", argv); |
execvpe |
数组 + envp | ✅ 是 | ✅ 是 | execvpe("ls", argv, envp); |
提示
参数形式指的是怎么把参数(
argv)传给要执行的程序。- 列表形式指的是一个一个地写参数(就是函数的变长参数)。例如
execl:
1
execl("/bin/ls", "ls", "-l", "/tmp", NULL);
这种形式里,函数的参数是分开的,最终内部会构造出一个
argv[]数组:1
char *argv[] = {"ls", "-l", "/tmp", NULL};
数组形式指的是需要自己先准备好一个
argv[]数组,把它直接传进去:1
2char *argv[] = {"ls", "-l", "/tmp", NULL};
execv("/bin/ls", argv);
- 列表形式指的是一个一个地写参数(就是函数的变长参数)。例如
是否查
PATH指的是系统要不要自动去$PATH环境变量指定的目录中查找可执行文件的位置。1
2
3execlp("ls", "ls", NULL); // ✅ 查 PATH,会找到 /bin/ls 或 /usr/bin/ls
execl("/bin/ls", "ls", NULL); // ❌ 不查 PATH,需要你手动给出完整路径在 Linux 中,环境变量
PATH是一串目录组成的列表,比如:1
2echo $PATH
# /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin当你调用
execvp("ls", argv)时,它会依次在这些目录中查找有没有可执行文件叫"ls",直到找到为止。- 如果找到了,比如
/bin/ls,就用它去执行; - 如果没找到,就报错
ENOENT。
- 如果找到了,比如
是否自带
envp这个函数是否支持你传入自定义envp(不然只能用默认的)。envp是环境变量数组,是一个char *envp[]类型,例如:1
char *envp[] = {"PATH=/bin:/usr/bin", "USER=sky123", NULL};
- 如果函数 没有
envp参数,那就只能自动使用当前进程的环境变量(通过全局变量environ获取); - 如果函数 有
envp参数(比如execle,execvpe),你可以自己传一组新的环境变量数组,用于改变目标程序执行时的环境。
- 如果函数 没有
下面是一个简易的 bash 程序实现:
1 |
|
execve 的内核的实现
execve() 是 Linux 中最核心的“程序执行”系统调用。它会将当前进程的用户态空间完全清空,然后加载新的 ELF 程序及其依赖库,并最终跳转到新程序入口点执行。
execve 整体的系统调用流程如下:
1 | glibc // 用户态 C 库;调用 exec 系列 API |
简单来说 execve 的执行逻辑就是就是判断可执行文件的魔数然后调用对应的回调函数加载执行可执行文件。
魔数(Magic Number) 指文件头部的一段固定字节序列,用来快速标识文件类型或版本。它是“文件格式的身份证”,让操作系统或应用程序无需解析整个文件即可知道该用哪种解析/加载器处理。
例如在类 UNIX 操作系统中,文件头以
#!(称为 Shebang)开头,是专门用于标识“这是一个脚本文件”及其对应解释器路径的魔数格式。而对于 ELF 格式的可执行文件,其魔数是:
\x7FELF。
对于可执行文件,在 fs/binfmt_elf.c 中定义了加载执行该类型文件的回调函数 load_elf_binary。
1 | static struct linux_binfmt elf_format = { |
load_elf_binary() 是 Linux 内核真正把 ELF 映像搬进新进程地址空间并把 CPU 跳到入口地址的函数,该函数的主要逻辑为:
- 验证 ELF 头
- 检查魔数
\x7FELF、位宽、字节序、e_type(ET_EXEC/ET_DYN)。 - 读取并验证 Program‑Header Table 数量与大小。
- 检查魔数
- 查找
.interp段(如有)- 若存在
PT_INTERP,读出动态链接器路径/lib*/ld-linux*.so.*。 - 打开链接器文件,为后续映射做准备。
- 若存在
- 加载 Program‑Header
PT_LOAD段- 逐段
mmap.text/.rodata/.data/.bss等到进程地址空间; - 计算
load_bias(PIE 随机基址)并更新start_code/end_code等 mm 统计字段; - 为
.bss/heap 调用set_brk()分配零页。
- 逐段
- 设置栈与辅助向量 (
setup_arg_pages()→create_elf_tables())- 把
argv[]、envp[]、auxv[]拷到新栈; - 在 auxv 填入
AT_PHDR,AT_ENTRY,AT_BASE,AT_RANDOM等,供链接器/程序读取。
- 把
- 加载并映射动态链接器(若存在)
load_elf_interp()把ld.so自身映射进地址空间;- 记录其加载基址,用作
AT_BASE及后续重定位。
- 切换到新进程映像
flush_old_exec()→ 清掉旧 mm;install_exec_creds()→ 安装新 UID/GID/LSM 凭据;- 随机化栈 / brk(若启用 ASLR)。
- 确定入口地址并启动线程
- 静态 ELF:入口 =
e_entry + load_bias; - **动态 ELF (PIE)**:入口 = 链接器入口;链接器完成重定位后再跳到主程序
_start; start_thread(regs, elf_entry, stack_top)把rip/eip指向入口并返回用户态。
- 静态 ELF:入口 =
一旦 start_thread() 返回到用户空间,CPU 已在 新程序入口 指令处运行;自此,旧进程代码与所有旧 .so 全部被替换。
进程虚拟地址空间
在现代操作系统中,每个进程都运行在自己的虚拟地址空间(Virtual Address Space)中。所谓虚拟地址空间,是操作系统提供给进程的一种抽象地址空间:
- 每个进程拥有独立的地址空间,互相隔离。
- 虚拟地址空间由连续的虚拟地址构成,而不是物理地址。
- 操作系统通过内存管理单元(MMU)将虚拟地址翻译为实际的物理地址。
虚拟地址空间让进程以为自己独占内存空间,简化了程序设计,并提高了系统的安全性和稳定性。
通常来说,一个进程(关闭 PIE 且动态链接)的进程空间布局如下:
1 | 0x0000_0000_0000 ── NULL page (不可访问,解引用触发 SIGSEGV) |
其中常见的段含义如下:
| 区域 / 段 | 典型权限 | 详细说明 |
|---|---|---|
.text |
R‑X |
- 代码段(text segment),包含可执行的 机器指令。- 在可执行文件中,此段往往是只读 + 可执行,避免被恶意篡改。- 如果启用了 NX(No-eXecute)保护,除了此段外,其他内存区域将被禁止执行(W^X 策略)。 |
.rodata |
R-- |
- Read-Only Data 段。- 存放 字符串常量、const 修饰的全局变量、C++ 的 虚表(vtable) 等。- 映射为只读,防止运行期间被意外或恶意修改。 |
.data |
RW- |
- 已初始化的全局变量、静态变量(.data段)。- 例如:int x = 42; 会被存入此区域。 |
.bss |
RW- |
- Block Started by Symbol(BSS 段),用于未初始化的全局 / 静态变量。- 比如:int y; 会占据此段空间。- 在加载时由内核自动用 0 填充,不会占用磁盘文件空间(仅占内存页)。 |
.got / .plt |
.got: RW-``.plt: R‑X |
- GOT(Global Offset Table) 保存运行时解析出的函数 / 全局变量地址。- PLT(Procedure Linkage Table) 是延迟绑定跳板,调用函数时会跳到 .plt 中间接跳转到实际地址。- 两者配合实现 dlopen() 和延迟绑定机制。 |
.dynamic |
R-- |
- 存放动态链接信息,如:符号表、重定位表偏移、需要的共享库名等。- 程序启动时由动态链接器(如 ld-linux.so)读取并处理。 |
.init_array / .fini_array |
RW- |
- 分别用于 C/C++ 程序的构造函数(初始化)和析构函数(结束)列表。- 编译器将 __attribute__((constructor)) 或全局对象构造函数地址放入 .init_array,在启动时自动调用。 |
| Heap(堆) | RW- |
- 程序通过 malloc() / new 等动态分配的内存区域。- 初始堆由 brk() 创建,超出部分通过 mmap() 生成匿名页。- 向高地址扩展。 |
| Stack(栈) | RW- |
- 包含函数调用栈帧、局部变量、返回地址等信息。- 默认 8MB 左右空间,可通过 ulimit -s 设置。- argv[], envp[], auxv[] 也在进程启动时由内核构造在此处。- 向低地址扩展;底部设置 guard page(不可访问)防溢出。 |
| vDSO / vvar | R-- |
- vDSO(Virtual Dynamic Shared Object)是内核映射到用户空间的共享库,提供 gettimeofday() 等系统调用的用户态实现,加快访问速度(免陷入内核)。- vvar 是 vDSO 访问的变量页,如时钟源信息。- cat /proc/self/maps 可见它们在栈附近。 |
| mmap() 区域 | R--/RW-/RWX 等 |
- 使用 mmap() 映射的所有区域:包括动态链接库(.so 文件)、匿名页、文件映射、JIT 编译代码区等。- 运行时由内核动态分配,段数量不定;常见于 JavaScript 引擎、Python、动态模块等。 |
运行
进程栈的初始化
我们知道进程刚开始启动的时候,须知道一些进程运行的环境,最基本的就是系统环境变量和进程的运行参数。很常见的一种做法是操作系统在进程启动前将这些信息提前保存到进程的虚拟空间的栈中。
假设我们运行如下命令,即运行 ls 程序,传入的参数为 /home 。
1 | ls /home |
在程序初始状态的栈如下图所示。
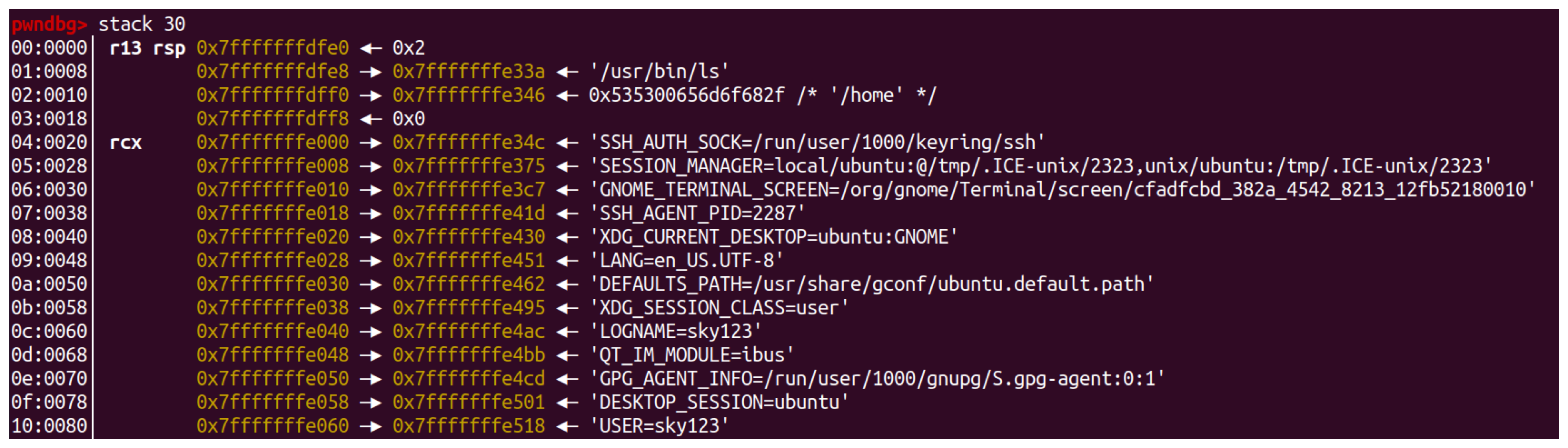
栈顶寄存器 rsp 指向的位置是初始化以后堆栈的顶部,最前面的 8 个字节表示命令行参数的数量,我们的例子里面是两个,即 /usr/bin/ls 和 /home ,紧接的就是分布指向这两个参数字符串的指针;后面跟了一个0;接着是一个以 0 结尾的指向环境变量字符串的指针数组。
 进程在启动以后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给 `main()` 函数,也就是我们熟知的 `main()` 函数的两个 `argc` 和 `argv` 两个参数,这两个参数分别对应这里的命令行参数数量和命令行参数字符串指针数组。
进程在启动以后,程序的库部分会把堆栈里的初始化信息中的参数信息传递给 `main()` 函数,也就是我们熟知的 `main()` 函数的两个 `argc` 和 `argv` 两个参数,这两个参数分别对应这里的命令行参数数量和命令行参数字符串指针数组。
main 函数之外的代码
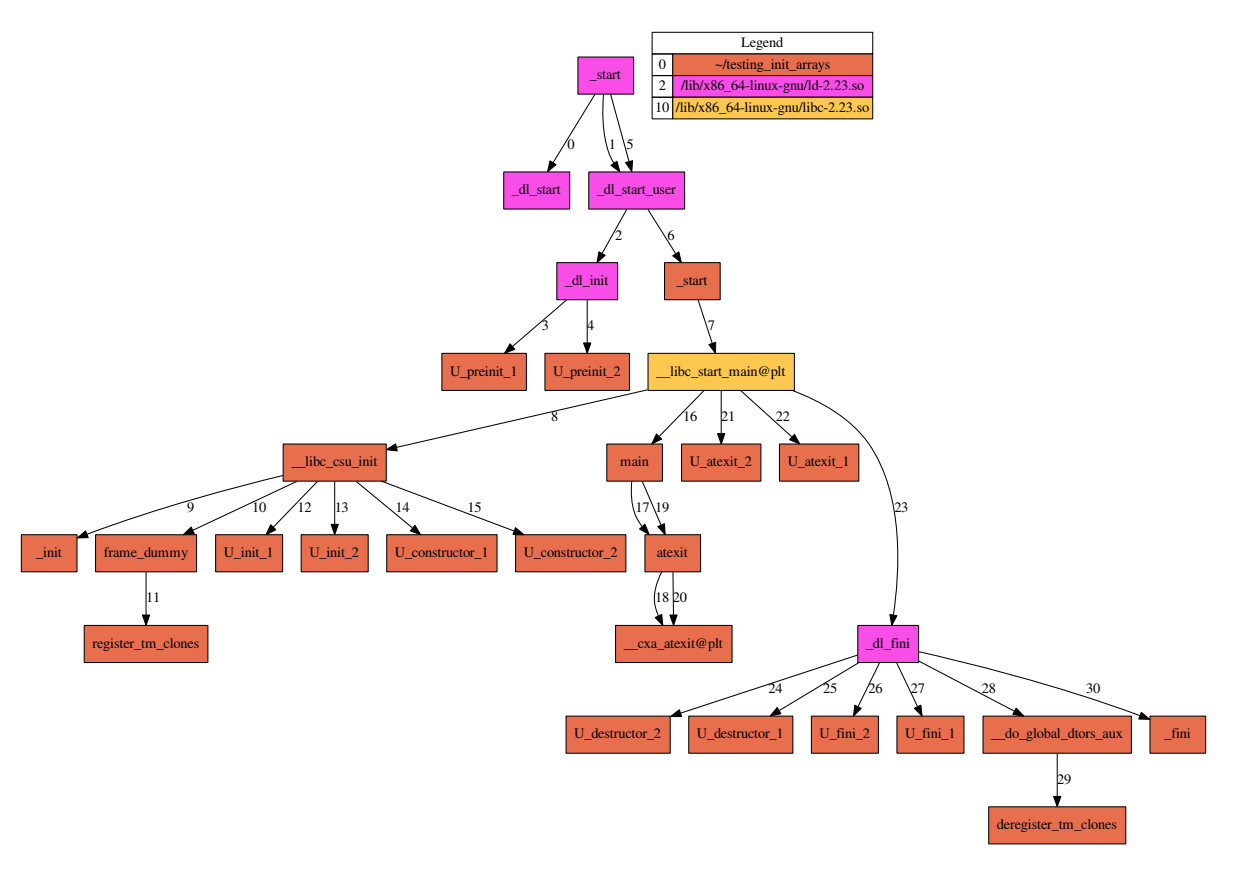
当运行程序时,shell 或 gui 调用 execve() ,它执行 linux 系统调用 execve() 设置一个堆栈,并将 argc 、 argv 和 envp 压入其中。文件描述 0、1 和 2(stdin 、stdout 、stderr)保留为 shell 设置的值,动态链接器完成重定位工作。当一切准备就绪后,通过调用 _start() 将控制权交给程序。
一般情况下 ELF 的入口点为 _start 函数,这个函数的主要作用是设置 ___libc_start_main 函数的所需参数。
1 | .text:08049080 endbr32 |
之后调用 __libc_start_main 函数,通过调试发现使用 glibc-2.23 的 32 位程序实际调用的是 generic_start_main 函数,该函数位于 csu/libc-start.c 中,定义如下:
1 |
|
可见和 _start 函数里的调用一致,一共有 7 个参数,其中 main 由第一个参数传入,紧接着是 argc 和 argv(这里称为 ubp_av ,因为其中还包含了环境变量表)。除了 main 的函数指针之外,外部还要传入 3 个函数指针,分别是:
init:main调用前的初始化工作,默认是__libc_csu_init函数指针。fini:main结束后的收尾工作,默认是__libc_csu_fini函数指针。rtld_fini:和动态加载有关的收尾工作,rtld是 runtime loader 的缩写。如果是动态链接程序默认是_dl_fini函数指针,如果是静态链接程序默认为 NULL 。
最后的 stack_end 标明了栈底的地址,即最高的栈地址。
首先初始化 __libc_multiple_libcs 为 0 之后 generic_start_main 会调用 __cxa_atexit 将 rtld_fini 注册为 main 函数结束后的回调函数。
1 | if (__glibc_likely (rtld_fini != NULL)) |
当然如果是静态链接程序还会做一些额外的初始化,在动态链接程序中这些初始化是在动态连接器中完成的。
- 如果是开启 PIE 的静态程序会调用
_dl_relocate_static_pie函数初始化link_map并且进行重定位。 - 初始化
__environ。 - 初始化
__libc_stack_end。 - 调用
dl_aux_init根据栈上的辅助信息数组做相关的初始化工作。 - 如果程序头表指针
dl_phdr没有初始化,就通过 ELF 文件头的e_phoff初始化dl_phdr(程序头表地址),通过e_phnum初始化dl_phnum(程序头表中的项数)。不过这个一般在上一步根据栈上的辅助信息数组做相关的初始化工作时就已经初始化过了。 - 调用
_libc_init_secure函数,如果_libc_enable_secure_decided不为 0 则初始化_libc_enable_secure为(__geteuid() != __getuid() || __getegid() != __getgid())。__geteuid() != __getuid():比较有效用户 ID(effective user ID)和实际用户 ID(real user ID)。如果它们不相等,表示当前进程以特权用户身份运行(比如以 root 用户权限运行)。__getegid() != __getgid():比较有效组 ID(effective group ID)和实际组 ID(real group ID)。如果它们不相等,表示当前进程以特权用户组身份运行。- 这段代码的目的是判断当前进程是否以特权用户或特权用户组身份运行。这在某些情况下可能需要采取不同的安全措施或限制特权操作。
- 调用
__tunables_init函数从环境变量中提取信息,并用于初始化可调节项列表,以便在程序运行时可以根据这些可调节项来进行相应的配置或调整。 - 使用
ARCH_INIT_CPU_FEATURES宏初始化 CPU 的相关参数到cpu_features类型的结构体_dl_x86_cpu_features中。 - 重定位代码中的绝对地址引用 。
- 调用
__libc_setup_tls函数初始化 tls 。 - 如果
__libc_multiple_libcs为 0 则调用DL_SYSDEP_OSCHECK宏来初始化dl_osversion为内核版本号。 - 调用
__pthread_initialize_minimal函数初始化线程库 。 - 初始化
__stack_chk_guard。 - 初始化
pointer_chk_guard。 - 调用
_libc_init_first函数初始化_libc_argc,_libc_argv和environ等。 - 调用
__cxa_atexit函数将fini注册为main函数结束后的回调函数 。
之后判断函数指针 init 是否为空,如果不为空则调用该函数指针,也就是 __libc_csu_init 函数。
__libc_csu_init 函数定义在 csu/elf-init.c 中,内容如下:
- 如果是静态链接程序会依次调用函数指针数组
__preinit_array_start中的所有函数。 - 调用
_init函数。 - 依次调用函数指针数组
__init_array_start(.init_array)中的所有函数。
1 | // 初始化函数,程序入口处由 _start 调用,用于执行构造函数数组中的内容 |
其中调用的 init 函数如下:
1 | .init:0000037C push ebx ; _init |
在静态链接程序中直接 mov eax, 0; test eax, eax; ,因此这个函数什么也不做。而动态链接程序中由于此时 __gmon_start___@got 为 NULL ,因此同样什么也不做。
从 __libc_csu_init 函数返回后会调用 main 函数和 exit 函数。
exit 中的 hook
exit 函数定义如下:
1 | //stdlib/exit.c |
首先 __call_tls_dtors 会被 exit 调用。
1 | // 调用并清理线程局部存储(TLS)析构函数链表中的函数 |
泄露 pointer_guard 后可以劫持 tls_dtor_list ,构造 dtor_list 结构体控制 rdi(obj 域)和 rdx(next 域),进而利用 setcontext 来劫持程序执行流程 。
1 | struct dtor_list { |
泄露 pointer_guard 后(如果该 glibc 版本加密了该函数指针)可以通过劫持 __exit_funcs 数组来获取控制流。
1 | // 遍历 __exit_funcs 链表,处理每一个注册的退出函数(如 _dl_fini) |
但这种方法只能控制 rsi 。
1 | struct exit_function { |
如果是动态链接程序 __run_exit_handlers 函数会调用 _dl_fini 函数。
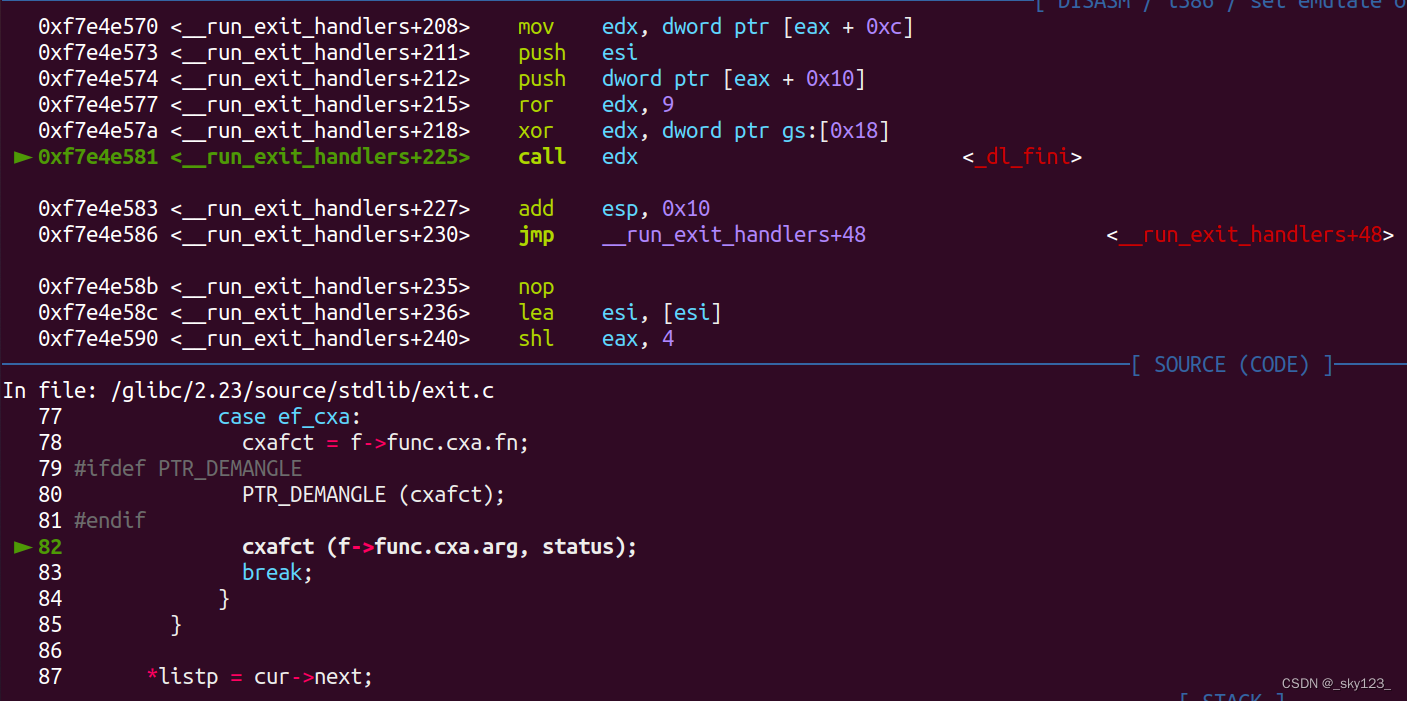
_dl_fini 函数定义如下,该函数的主要作用就是依次调用 link_map->l_info[DT_FINI_ARRAY] 中描述的函数数组中的函数指针。有一种攻击方法就是通过伪造 link_map 来实现控制流劫持,这种攻击方法叫做 House Of Banana 。
1 | //省略了有关SHARED的操作 |
另外 _dl_fini 中的 __rtld_lock_lock_recursive 和 __rtld_lock_unlock_recursive 宏展开后分别为 _rtld_local._dl_rtld_lock_recursive(&(_rtld_local._dl_load_lock).mutex) 和 _rtld_local._dl_rtld_unlock_recursive(&(_rtld_local._dl_load_lock).mutex) 因此我们可以劫持对应函数指针完成控制流劫持,这些函数指针就是狭义上的 exit hook 。
如果是静态链接程序 __run_exit_handlers 函数会调用 __libc_csu_fini 函数。__libc_csu_fini 函数会依次调用 .fini_array 中的函数指针,因此我们可以通过改写 .fini_array 实现控制流劫持。
1 | void |
之后调用 RUN_HOOK 宏:
1 | if (run_list_atexit) |
这个宏展开后的结果如下,可以看到这个宏会依次调用 __start___libc_atexit 函数指针数组直到遇到 NULL 。
1 | do { |
函数指针所在的内存在动态链接程序中位于 libc 上。
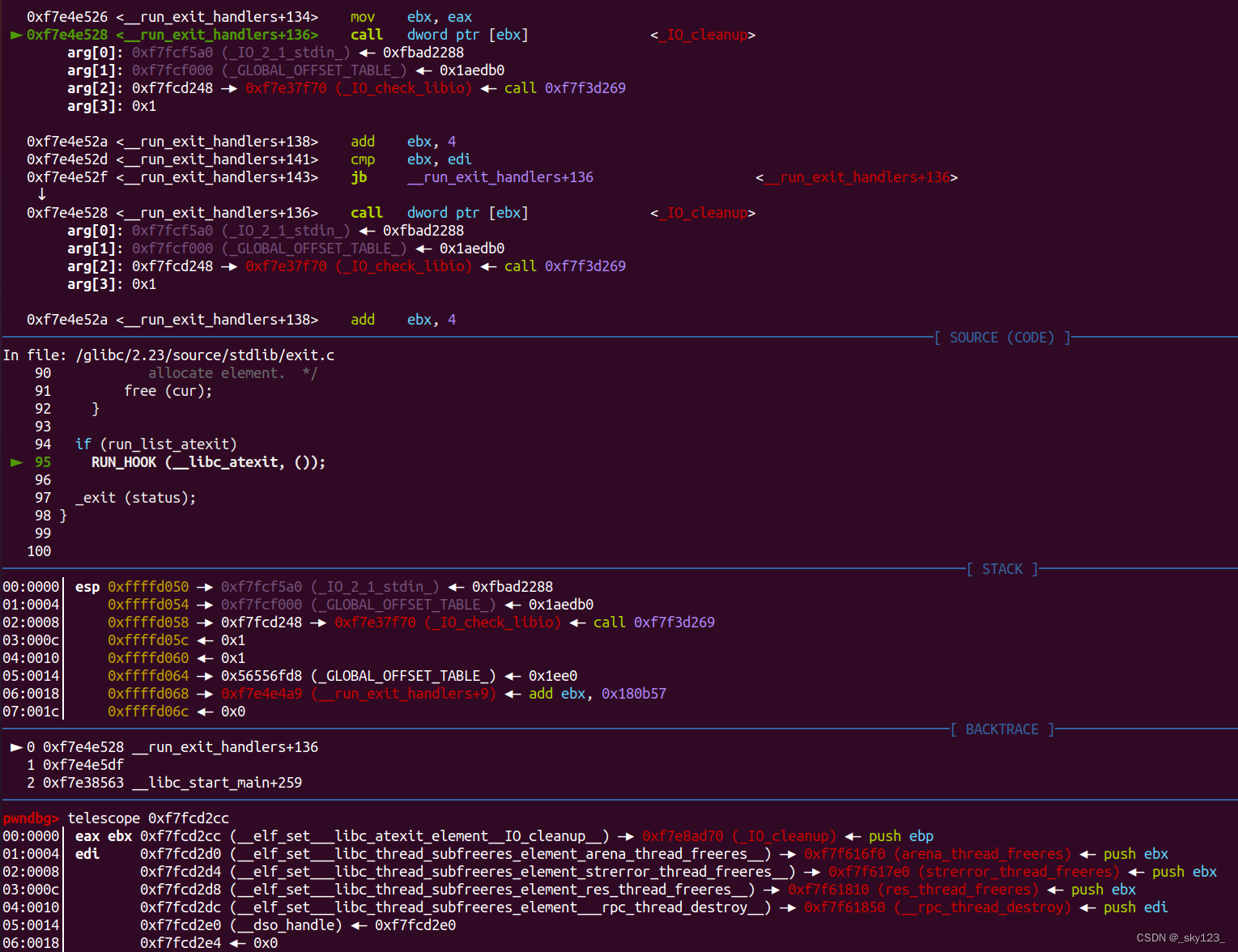
在静态链接程序中位于程序的 __libc_atexit 段。

用于 FSOP 的 _IO_cleanup 就是在这里被调用的,另外如果我们能控制这里的函数指针也可以劫持程序执行流程。
共享库
共享库版本
共享库版本命名
Linux有一套规则来命名系统中的每一个共享库,它规定共享库的文件名规则必须如下:
1 | libname.so.x.y.z |
最前面使用前缀 lib 、中间是库的名字和后缀 .so ,最后面跟着的是三个数字组成的版本号。x 表示主版本号(Major Version Number),y 表示次版本号(Minor Version Number),z 表示发布版本号(Release Version Number)。三个版本号的含义不一样。
- 主版本号表示库的重大升级,不同主版本号的库之间是不兼容的,依赖于旧的主版本号的程序需要改动相应的部分,并且重新编译,才可以在新版的共享库中运行;或者,系统必须保留旧版的共享库,使得那些依赖于旧版共享库的程序能够正常运行。
- 次版本号表示库的增量升级,即增加一些新的接口符号,且保持原来的符号不变。在主版本号相同的情况下,高的次版本号的库向后兼容低的次版本号的库。
- 发布版本号表示库的一些错误的修正、性能的改进等,并不添加任何新的接口,也不对接口进行更改。相同主版本号、次版本号的共享库,不同的发布版本号之间完全兼容,依赖于某个发布版本号的程序可以在任何一个其他发布版本号中正常运行,而无须做任何修改。
SO-NAME
系统普遍采用一种叫做 SO-NAME 的命名机制来记录共享库的依赖关系。每个共享库都有一个对应的 SO-NAME ,这个 SO-NAME 即共享库的文件名去掉次版本号和发布版本号,保留主版本号。比如一个共享库叫做 libfoo.so.2.6.1 ,那么它的 SO-NAME 即 libfoo.so.2 。很明显,SO-NAME 规定了共享库的接口,SO-NAME 的两个相同共享库,次版本号大的兼容次版本号小的。在 Linux 系统中,系统会为每个共享库在它所在的目录创建一个跟 SO-NAME 相同的并且指向它的软链接(Symbol Link)。比如系统中有存在一个共享库 /lib/libfoo.so.2.6.1 ,那么 Linux 中的共享库管理程序就会为它产生一个软链接 /lib/libfoo.so.2 指向它。比如 Linux 系统的 Glibc 共享库(注意稍高版本的 libc 的 libc.so.6 本身就是动态库,不是符号链接):
1 | $ ls -l /lib/x86_64-linux-gnu/libc.so.6 |
由于历史原因,动态链接器和 C 语言库的共享对象文件名规则不按 Linux 标准的共享库命名方法,但是 C 语言的 SO-NAME 还是按照正常的规则。
另外动态连接器的 SO-NAME 命名不按照普通的规则。
1 | $ ls -al /lib64/ld-linux-x86-64.so.2 |
建立以 SO-NAME 为名字的软链接目的是,使得所有依赖某个共享库的模块,在编译、链接和运行时,都使用共享库的 SO-NAME ,而不使用详细的版本号。
动态链接文件中的 .dynamic 段中的 DT_NEED 类型的字段就是 SO-NAME 而不是共享库的完整名字,这样当动态链接器进行共享库依赖文件查找时,就会根据系统中各种共享库目录中的SO-NAME软链接自动定向到最新版本的共享库。
当共享库进行升级的时候,如果只是进行增量升级,即保持主版本号不变,只改变次版本号或发布版本号,那么我们可以直接将新版的共享库替换掉旧版,并且修改 SO-NAME 的软链接指向新版本共享库,即可实现升级;当共享库的主版本号升级时,系统中就会存在多个 SO-NAME ,由于这些 SO-NAME 并不相同,所以已有的程序并不会受影响。
Linux 中提供了一个工具叫做 ldconfig ,当系统中安装或更新一个共享库时,就需要运行这个工具,它会遍历所有的默认共享库目录,比如 /lib 、/usr/lib 等,然后更新所有的软链接,使它们指向最新版的共享库;如果安装了新的共享库,那么 ldconfig 会为其创建相应的软链接。
符号版本
根据提到的可知,一个程序所依赖的共享库的次版本号如果高于系统中的共享库,那么就不保证该程序能在该系统中运行,这类问题叫做次版本号交会问题(Minor-revision Rendezvous Problem)。
这种次版本号交会问题并没有因为 SO-NAME 的存在而得到任何改善。对于这个问题,现代的系统通过一种更加精巧的方式来解决,那就是符号版本机制。这个方案的基本思路是让每个导出和导入的符号都有一个相关联的版本号,它的实际做法类似于名称修饰的方法。
.dynamic 段中的 DT_VERSYM 类型字段包含了符号版本。它的作用是维护库的版本信息,以便在运行时进行版本控制和符号解析。通过 DT_VERSYM ,动态链接器可以确定所链接的库的版本与运行时环境是否兼容,以及选择正确的版本来解析符号。

共享库系统路径
目前大多数包括 Linux 在内的开源操作系统都遵守一个叫做 FHS(File Hierarchy Standard)的标准,这个标准规定了一个系统中的系统文件应该如何存放,包括各个目录的结构、组织和作用,这有利于促进各个开源操作系统之间的兼容性。共享库作为系统中重要的文件,它们的存放方式也被 FHS 列入了规定范围。FHS 规定,一个系统中主要有两个存放共享库的位置,它们分别如下:
/lib:该目录包含操作系统核心组件所需的共享库文件。这些库文件通常是系统引导和运行时所必需的,例如与操作系统内核相关的库文件。/usr/lib:该目录包含操作系统提供的额外共享库文件。这些库文件用于支持系统上安装的应用程序和工具的运行,如图形界面工具包(GUI toolkit)、网络库、数据库驱动程序等。/usr/local/lib:该目录是用于安装本地(local)软件的库文件的默认位置。当用户手动编译和安装软件到系统时,通常会将其安装到/usr/local目录下。因此,相关的库文件也会被安装到/usr/local/lib目录下。
共享库查找过程
动态链接器对于模块的查找有一定的规则:如果 DT_NEED 里面保存的是绝对路径,那么动态链接器就按照这个路径去查找;如果 DT_NEED 里面保存的是相对路径,那么动态链接器会在 /lib 、/usr/lib 和由 /etc/ld.so.conf 配置文件指定的目录中查找共享库。为了程序的可移植性和兼容性,共享库的路径往往是相对的。
ld.so.conf 是一个文本配置文件,它可能包含其他的配置文件,这些配置文件中存放着目录信息。
1 | ➜ ~ cat /etc/ld.so.conf |
如果动态链接器在每次查找共享库时都去遍历这些目录,那将会非常耗费时间。所以 Linux 系统中都有一个叫做 ldconfig 的程序,这个程序的作用是为共享库目录下的各个共享库创建、删除或更新相应的 SO-NAME(即相应的符号链接),这样每个共享库的 SO-NAME 就能够指向正确的共享库文件;并且这个程序还会将这些 SO-NAME 收集起来,集中存放到 /etc/ld.so.cache 文件里面,并建立一个 SO-NAME 的缓存。当动态链接器要查找共享库时,它可以直接从 /etc/ld.so.cache 里面查找。而 /etc/ld.so.cache 的结构是经过特殊设计的,非常适合查找,所以这个设计大大加快了共享库的查找过程。
如果动态链接器在 /etc/ld.so.cache 里面没有找到所需要的共享库,那么它还会遍历 /lib 和 /usr/lib 这两个目录,如果还是没找到,就宣告失败。
所以理论上讲,如果我们在系统指定的共享库目录下添加、删除或更新任何一个共享库,或者我们更改了 /etc/ld.so.conf 的配置,都应该运行 ldconfig 这个程序,以便调整 SO-NAME 和 /etc/ld.so.cache 。很多软件包的安装程序在往系统里面安装共享库以后都会调用 ldconfig 。
更改共享库
Linux 系统提供了很多方法来改变动态链接器装载共享库路径的方法,通过使用这些方法,我们可以满足一些特殊的需求,比如共享库的调试和测试、应用程序级别的虚拟等。
LD_LIBRARY_PATH
在 Linux 系统中,LD_LIBRARY_PATH 是一个由若干个路径组成的环境变量,每个路径之间由冒号隔开。默认情况下, LD_LIBRARY_PATH 为空。如果我们为某个进程设置了 LD_LIBRARY_PATH ,那么进程在启动时,动态链接器在查找共享库时,会首先查找由 LD_LIBRARY_PATH 指定的目录。这个环境变量可以很方便地让我们测试新的共享库或使用非标准的共享库。
比如更换 libdl.so.2 和 libc.so.6 的 pwntools 脚本如下:
1 | sh = process("./lib/ld.so --preload libdl.so.2 ./pwnhub".split(), env={"LD_LIBRARY_PATH": "./lib/"}) |
LD_PRELOAD
系统中另外还有一个环境变量叫做 LD_PRELOAD ,这个文件中我们可以指定预先装载的一些共享库甚或是目标文件。在 LD_PRELOAD 里面指定的文件会在动态链接器按照固定规则搜索共享库之前装载,它比 LD_LIBRARY_PATH 里面所指定的目录中的共享库还要优先。无论程序是否依赖于它们,LD_PRELOAD 里面指定的共享库或目标文件都会被装载。
比如更换 libdl.so.2 和 libc.so.6 的 pwntools 脚本如下:
1 | process("./lib/ld.so ./pwnhub".split(), env={"LD_PRELOAD": "./lib/libc.so.6 ./lib/libdl.so.2"}) |
LD_DEBUG
另外还有一个非常有用的环境变量 LD_DEBUG ,这个变量可以打开动态链接器的调试功能,当我们设置这个变量时,动态链接器会在运行时打印出各种有用的信息,对于我们开发和调试共享库有很大的帮助。
例如运行 LD_DEBUG=files /bin/ls 命令时动态链接器打印出了整个装载过程,显示程序依赖于哪个共享库并且按照什么步骤装载和初始化,共享库装载时的地址等。
bindings:显示动态链接的符号绑定过程。libs:显示共享库的查找过程。versions:显示符号的版本依赖关系。reloc:显示重定位过程。symbols:显示符号表查找过程。statistics:显示动态链接过程中的各种统计信息。
patchelf
用于对于依赖不是很复杂的程序更换 libc ,有一下几点需要注意:
- 如果在漏洞利用时用到了动态链接相关结构最好不要 patchelf,因为 patchelf 会改变动态链接相关结构的位置。
- 一个程序在一个版本的虚拟机里面 patchelf 后换到另一个版本虚拟机中可能会运行失败。
- 在 patch 完 libc 后最好把 ld 也 patch 成大版本相同的 ld ,否则会运行失败。
修改 libc:
1 | patchelf --replace-needed libc.so.6 ./libc.so.6 ./pwn |
修改 ld:
1 | patchelf --set-interpreter ./ld-2.31.so ./pwn |
多线程与 TLS
基本概念
线程的访问非常自由,它可以访问进程内存里的所有数据,甚至包括其他线程的堆栈(如果它知道其他线程的堆栈地址,那么这就是很少见的情况),但实际运用中线程也拥有自己的私有存储空间,包括以下几方面:
- 栈(尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)。
- 线程局部存储(Thread Local Storage, TLS)。线程局部存储是某些操作系统为线程单独提供的私有空间,但通常只具有很有限的容量。
- 寄存器(包括PC寄存器),寄存器是执行流的基本数据,因此为线程私有。
实际上,线程私有的数据有:
- 局部变量
- 函数的参数
- TLS 数据
线程共享的数据有:
- 全局变量
- 堆上的数据
- 函数里的静态变量
- 程序代码,任何线程都有有权利读取并执行任何代码。
- 打开的文件,A 线程打开的文件可以由 B 线程读写。
一个全局变量如果使用 __thread 关键字修饰,那么这个变量就变成线程私有的 TLS 数据,也就是说每个线程都在自己所属 TLS 中单独保存一份这个变量的副本。例如下面的代码中,a 和 b 都是 TLS 数据,而 c 是全局变量。
1 | // gcc test.c -o test -g -pthread |
分析生成的 ELF 文件的节表,发现多出了 .tdata 和 .tbss ,这两个节分别记录已初始化和未初始化的 TLS 数据。
其中 .tbss 在 ELF 文件中不占用空间, .tdata 在 ELF 中存储了初始化的数据,比如上面的代码中的 __thread uint32_t a = 0x114514 。
ELF 加载到内存中后, .tdata 和 .tbss 这两个节合并为一个段,在程序头表中这个段的 p_type 为 PT_TLS(7) 。
TLS(Thread Local Storage)的结构与 TCB(Thread Control Block)以及 dtv(dynamic thread vector)密切相关,每一个线程中每一个使用了 TLS 功能的模块都拥有一个 TLS Block 。这几者的关系如下图所示:
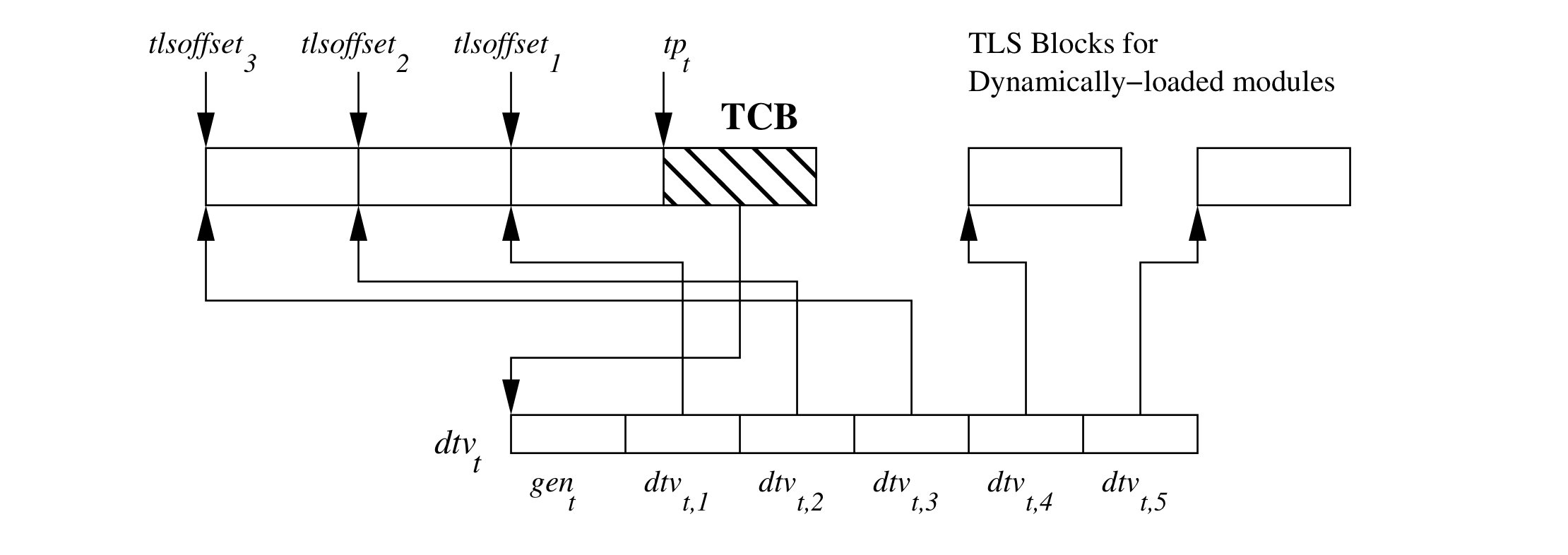
注意
这里是 x86_64-ABI 要求的 TLS 结构,Glibc 实现的 TLS 结构与上图有一些差异。
根据图中显示的信息,TLS Blocks 可以分为两类:
- 一类是程序装载时就已经存在的(位于 TCB 前),这一部分 Block 被称为
_static TLS_。 - 一类是右边的 Blocks 是动态分配的,它们被使用
dlopen函数在程序运行时动态装载的模块所使用。
TCB 作为线程控制块,保存着 dtv 数组的入口,dtv 数组中的每一项都是 TLS Block 的入口,它们是指向 TLS Blocks 的指针。特别的,dtv 数组的第一个成员是一个计数器,每当程序使用 dlopen 函数或者 dlfree 函数加载或者卸载一个具备 TLS 变量的模块,该计数器的值都会加一,从而保证程序内版本的一致性。 特别的,ELF 文件本身对应的 TLS Block 一定在 dtv 数组中占据索引为 1 的位置,且位置上与 TCB 相邻。 还需要注意的是,图中出现了一个名为 的指针,在 i386 架构上,这个指针为 gs 段寄存器;在 x86_64 架构上,该指针为 fs 段寄存器。由于该指针与 ELF 文件本身对应的 TLS Block 之间的偏移是固定的,程序在编译时就可以将 ELF 中线程变量的地址硬编码到目标文件中。
主线程 TLS 初始化
前面提到过在 main 开始前会调用 __libc_setup_tls 初始化 TLS 。
在 __libc_setup_tls 函数中,首先会遍历 ELF 的程序头表,找到 p_type 为 PT_TLS(7) 的段,这个段中就存储着 TLS 的初始化数据。
1 | /* Look through the TLS segment if there is any. */ |
然后通过 brk 调用为 TLS 中的数据以及一个 pthread 结构体分配内存。其中 pthread 结构体的第一项为 tcbhead_t header; ,即前面提到的 TCB 。
1 | /* Align the TCB offset to the maximum alignment, as |
tcbhead_t 结构体定义如下,也就是很多资料中提到的 TLS 。
1 | typedef struct |
之后初始化 _dl_static_dtv ,也就是前面提到的 dtv 数组,具体过程为:
- 将
tlsblock地址关于max_align向上对齐。 _dl_static_dtv[0].counter初始化为dtv的数量,由于_dl_static_dtv前两项分别用于记录dtv总数和使用的数量,因此这里记录的dtv数量是要减去这两项的。_dl_static_dtv[1].counter初始化为 0 。_dl_static_dtv[2]也就是当前模块对应的dtv的pointer.val指向 TLS 。_dl_static_dtv[2].pointer.to_free置为 NULL 。- 将 TLS 的初始数据也就是
PT_TLS段中的数据复制到 TLS 中。
1 | struct dtv_pointer |
此时 TLS 相关结构之间的关系如下图所示:
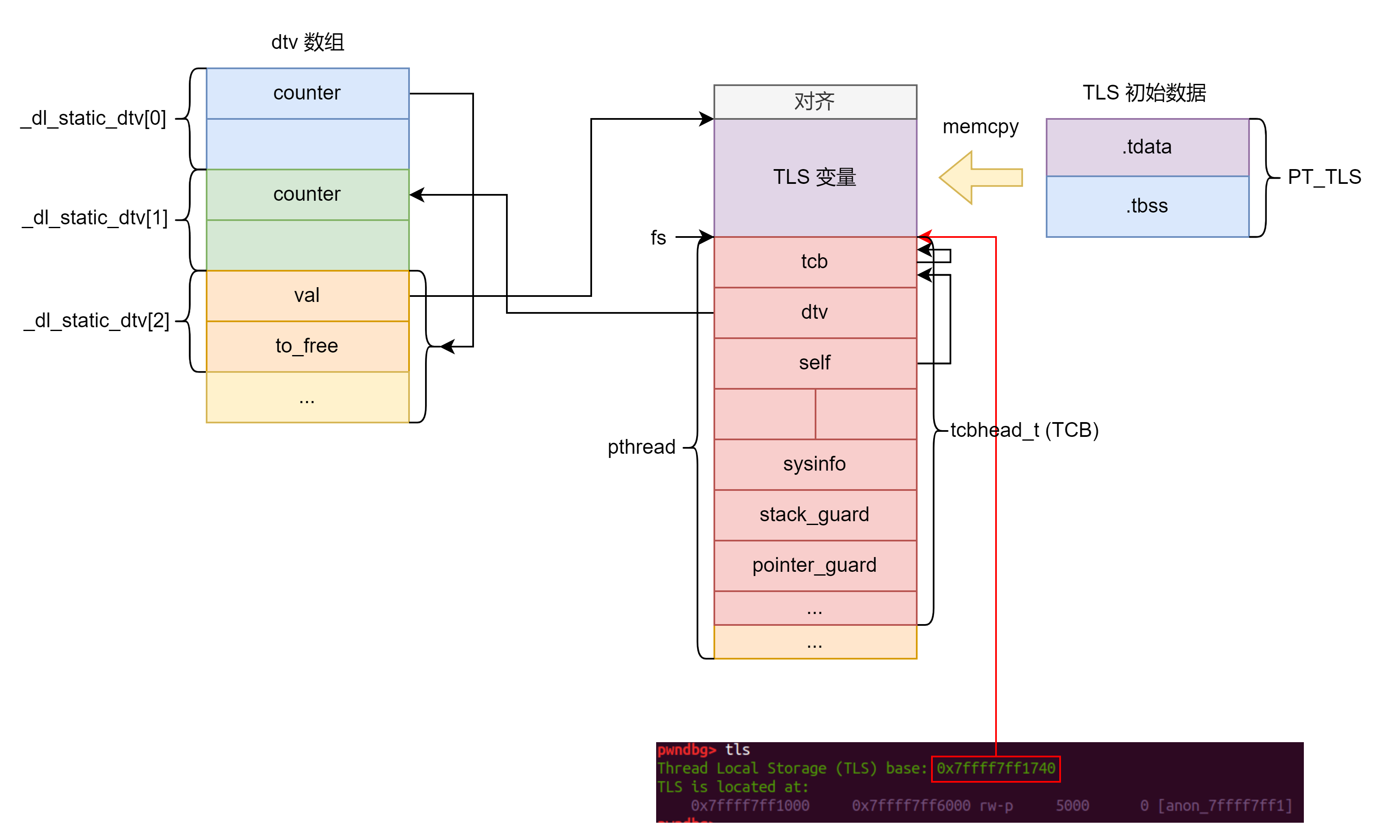
另外还会初始化 link_map 中的 TLS 相关的数据,由此我们可以知道 link_map 中这些字段的含义:
l_tls_offset:TCB 在 TLS 中的偏移。l_tls_align:TLS 初始数据的对齐,在 TLS 中 TLS 初始数据关于l_tls_align向上取整。l_tls_blocksize:TLS 初始数据的大小,也就是前面提到的 TLS Block 的大小。l_tls_initimage:TLS 初始数据的地址。也就是PT_TLS段的地址。l_tls_initimage_size:PT_TLS段在文件中的大小,也就是.tdata的大小。l_tls_modid:模块编号。
1 | struct link_map *main_map = GL(dl_ns)[LM_ID_BASE]._ns_loaded; |
创建线程时 TLS 初始化
创建线程的函数 pthread_create 实际调用的是 __pthread_create_2_1 函数,在该函数中调用了 allocate_stack 函数。
1 |
|
在 allocate_stack 函数中会调用 mmap 为线程分配栈空间,然后初始化栈底为一个 pthread 结构体并将指针 pd 指向该结构体。最后调用 _dl_allocate_tls 函数为 TCB 创建 dtv 数组。
1 | struct pthread *pd; |
_dl_allocate_tls 函数依次调用 allocate_dtv 和 _dl_allocate_tls_init 分配和初始化 dtv 数组。
1 | void * |
allocate_dtv 函数调用了 ptmalloc 堆管理器的 calloc 函数为 dtv 数组分配内存,初始化 dtv[0].counter 为数组中元素数量,并且让 pd->dtv 指向 dtv[1] 。
1 | /* Install the dtv pointer. The pointer passed is to the element with |
_dl_allocate_tls_init 函数会遍历 dl_tls_dtv_slotinfo_list 中的 link_map ,初始化 dtv 数组并将初始数据复制到 TLS 变量中。从这里可以看出,如果一个模块有 TLS 变量,则该模块对应的 dtv->pointer.val 指向 TLS 变量的起始地址。
1 | dtv[map->l_tls_modid].pointer.val = TLS_DTV_UNALLOCATED; |
回到 __pthread_create_2_1 函数,在完成了 pthread 的一系列初始化后调用了 THREAD_COPY_STACK_GUARD 和 THREAD_COPY_POINTER_GUARD 两个宏,这两个宏的展开如下:
1 | ((pd)->header.stack_guard = ({ |
不难看出这两个宏把当前线程(当前 fs 寄存器还没有指向新线程的 TCB)的 TLS 中的 stack_guard 和 pointer_guard 都复制到子线程的 TLS 的对应位置上。因此可以确定线程的 stack_guard 和 pointer_guard 与主线程相同。
最后需要确定是 fs 寄存器何时被修改,因为 fs 寄存器不能再用户态修改,因此一定是一个系统调用完成了对 fs 寄存器的修改。
通过调试发现,pthread_create->create_thread->clone 中的 clone 系统调用完成了对 fs 寄存器的修改。
子进程调试
gdb默认情况下,父进程 fork 一个子进程,gdb 只会继续调试父进程而不会管子进程的运行(pwndbg 插件设置相反)。
相关设置
- 跟踪子进程进行调试,可以使用
set follow-fork-mode mode来设置fork跟随模式。show follow-fork-mode:进入 gdb 以后,我们可以使用show follow-fork-mode来查看目前的跟踪模式。set follow-fork-mode parent:gdb 只跟踪父进程,不跟踪子进程,这是默认的模式。set follow-fork-mode child:gdb 在子进程产生以后只跟踪子进程,放弃对父进程的跟踪。
- 想同时调试父进程和子进程,以上的方法就不能满足了。Linux 提供了
set detach-on-fork mode命令来供我们使用。show detach-on-fork:show detach-on-fork显示了目前是的detach-on-fork模式。set detach-on-fork on:只调试父进程或子进程的其中一个(根据follow-fork-mode来决定),这是默认的模式。set detach-on-fork off:父子进程都在 gdb 的控制之下,其中一个进程正常调试(根据follow-fork-mode来决定),另一个进程会被设置为暂停状态。
调试进程切换
使用 gdb 调试多进程时,如果想要在进程间进行切换,那么就需要
- 在
fork调用前设置:set detach-on-fork off。 - 使用
info inferiors来查看进程信息,得到的信息可以看到最前面有一个进程编号,使用inferior num来进行进程切换。
常见保护
checksec 可以查看程序开启了哪些保护。
1 | ➜ ~ checksec /bin/ls |
Canary
canary 是一种防止缓冲区溢出攻击的保护机制。它的基本思想是在程序的堆栈中插入一个随机生成的数值,用于检测缓冲区溢出攻击。
1 | .text:0000000000001189 endbr64 |
canary 的初始值存储在 tls 中,也就是前面提到的 stack_guard 。
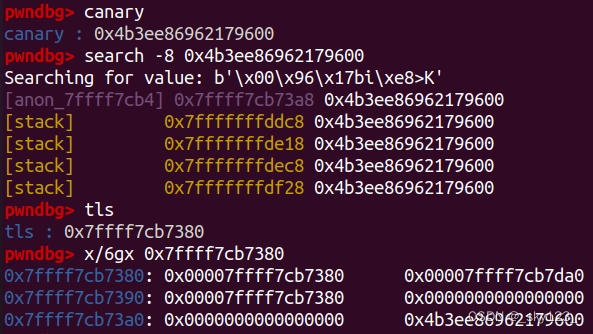
在编译 c 程序时使用 -fno-stack-protector 参数可以关闭 canary 保护(注意高版本的 gcc 的 canary 保护关不掉)。
NX
NX 即 No-eXecute(不可执行),NX 的基本原理是将数据所在内存页标识为不可执行,也就是同一内存可写与可执行不共存。
gcc 编译器默认开启了 NX 选项,如果需要关闭 NX 选项,可以给 gcc 编译器添加 -zexecstack 参数。
PIE
PIE 主要随机了代码段(.text),初始化数据段(.data)和未初始化数据段(.bss)的地址。另外 PIE 是否开启还会影响堆的基址。
开启 PIE:
关闭 PIE:
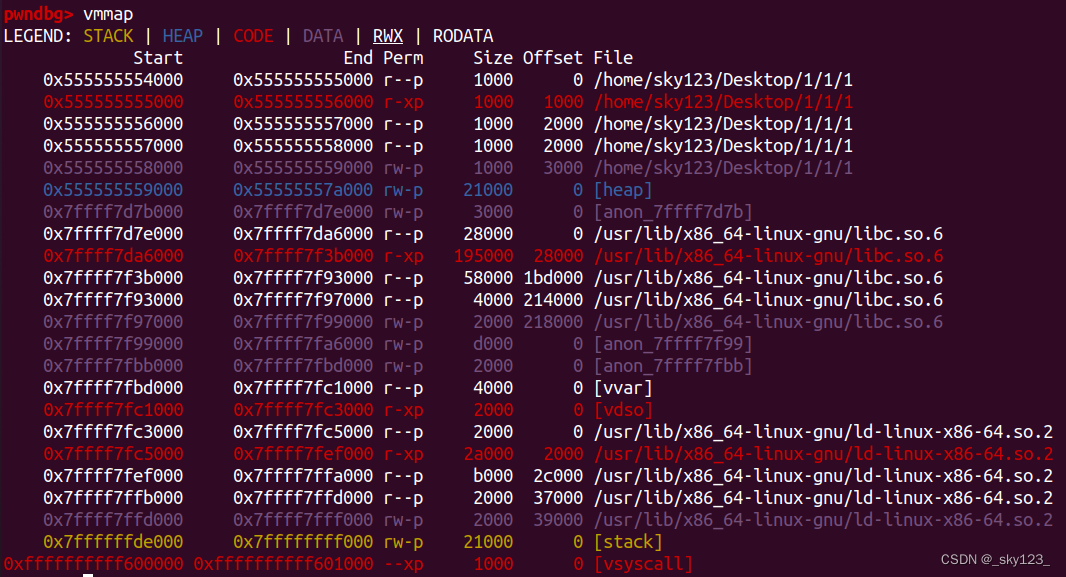
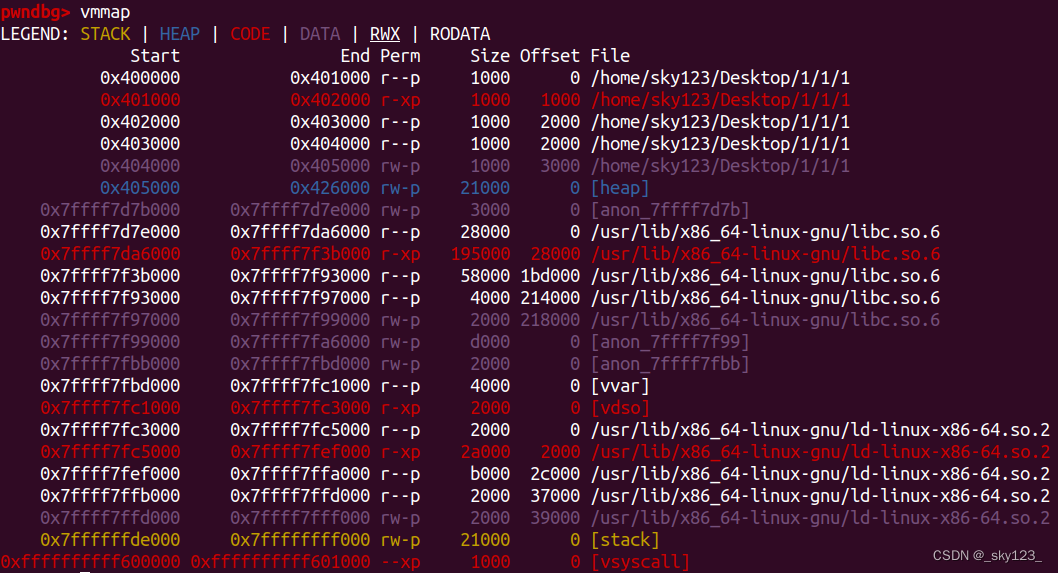
在编译 c 程序时使用 -no-pie 参数可以关闭 PIE 保护。
ASLR
ASLR 是系统级别的地址随机。通过修改 /proc/sys/kernel/randomize_va_space 的值可以控制 ASLR 的级别:
- 0:关闭 ASLR
- 1:栈基址,共享库,mmap 基址随机
- 2:在 1 的基础上增加堆基址的随机
RELRO
- 当 RELRO 保护为 NO RELRO 的时候,
init.array、fini.array、got.plt均可读可写。 - 为 PARTIAL RELRO 的时候,
init.array、fini.array根据实际调试结果判断是否可写,got.plt可读可写。 - 为 FULL RELRO 时,
init.array、fini.array、got.plt均可读不可写。 -Wl,-z,norelro编译参数可以关闭 RELRO ,使 RELRO 状态变为 NO RELRO 。-Wl,-z,lazy会开启延迟绑定,使 RELRO 状态变为 Partial RELRO 。
读入函数
| 函数 | 是否读空格 | 截断条件(停止条件) | 自动加 '\0' |
长度控制 | 备注 / 安全提示 |
|---|---|---|---|---|---|
gets(buf) |
✅ 能 | 遇到首个 \n(丢弃该换行)或 EOF |
✅ 是(成功时) | ❌ 无 | 已被 C11 移除,严禁使用;无法限制长度,极不安全。 |
fgets(buf, n, stdin) |
✅ 能 | 读到 \n(保留在缓冲区)、或读满 n-1、或 EOF/错误 |
✅ 是*(若至少读到 1 字节;否则返回 NULL) |
✅ 由 n 限制 |
常见坑:换行会保留;若一开始就 EOF/错误,缓冲区不改动、返回 NULL。 |
scanf("%s", buf) |
❌ 不能(以任一空白为分隔) | 遇到空白字符(空格/\t/\n 等;会跳过前导空白) |
✅ 是*(成功匹配时) | ❌ 默认无;应写宽度如 %Ns |
对 %s 和 %[ 必须写入字段宽度,否则同样不安全;s 会写终止符。 |
scanf("%[^\n]", buf) |
✅ 能 | 遇到 \n(不消费该换行,仍留在输入流中)或达字段宽度 |
✅ 是*(成功匹配时) | ❌ 默认无;应写 %N[^\n] |
扫描集会把空格读入结果;由于不消费换行,后续读取前最好先丢弃该换行。 |
read(fd, buf, size) |
✅ 能 | 读满 size 或 EOF(返回已读字节数) |
❌ 否 | ✅ 由 size 精确控制 |
原始字节读取(系统调用),不会追加终止符;若要当 C 字符串用,需手动补 '\0'。 |
getline(&buf, &len, stdin) |
✅ 能 | 读到 \n(保留在缓冲区)或 EOF/错误 |
✅ 是(成功时) | ✅ 自动扩容(必要时 realloc) |
POSIX 接口(ISO C 未定义);返回字节数(包含换行,不包含终止 '\0')。 |
在 C 语言
Clocale 下,isspace()判定为空白的仅以下 6 个字符(也是scanf/printf相关规则里的空白集合):
- 空格:
' '- 水平制表:
'\t'(HT)- 换行:
'\n'(LF)- 垂直制表:
'\v'(VT)- 换页:
'\f'(FF)- 回车:
'\r'(CR)
调用约定
栈结构
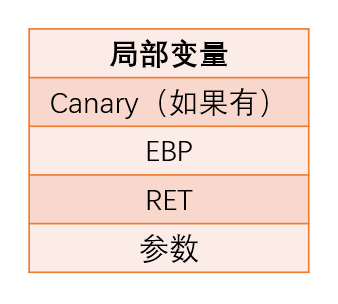
注意
canary 不一定与 ebp 相邻,因为有些函数会先将一些寄存器保存到栈中。canary 实际位置以调试为准。
函数调用过程
32位为例:
函数参数传递
注意:通常 linux 下的程序的函数调用都是外平栈的。
32 位程序
普通函数
Linux 使用 cdecl 调用约定,所有参数 从右到左 压入栈中。由 调用者(caller) 负责清理栈上的参数。使用 EAX 返回函数值。
系统调用
在 32 位 Linux(x86 架构)中,用户态通过 int 0x80 进入内核执行系统调用。为了提高兼容性,Linux 系统主要采用 int 0x80,而不是 sysenter,因为后者需要硬件支持和额外的返回跳板机制。
系统调用时,调用号和参数都通过寄存器传递,具体分配如下:
EAX寄存器用于存放系统调用号(syscall number)。EBX、ECX、EDX、ESI、EDI、EBP依次用于传递系统调用的第 1 到第 6 个参数。
系统调用返回时,结果会存放在 EAX 中。如果调用成功,EAX 中为返回值;如果失败,则 EAX 为负值(对应负的 errno 编号)。
64位程序
普通函数
在 64 位 Linux(x86_64 架构)中,普通函数调用遵循 System V AMD64 ABI 调用约定,这是当前 Linux 平台上 C/C++ 等语言的标准调用方式。
函数参数通过寄存器优先传递,具体为:
RDI、RSI、RDX、RCX、R8、R9依次用于传递前 6 个参数。- 超过 6 个参数的部分,从右到左压入栈中。
函数返回值通过 RAX 返回,若返回值过大或为结构体,可能使用多个寄存器(必要时用 RDX:RAX 返回 128bit)或通过内存返回。
在寄存器使用上,调用者负责保存 RAX、RCX、RDX、RDI、RSI、R8~R11 等 caller-saved 寄存器;而 RBX、RBP、R12~R15 等 callee-saved 寄存器由被调用函数保存。
函数调用前,要求栈地址必须对齐到 16 字节,否则在使用某些 SSE 指令时会触发崩溃。
系统调用
在 64 位 Linux(x86_64 架构)中,用户态通过 syscall 指令进入内核执行系统调用。相比 32 位的 int 0x80,syscall 是专为 64 位架构设计的系统调用指令,执行效率更高,也是当前主流的调用方式。
系统调用时,调用号和参数都通过寄存器传递,具体分配如下:
RAX寄存器用于存放系统调用号(syscall number)。RDI、RSI、RDX、R10、R8、R9依次用于传递系统调用的第 1 到第 6 个参数。
注意
第 4 个参数使用 R10 而不是 RCX,因为 RCX 在执行 syscall 时会被硬件破坏(用作返回地址保存)。
系统调用返回时,结果会存放在 RAX 中。如果调用成功,RAX 中为返回值;如果失败,则 RAX 为负值(对应负的 errno 编号)。
系统调用号
32 位
1 |
64 位
1 |
- Title: linux user pwn 基础知识
- Author: sky123
- Created at : 2024-11-07 18:56:56
- Updated at : 2025-11-18 00:10:50
- Link: https://skyi23.github.io/2024/11/07/linux-user-pwn-basic-knowlege/
- License: This work is licensed under CC BY-NC-SA 4.0.